Cerchiamo di essere dolorosamente onesti, quando il vostro business non è rappresentato su Internet, è inesistente al mondo. Inoltre, se non si dispone di un sito web, si sta perdendo un’ampia opportunità per attirare più lead di qualità. Qualsiasi azienda, da un gigante aziendale come Amazon a un’azienda di una sola persona, si sforza di avere un sito Web e contenuti che attraggano il proprio pubblico. Scoprire te e la tua azienda online non si ferma qui. Dietro i siti web, c’è un intero mondo “invisibile all’occhio umano” in cui i web crawler svolgono un ruolo importante.
Contents
- Che cos’è un crawler Web e l’indicizzazione?
- Come funziona una ricerca Web?
- Come funziona un crawler Web?
- Quali sono i principali tipi di Web Crawler?
- Quali sono esempi di Web Crawler?
- Che cos’è un Googlebot?
- Web Crawler vs Web Scraper-Qual è la differenza?
- Crawler Web personalizzato-Che cos’è?
- Avvolgimento
Che cos’è un crawler Web e l’indicizzazione?
cominciamo con un web crawler definizione:
Un web crawler (noto anche come web spider, spider bot, bot web, o semplicemente un crawler) è un programma software per computer che viene utilizzato da un motore di ricerca per indicizzare le pagine web e contenuti attraverso il World Wide Web.
L’indicizzazione è piuttosto un processo essenziale in quanto aiuta gli utenti a trovare query pertinenti in pochi secondi. L’indicizzazione della ricerca può essere paragonata all’indicizzazione del libro. Ad esempio, se apri le ultime pagine di un libro di testo, troverai un indice con un elenco di query in ordine alfabetico e le pagine in cui sono menzionate nel libro di testo. Lo stesso principio sottolinea l’indice di ricerca, ma invece di numerazione delle pagine, un motore di ricerca vi mostra alcuni link dove è possibile cercare le risposte alla vostra richiesta.
La differenza significativa tra gli indici di ricerca e di libro è che il primo è dinamico, quindi può essere modificato e il secondo è sempre statico.
Come funziona una ricerca Web?
Prima di immergerti nei dettagli di come funziona un robot cingolato, vediamo come viene eseguito l’intero processo di ricerca prima di ottenere una risposta alla tua query di ricerca.
Ad esempio, se digiti “Qual è la distanza tra Terra e Luna” e premi Invio, un motore di ricerca ti mostrerà un elenco di pagine pertinenti. Di solito, ci vogliono tre passaggi principali per fornire agli utenti le informazioni richieste per le loro ricerche:
- Un web spider indicizzazione dei contenuti sui siti web
- Si costruisce un indice di un motore di ricerca
- gli algoritmi di Ricerca di classificare le pagine più pertinenti
Inoltre, bisogna tenere a mente due punti essenziali:
- Non fare le ricerche in tempo reale, è impossibile
Ci sono un sacco di siti web sul World Wide Web, e molti altri sono stati creati anche ora, quando si sta leggendo questo articolo. Ecco perché potrebbe richiedere eoni per un motore di ricerca a venire con un elenco di pagine che sarebbero rilevanti per la query. Per accelerare il processo di ricerca, un motore di ricerca esegue la scansione delle pagine prima di mostrarle al mondo.
- Non fai ricerche nel World Wide Web
In effetti, non esegui ricerche nel World Wide Web ma in un indice di ricerca e questo è quando un web crawler entra nel campo di battaglia.
Contattaci ora!
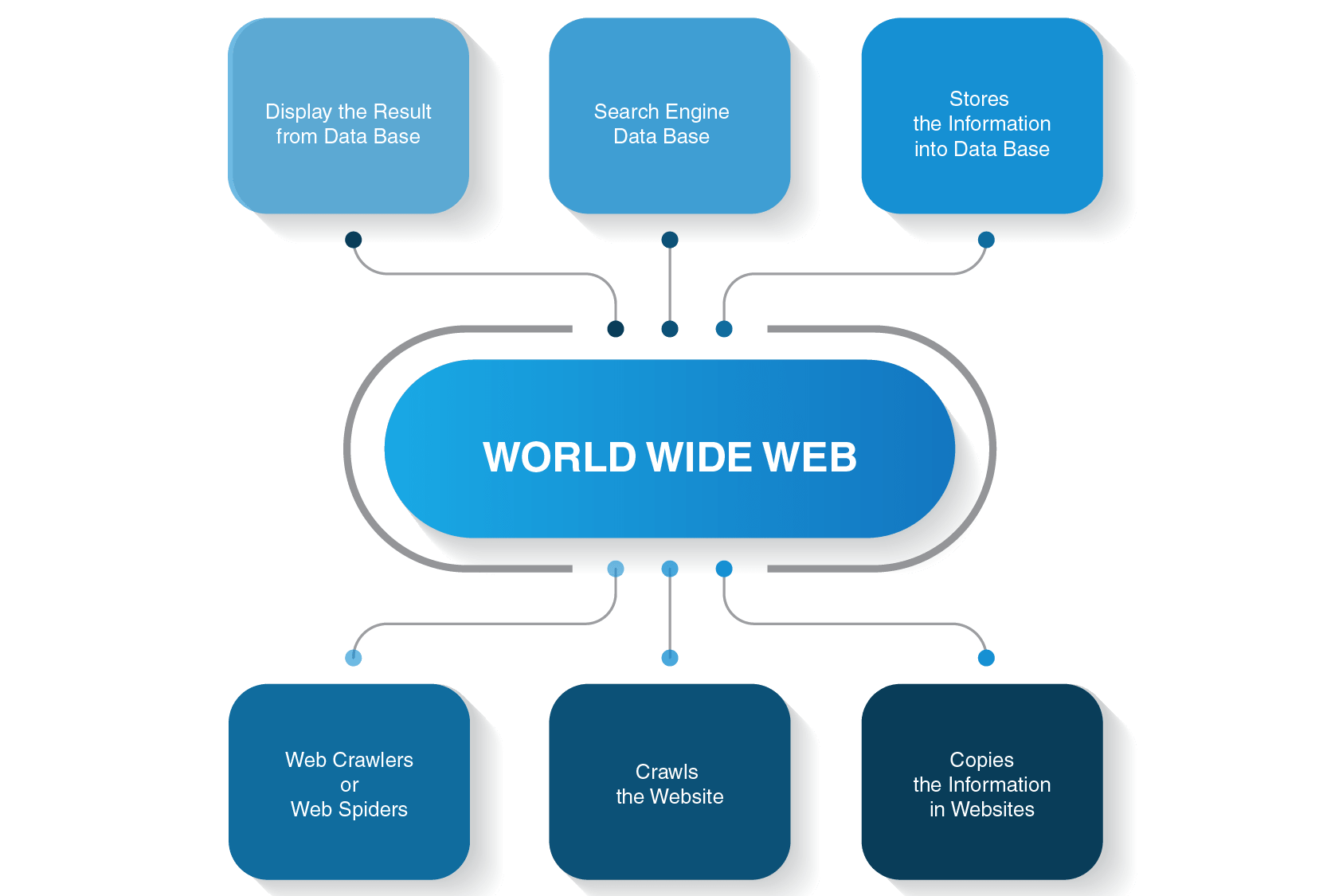
Come funziona un Web Crawler?
Ci sono molti motori di ricerca là fuori-Google, Bing, Yahoo!, DuckDuckGo, Baidu, Yandex, e molti altri. Ognuno di loro usa il suo spider bot per indicizzare le pagine.
Iniziano il loro processo di scansione dai siti web più popolari. Il loro scopo principale di bot web è quello di trasmettere l’essenza di ciò che ogni contenuto della pagina è tutto. Così, ragni web cercano parole su queste pagine e poi costruire un elenco pratico di queste parole che verranno utilizzati da un motore di ricerca la prossima volta quando si desidera trovare informazioni sulla query.
Tutte le pagine su Internet sono collegate da collegamenti ipertestuali, quindi gli spider del sito possono scoprire quei collegamenti e seguirli alle pagine successive. I bot Web si fermano solo quando individuano tutti i contenuti e i siti Web collegati. Quindi inviano le informazioni registrate un indice di ricerca, che viene memorizzato su server in tutto il mondo. L’intero processo assomiglia a una ragnatela reale in cui tutto è intrecciato.
La scansione non si arresta immediatamente dopo l’indicizzazione delle pagine. I motori di ricerca utilizzano periodicamente web spider per vedere se sono state apportate modifiche alle pagine. Se c’è una modifica, l’indice di un motore di ricerca verrà aggiornato di conseguenza.
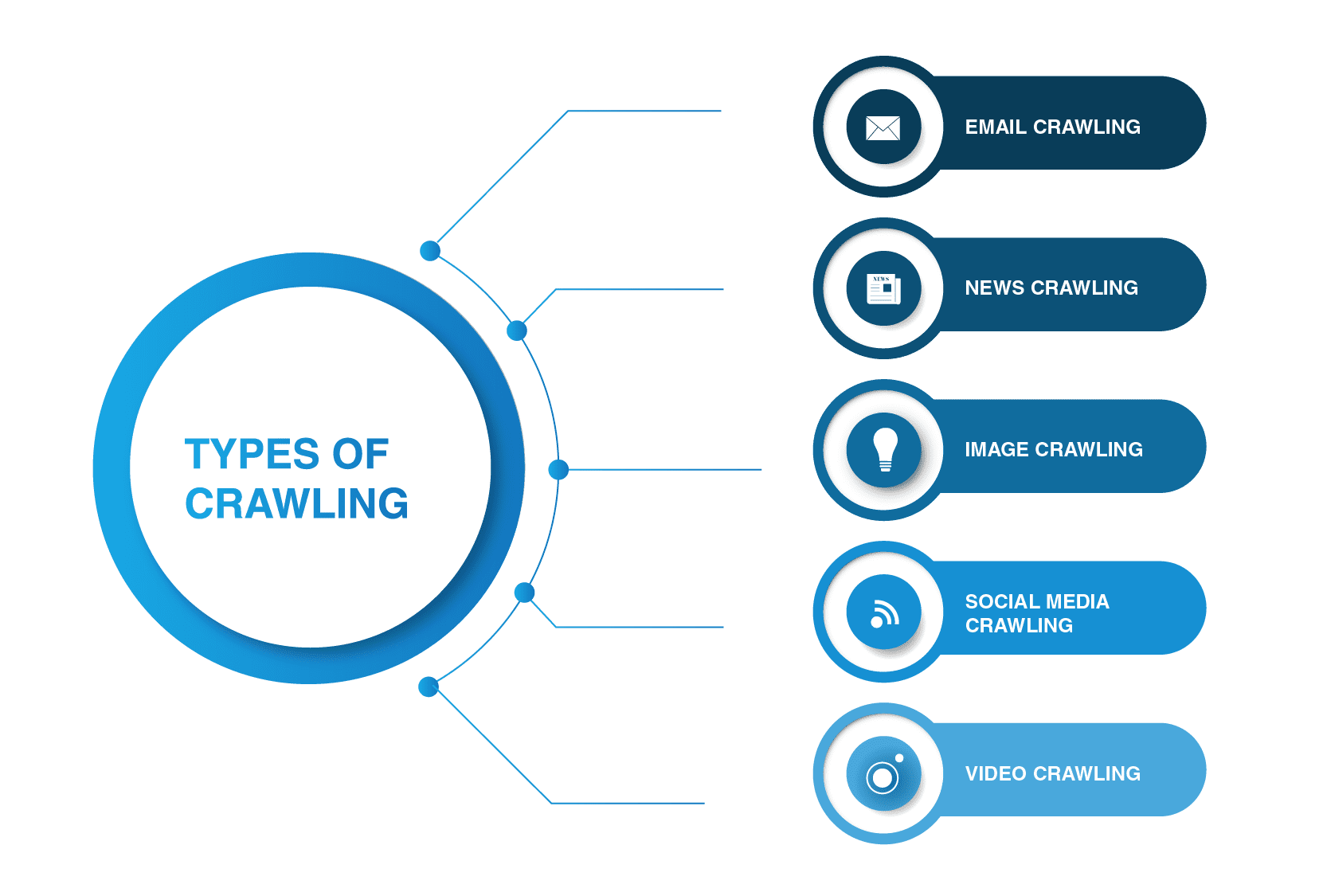
Quali sono i principali tipi di Web Crawler?
I web crawler non sono limitati agli spider dei motori di ricerca. Ci sono altri tipi di web che strisciano là fuori.
- Email crawling
Email crawling è particolarmente utile nella generazione di lead in uscita in quanto questo tipo di scansione aiuta a estrarre gli indirizzi email. Vale la pena ricordare che questo tipo di scansione è illegale in quanto viola la privacy personale e non può essere utilizzato senza il permesso dell’utente.
- News crawling
Con l’avvento di Internet, notizie provenienti da tutto il mondo possono essere diffuse rapidamente in tutto il Web, e per estrarre i dati da vari siti web può essere abbastanza ingestibile.
Ci sono molti web crawler che possono far fronte a questa attività. Tali crawler sono in grado di recuperare i dati dal nuovo, vecchio, e contenuti di notizie archiviati e leggere i feed RSS. Estraggono le seguenti informazioni: data di pubblicazione, nome dell’autore, titoli, paragrafi principali, testo principale e lingua di pubblicazione.
- Scansione di immagini
Come suggerisce il nome, questo tipo di scansione viene applicato alle immagini. Internet è pieno di rappresentazioni visive. Pertanto, tali bot aiutano le persone a trovare immagini pertinenti in una pletora di immagini sul Web.
- Social media crawling
Social media crawling è piuttosto una questione interessante come non tutte le piattaforme di social media permettono di essere strisciato. Si dovrebbe anche tenere a mente che tale tipo di scansione può essere illegale se viola la conformità privacy dei dati. Tuttavia, ci sono molti fornitori di piattaforme di social media che vanno bene con la scansione. Ad esempio, Pinterest e Twitter consentono ai bot spider di scansionare le loro pagine se non sono sensibili all’utente e non rivelano alcuna informazione personale. Facebook, LinkedIn sono rigorosi per quanto riguarda questa materia.
- Video crawling
A volte è molto più facile guardare un video che leggere molti contenuti. Se decidi di incorporare Youtube, Soundcloud, Vimeo o qualsiasi altro contenuto video nel tuo sito Web, può essere indicizzato da alcuni crawler web.
Quali sono esempi di Web Crawler?
Molti motori di ricerca utilizzano i propri bot di ricerca. Ad esempio, gli esempi di web crawler più comuni sono:
- Alexabot
Amazon web crawler Alexabot viene utilizzato per l’identificazione di contenuti web e backlink discovery. Se vuoi mantenere alcune delle tue informazioni private, puoi escludere Alexabot dalla scansione del tuo sito web.
- Yahoo! Il sito utilizza cookie tecnici e di terze parti. Slurp Bot viene utilizzato per l’indicizzazione e la raschiatura di pagine web per migliorare i contenuti personalizzati per gli utenti.
- Bingbot
Bingbot è uno dei ragni web più popolari alimentati da Microsoft. Aiuta un motore di ricerca, Bing, per creare l’indice più rilevante per i suoi utenti.
- DuckDuck Bot
DuckDuckGo è probabilmente uno dei motori di ricerca più popolari che non traccia la tua cronologia e ti segue su qualsiasi sito tu stia visitando. Il suo crawler web DuckDuck Bot aiuta a trovare i risultati più rilevanti e migliori in grado di soddisfare le esigenze di un utente.
- Facebook Hit esterno
Facebook ha anche il suo crawler. Ad esempio, quando un utente di Facebook desidera condividere un link a una pagina di contenuto esterno con un’altra persona, il crawler raschia il codice HTML della pagina e fornisce a entrambi il titolo, un tag del video o immagini del contenuto.
- Baiduspider
Questo crawler è gestito dal motore di ricerca cinese dominante − Baidu. Come qualsiasi altro bot, viaggia attraverso una varietà di pagine web e cerca collegamenti ipertestuali per indicizzare il contenuto per il motore.
- Exabot
Motore di ricerca francese Exalead utilizza Exabot per l’indicizzazione dei contenuti in modo che possano essere inclusi nell’indice del motore.
- Yandex Bot
Questo bot appartiene al più grande motore di ricerca russo Yandex. Puoi bloccarlo dall’indicizzazione dei tuoi contenuti se non hai intenzione di condurre affari lì.
Che cos’è un Googlebot?
Come affermato sopra, quasi tutti i motori di ricerca hanno i loro spider bot e Google non fa eccezione. Googlebot è un crawler di Google alimentato dal motore di ricerca più popolare al mondo, che viene utilizzato per l’indicizzazione dei contenuti per questo motore.
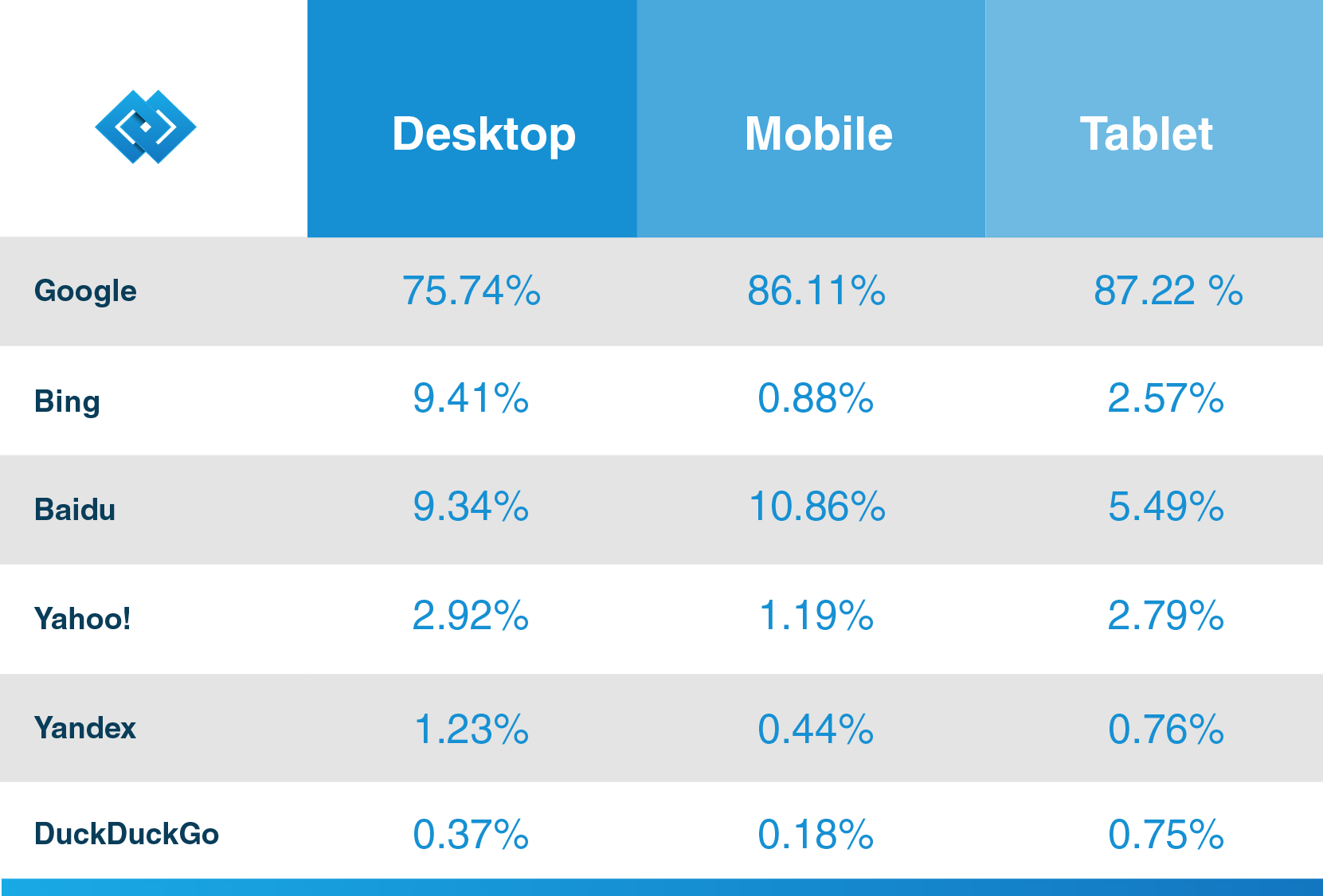
Come Hubspot, un rinomato fornitore di CRM, afferma nel suo blog, Google ha oltre il 92,42% della quota di mercato della ricerca e il suo traffico mobile supera l ‘ 86%. Quindi, se vuoi sfruttare al meglio il motore di ricerca per la tua attività, scopri ulteriori informazioni sul suo web spider in modo che i tuoi futuri clienti possano scoprire i tuoi contenuti grazie a Google.
Googlebot può essere di due tipi: un bot desktop e un crawler di app mobili, che simulano l’utente su questi dispositivi. Utilizza lo stesso principio di scansione di qualsiasi altro ragno web, come i seguenti link e la scansione dei contenuti disponibili sui siti web. Il processo è anche completamente automatizzato e può essere ricorrente, il che significa che può visitare la stessa pagina più volte a intervalli non regolari.
Se sei pronto a pubblicare contenuti, ci vorranno giorni prima che il crawler di Google lo indicizzi. Se sei il proprietario del sito Web, puoi accelerare manualmente il processo inviando una richiesta di indicizzazione tramite Fetch come Google o aggiornando la sitemap del tuo sito web.
Puoi anche usare i robot.txt (o il Robots Exclusion Protocol) per “dare istruzioni” a un spider bot, incluso Googlebot. Qui puoi consentire o impedire ai crawler di visitare determinate pagine del tuo sito web. Tuttavia, tieni presente che questo file può essere facilmente accessibile da terze parti. Vedranno quali parti del sito hai limitato dall’indicizzazione.
Web Crawler vs Web Scraper-Qual è la differenza?
Molte persone usano crawler web e raschietti web in modo intercambiabile. Tuttavia, c’è una differenza essenziale tra questi due. Se il primo si occupa principalmente di metadati di contenuti, come tag, titoli, parole chiave e altre cose, il secondo “ruba” contenuti da un sito Web per essere pubblicato sulla risorsa online di qualcun altro.
Un raschietto web “caccia” anche per dati specifici. Ad esempio, se è necessario estrarre informazioni da un sito Web in cui sono presenti informazioni come le tendenze del mercato azionario, i prezzi di Bitcoin o qualsiasi altro, è possibile recuperare i dati da questi siti Web utilizzando un bot di raschiamento Web.
Se esegui la scansione del tuo sito Web e vuoi inviare i tuoi contenuti per l’indicizzazione o hai intenzione che altre persone lo trovino, è perfettamente legale, altrimenti raschiare i siti Web di altre persone e aziende è contro la legge.
Crawler Web personalizzato-Che cos’è?
Un crawler web personalizzato è un bot che viene utilizzato per coprire un’esigenza specifica. Puoi costruire il tuo spider bot per coprire qualsiasi attività che deve essere risolta. Ad esempio, se sei un imprenditore o un marketer o qualsiasi altro professionista che si occupa di contenuti, puoi rendere più facile per i tuoi clienti e utenti trovare le informazioni che vogliono sul tuo sito web. È possibile creare una varietà di bot web per vari scopi.
Se non hai alcuna esperienza pratica nella costruzione del tuo crawler web personalizzato, puoi sempre contattare un fornitore di servizi di sviluppo software che può aiutarti.
Wrapping Up
I crawler dei siti Web sono parte integrante di qualsiasi motore di ricerca principale utilizzato per l’indicizzazione e la scoperta di contenuti. Molte società di motori di ricerca hanno i loro bot, ad esempio, Googlebot è alimentato dal gigante aziendale Google. Oltre a questo, ci sono più tipi di scansione che vengono utilizzati per coprire esigenze specifiche, come video, immagine, o social media crawling.
Tenendo conto di ciò che i robot spider possono fare, sono altamente essenziali e vantaggiosi per il tuo business perché i web crawler rivelano te e la tua azienda al mondo e possono portare nuovi utenti e clienti.
Se stai cercando di creare un crawler web personalizzato, contatta LITSLINK, un fornitore di servizi di sviluppo Web esperto, per ulteriori informazioni.