In questo articolo, discutiamo la prima fase nella progettazione del compilatore in cui il programma di input di alto livello viene convertito in una sequenza di token. Questa fase è nota come Analisi lessicale nella progettazione del compilatore.
Indice:
- Definizioni per l’Analisi Lessicale
- Un esempio di Analisi Lessicale
- Architettura dell’analizzatore lessicale
- Espressioni Regolari
- Finiti Automi
- la Relazione tra le espressioni regolari e automi finiti
- più Lunga Corrispondenza con la Regola
- Lessicale errori
- Errore di recupero di schemi
- Necessità di analizzatori lessicali
- Necessità di analizzatori lessicali
analisi Lessicale è il processo di conversione di una sequenza di caratteri da un programma di origine che viene preso come input una sequenza di token.
Un lex è un programma che genera analizzatori lessicali.
Un analizzatore lessicale / lexer / scanner è un programma che esegue l’analisi lessicale.
I ruoli di lexical analyzer comportano;
- Lettura dei caratteri di input dal programma sorgente.
- Correlazione dei messaggi di errore con il programma sorgente.
- Striatura di spazi bianchi e commenti dal programma sorgente.
- Macro di espansione se trovate nel programma sorgente.
- Inserimento di token identificati nella tabella dei simboli.
Lexeme è un’istanza di un token, cioè una sequenza di caratteri inclusi nel programma sorgente in base al modello corrispondente di un token.
Un esempio, data l’espressione;
c = a + b * 5
I lessemi e i token sono;
| i Lessemi | Token |
|---|---|
| c | identificatore |
| = | simbolo di assegnazione |
| un | identificatore |
| + | +(oltre che simbolo) |
| b | identificatore |
| * | *(simbolo di moltiplicazione) |
| 5 | 5(numero) |
La sequenza di token prodotta dall’analizzatore lessicale permette il parser per analizzare la sintassi di un linguaggio di programmazione.
Un token è una sequenza valida di caratteri data da un lessema, viene trattata come un’unità nella grammatica del linguaggio di programmazione.
In un linguaggio di programmazione questo può includere;
- parole chiave
- Operatori
- i simboli di Punteggiatura
- Costanti
- Identificatori
- Numeri
Un modello è una regola di corrispondenza da una sequenza di caratteri(lessemi) utilizzato per il token. Può essere definito da espressioni regolari o regole grammaticali.
Un esempio di Analisi Lessicale
Codice
#include<iostream>// exampleint main(){ int a, b; a = 7; return 0;}Token
| i Lessemi | Token |
|---|---|
| int | parola chiave |
| principale | parola chiave |
| ( | operatore |
| ) | operatore |
| { | operatore |
| int | parola chiave |
| un | identificatore |
| , | operatore |
| b | identificatore |
| ; | operatore |
| un | identificatore |
| = | simbolo di assegnazione |
| 10 | 10(numero) |
| ; | operatore |
| di ritorno | parola chiave |
| 0 | 0(numero) |
| ; | operatore |
| } | operatore |
Non Gettoni
| Tipo | Token |
|---|---|
| la direttiva del preprocessore | #include<iostream> |
| commento | // esempio |
Il processo di analisi lessicale costituisce di due fasi.
- Scansione-Ciò comporta la lettura dei caratteri di input e la rimozione di spazi bianchi e commenti.
- Tokenizzazione-Questa è la produzione di token come output.
Architettura dell’analizzatore lessicale
Il compito principale dell’analizzatore lessicale è quello di scansionare l’intero programma sorgente e identificare i token uno per uno.
Gli scanner sono implementati per produrre token quando richiesto dal parser.

Passi:
- “get next token” viene inviato dal parser all’analizzatore lessicale.
- L’analizzatore lessicale esegue la scansione dell’input fino a quando non si trova il “token successivo”.
- Il token viene restituito al parser.
Espressioni regolari
Usiamo espressioni regolari per esprimere linguaggi finiti definendo modelli per un insieme finito di simboli.
La grammatica definita dalle espressioni regolari è nota come grammatica regolare e la lingua definita dalla grammatica regolare è nota come lingua regolare.
Esistono regole algebriche obbedite dalle espressioni regolari utilizzate per manipolare le espressioni regolari in forme equivalenti.
Operazioni.
Unione di due lingue A e B è scritto come
A U B = {s | s è in a o i B}
Concatenazione di due lingue A e B è scritto come
AB = {ss | s in e s a B}
Il kleen chiusura di un linguaggio che è scritto come
A* = (zero o più occorrenze di lingua A.
Notazioni.
Se x e y sono espressioni regolari che denotano i linguaggi A(x) e B(y) allora;
(x) è un’espressione regolare che denota A(x).
Union (x)|(y) è un’espressione regolare che denota A(x) B(y).
Concatenazione (x) (y)è un’espressione regolare ammaccatura A(x) B (y).
Kleen closure (x) * è un’espressione regolare che denota (A (x))*
Precedenza e associatività.
* ” concatenazione .’e / (pipe) sono lasciati associativi.
Kleen closure * ha la precedenza più alta.
Concatenazione (.) segue in precedenza.
(pipe) | ha la precedenza più bassa.
Che rappresenta token validi di una lingua nelle espressioni regolari.
X è un’espressione regolare, quindi;
- x * rappresenta zero o più occorrenze di x.
- x+ rappresenta una o più occorrenze di x, cioè{x, xx, xxx}
- x? rappresenta al massimo un’occorrenza di x cioè {x}
- rappresentano tutti gli alfabeti minuscoli nella lingua inglese.
- rappresentano tutti gli alfabeti maiuscoli in lingua inglese.
- rappresentano tutti i numeri naturali.
Che rappresenta l’occorrenza di simboli usando espressioni regolari
Letter = or
Digit = or|0|1|2|3|4|5|6|7|8|9
Sign =
Che rappresenta i token di lingua usando espressioni regolari.
Decimale = (segno)?(digit)+
Identifier = (letter) (letter | digit)*
Automi finiti
Questa è la combinazione di cinque tuple (Q, Σ, q0, qf, δ) che si concentrano su stati e transizioni attraverso i simboli di input.
Riconosce i pattern prendendo la stringa di symbol come input e cambia il suo stato di conseguenza.
Il modello matematico per automi finiti è costituito da;
- insieme Finito di stati(Q)
- insieme Finito di simboli in ingresso(Σ)
- Uno stato iniziale(q0)
- Set di stati finali(qf)
- funzione di Transizione δ)
Finite automata è utilizzato in analisi lessicale per produrre i token in forma di identificatori, parole chiave e costanti, dall’ingresso del programma.
Gli automi finiti alimentano la stringa di espressioni regolari e lo stato viene modificato per ogni letterale.
Se l’input viene elaborato correttamente, l’automata raggiunge lo stato finale e viene accettato altrimenti viene rifiutato.
Costruzione di automi finiti
Sia L(r) un linguaggio regolare da parte di alcuni automi finiti F(A).
Pertanto;
- Stati: Cerchi rappresenteranno gli stati di FA ed i loro nomi sono scritti all’interno dei cerchi.
- Stato di avvio: questo è lo stato in cui vengono avviati gli automi. Avrà una freccia che punta verso di essa.
- Stati intermedi: questi hanno due frecce, una che punta ad esso e un’altra che indica dagli stati intermedi.
- Stato finale: Gli automi dovrebbero essere nello stato finale quando la stringa di input è stata analizzata correttamente e rappresentata da doppi cerchi altrimenti l’input viene rifiutato. Può contenere un numero dispari di frecce che puntano verso di esso e un numero pari che indica da esso, cioè
frecce dispari = frecce pari + 1. - Transizione: quando viene trovato un simbolo desiderato nell’input, si verificherà la transizione da uno stato a un altro stato. Gli automi passano allo stato successivo o persistono.
Una freccia diretta mostrerà il movimento da uno stato all’altro mentre una freccia punta verso lo stato di destinazione.
Se gli automi rimangono sullo stesso stato, viene disegnata una freccia che punta da uno stato a se stesso.
Un esempio; Supponiamo che un valore binario a 3 cifre che termina con 1 sia accettato da FA.
Quindi FA = {Q(q0, qf), Σ (0,1), q0, qf, δ}
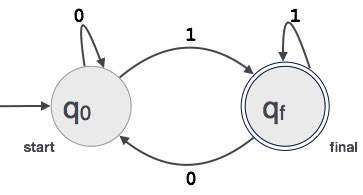
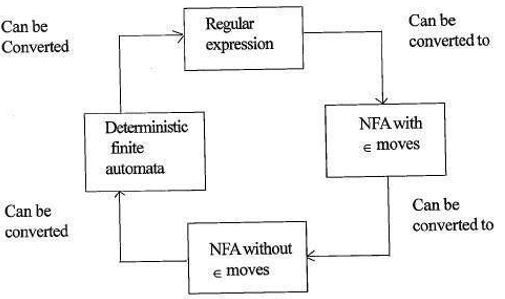
Relazione tra espressioni regolari e automi finiti
La relazione tra espressione regolare e automi finiti è la seguente;
La figura seguente mostra che è facile da convertire;
- Espressioni regolari agli automi finiti non deterministici(NFA) con moves moves.
- Automi finiti non deterministici con moves moves a senza moves moves
- Automi finiti non deterministici senza Autom moves a Automi Finiti deterministici(DFA).
- Automi finiti deterministici all’espressione regolare.
Un Lex accetta espressioni regolari come input e restituisce un programma che simula un automa finito per riconoscere le espressioni regolari.
Pertanto, lex combinerà la generazione di pattern string (espressioni regolari che definiscono le stringhe di interesse per lex) e il riconoscimento di pattern string (un automa finito che riconosce le stringhe di interesse).
Regola di corrispondenza più lunga
Afferma che il lessema scansionato deve essere determinato in base alla corrispondenza più lunga tra tutti i token disponibili.
Viene utilizzato per risolvere le ambiguità al momento di decidere il token successivo nel flusso di input.
Durante l’analisi del codice sorgente, l’analizzatore lessicale esegue la scansione del codice lettera per lettera e quando viene rilevato un operatore, un simbolo speciale o uno spazio bianco decide se una parola è completa.
Esempio:
int intvalue;Durante la scansione di quanto sopra, l’analizzatore non può determinare se ‘int’ è una parola chiave int o il prefisso dell’identificatore intvalue.
Viene applicata la priorità della regola per cui una parola chiave verrà data priorità all’input dell’utente, il che significa che nell’esempio precedente l’analizzatore genererà un errore.
Errori lessicali
Si verifica un errore lessicale quando una sequenza di caratteri non può essere scansionata in un token valido.
Questi errori possono essere causati da un errore di ortografia di identificatori, parole chiave o operatori.
Generalmente, sebbene gli errori lessicali molto rari siano causati da caratteri illegali in un token.
Gli errori possono essere;
- Errore di ortografia.
- Trasposizione di due caratteri.
- Caratteri illegali.
- Lunghezza superiore dell’identificatore o delle costanti numeriche.
- Sostituzione di un carattere con un carattere errato
- Rimozione di un carattere che dovrebbe essere presente.
Il recupero degli errori comporta;
- Rimozione di un carattere dall’input rimanente
- Trasposizione di due caratteri adiacenti
- Eliminazione di un carattere dall’input rimanente
- Inserimento del carattere mancante nell’input rimanente
- Sostituzione di un carattere con un altro carattere.
- Ignorando i caratteri successivi fino a formare un token legale (recupero in modalità panico).
Schemi di recupero degli errori
Recupero in modalità panico.
In questo schema di ripristino degli errori i pattern non corrispondenti vengono eliminati dall’input rimanente fino a quando l’analizzatore lessicale non trova un token ben formato all’inizio dell’input rimanente.
L’implementazione più semplice è un vantaggio per questo approccio.
Ha la limitazione che una grande quantità di input viene saltata senza controllare eventuali errori aggiuntivi.
Correzione locale.
Quando viene rilevato un errore in un punto, le operazioni di inserimento/eliminazione e/o sostituzione vengono eseguite fino a ottenere un testo ben formato.
L’analizzatore viene riavviato con il nuovo testo risultante come input.
Correzione globale.
Si tratta di una modalità di recupero panico migliorata preferito quando la correzione locale non riesce.
Ha requisiti di tempo e spazio elevati, quindi non è implementato praticamente.
Necessità di analizzatori lessicali
- Miglioramento dell’efficienza del compilatore – tecniche di buffering specializzate per la lettura dei caratteri accelerano il processo del compilatore.
- Semplicità di progettazione del compilatore-La rimozione di spazi bianchi e commenti consentirà costrutti sintattici efficienti per l’analizzatore di sintassi.
- Portabilità del compilatore – solo lo scanner comunica con il mondo esterno.
- Specializzazione – tecniche specializzate possono essere utilizzate per migliorare il processo di analisi lessicale
Problemi con l’analisi lessicale
- Lookahead
Data una stringa di input, i caratteri vengono letti da sinistra a destra uno per uno.
Per determinare se un token è finito o meno dobbiamo guardare il carattere successivo.
Esempio: È ‘ = ‘un operatore di assegnazione o il primo carattere dell’operatore’==’.
Lookahead salta i caratteri nell’input fino a quando non viene trovato un token ben formato, questo dimostra che look ahead non può rilevare errori significativi tranne che per errori semplici come simboli illegali. - Ambiguità
I programmi scritti con lex accettano specifiche ambigue e quindi scelgono la corrispondenza più lunga e quando più espressioni corrispondono all’input o si preferisce la corrispondenza più lunga o la prima regola tra le regole corrispondenti è prioritaria. - parole chiave Riservate
Alcune lingue hanno parole riservate, che non siano riservate in altri linguaggi di programmazione, ad esempio, elif è una parola riservata in python, ma non in C. - Contesto di Dipendenza
Esempio:
Dato il comando DO 10 l = 10.86, DO10l è un identificatore e non è una parola chiave.
E data la dichiarazione DO 10 l = 10, 86, DO è una parola chiave
Tali affermazioni richiederebbero un sostanziale sguardo in avanti per la risoluzione.
Le applicazioni
- Utilizzate dai compilatori creano eseguibili binari conformi dal codice analizzato.
- Utilizzato dai browser web per formattare e visualizzare una pagina web che viene analizzato HTML, CSS e java script.
Con questo articolo su OpenGenus, devi avere una forte idea dell’analisi lessicale nella progettazione del compilatore.