Con reti complesse costituite da cloud, IT ibrido, virtualizzazione, storage area network e così via, i problemi IT sfaccettati possono essere difficili da individuare e diagnosticare. Quando si verifica un problema, ad esempio un’applicazione o un server con prestazioni non ottimali, l’indagine può richiedere molto tempo per individuare il problema principale. Il problema potrebbe essere nello storage, nella connettività di rete, nell’accesso degli utenti o in un mix di risorse e configurazioni.
Per esaminare il problema, creare progetti di risoluzione dei problemi con la dashboard Performance Analysis (PerfStack™) che correlano visivamente i dati storici di più prodotti SolarWinds e tipi di entità in un’unica vista.
Con i dashboard di analisi delle prestazioni, è possibile effettuare le seguenti operazioni:
- Confronta e analizza più tipi di metriche in un’unica vista, inclusi stato, eventi e statistiche.
- Confronta e analizza le metriche per più entità in un’unica vista, inclusi nodi, interfacce, volumi, applicazioni e altro ancora.
- Correlare i dati da tutta la piattaforma Orion su una singola linea temporale condivisa.
- Visualizza i dati ibridi per locali, cloud e tutto il resto.
- Condividi un progetto di risoluzione dei problemi con i tuoi team ed esperti per esaminare i dati storici per un problema.
Per VMAN, le possibilità sono infinite per l’analisi delle applicazioni e gli ambienti ibridi:
- Visivamente piedi attraverso i dati storici per macchine virtuali in ambiente
- Verificare problemi di allocazione di risorse in ambienti ibridi
- Correlare i dati per risolvere i problemi di traffico di rete inviati e ricevuti dal server virtuali (host, cluster, archivi di dati, e VMs), server on-premise, cloud e le istanze
L’esempio seguente mostra come identificare una causa principale di un VM verificano problemi di prestazioni. In questo scenario, un host virtuale ha riscontrato un problema di risorse e prestazioni al punto in cui gli utenti incontrano risposte e accessi più lenti. Il problema ha attivato un avviso, che ha notificato il proprietario dell’applicazione, che ha inoltrato il problema agli amministratori di sistema e di rete.
Creare un nuovo progetto di risoluzione dei problemi per esaminare il problema e confrontare le metriche per l’host e tutti i relativi sistemi di ambiente virtuale per tenere traccia delle tendenze e dei picchi di utilizzo.
-
Nella console Web di Orion, selezionare Dashboard personali > Home > Analisi delle prestazioni.
Si apre la dashboard Performance Analysis, o PerfStack, per creare grafici e grafici utilizzando metriche estratte da applicazioni e server monitorati nella tavolozza Metriche. Ogni grafico può contenere più metriche per correlare direttamente i dati.
-
Nel Nuovo progetto di analisi, fare clic su Aggiungi entità.
Per iniziare, è necessario individuare e aggiungere la VM in difficoltà. Nel campo di ricerca, immettere syd per visualizzare un elenco di server virtuali che condividono tale nome. Espandere e selezionare Tipi o Stato per filtrare l’elenco, se necessario.
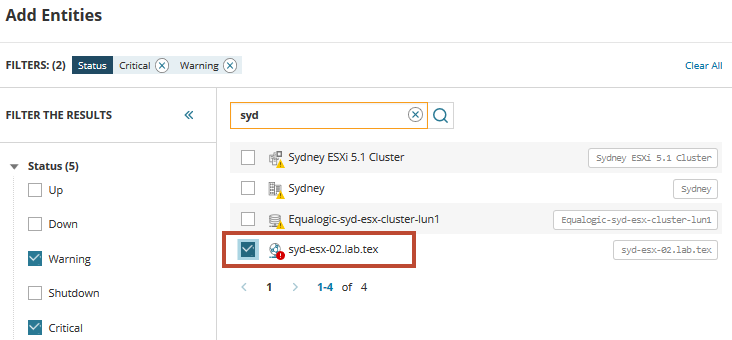
Dall’elenco, troviamo l’host virtuale che incontra i problemi e attiva gli avvisi. Selezionare l’host e aggiungerlo alla tavolozza Metrica dashboard. Fare clic sull’icona Entità correlate per visualizzare tutti i server e i servizi correlati all’host.
Sei interessato a tutti i nodi, le applicazioni, i server associati e altro a questo nodo selezionato? Fare clic sull’icona entità correlate.
 Tutte le entità correlate vengono visualizzate nella tavolozza Metrica fornendo più opzioni per le metriche che potrebbero causare problemi.
Tutte le entità correlate vengono visualizzate nella tavolozza Metrica fornendo più opzioni per le metriche che potrebbero causare problemi.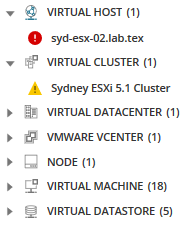
-
Selezionare il nodo host syd da visualizzare e selezionare le metriche da trascinare e rilasciare sul dashboard. È possibile trascinarli nello stesso grafico per confrontare i valori tra le metriche.
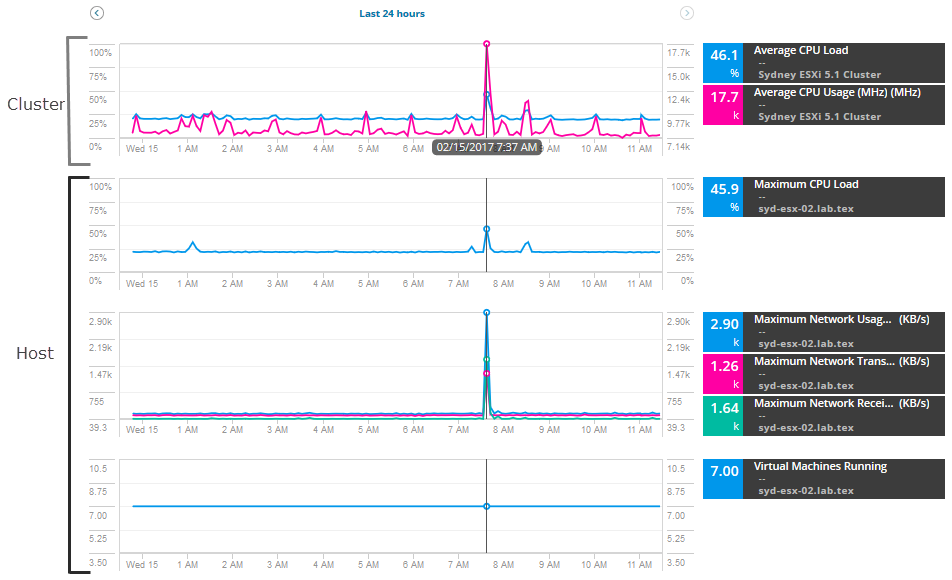
Per iniziare a indagare, estrai una serie di metriche per l’host e il cluster, confrontando le metriche per trovare picchi o un utilizzo elevato. Per questo scenario, aggiungere queste metriche host:
- Massimo Utilizzo della Rete
- di Rete Massima velocità di Trasmissione
- di Rete Massima velocità di Ricezione
- Macchine Virtuali in Esecuzione
Per il cluster, è possibile aggiungere queste metriche:
- Il Carico medio della CPU
- Utilizzo Medio della CPU
grafici, tabelle e grafici di visualizzazione dei dati e degli avvisi per il Ultimi 12 ore di metriche. È possibile espandere la data e l’ora per visualizzare ulteriori metriche storiche nel corso dell’avviso.
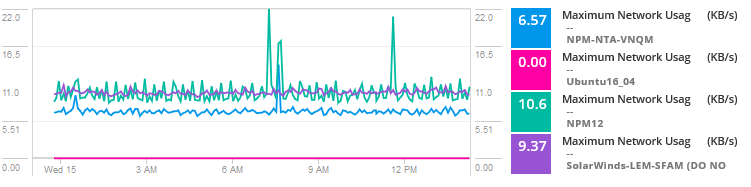
Aggiungi metriche di utilizzo per le macchine virtuali sull’host per confrontare l’utilizzo e l’attività della rete.
-
Analizzando i dati, il problema sembra essere un vicino rumoroso per una delle macchine virtuali che consuma risorse e presenta un traffico elevato che causa colli di bottiglia e problemi per le VM che condividono l’host. Fondamentalmente, un altro server, servizio o applicazione sta consumando maggiore larghezza di banda, I/O del disco, CPU e altre risorse che causano problemi per questa specifica applicazione.
Queste informazioni forniscono agli amministratori di rete e di sistema una direzione per ulteriori indagini e risolvere i problemi di latenza. Per risolvere, possono riallocare le risorse o spostare l’applicazione ad alto consumo in un’altra posizione.
-
Fare clic su Salva e assegnare un nome al progetto.
Il progetto viene salvato come dashboard con le metriche selezionate nell’intervallo di data e ora impostato.
Quando salvato, l’URL diventa un collegamento condivisibile. Copia e condividi il link al dashboard salvato nei ticket o nelle e-mail inviate dagli amministratori di sistema e di rete e dal proprietario del prodotto. Possono accedere al link per esaminare i dati raccolti e risolvere i problemi.
Dopo aver riallocato le risorse e apportato modifiche alla rete, riaprire il dashboard per verificare le modifiche e le nuove tendenze di utilizzo per le metriche interrogate.