In questo articolo scritto da un fornitore di una soluzione di monitoraggio della sicurezza, l’argomento principale (spesso ripreso in altre pubblicazioni e varie fiere) era che la patch dei sistemi OT è difficile. L’autore sostiene che dal momento che è difficile, dovremmo rivolgerci ad altri metodi per migliorare la sicurezza. La sua teoria è quella di attivare una tecnologia di allarme come la sua e accoppiare gli allarmi in sospeso con un team di risposta agli incidenti di sicurezza. In altre parole, basta accettare patch è difficile, rinunciare, e versare più soldi in apprendimento in precedenza (forse?) e rispondendo più vigorosamente.
Tuttavia, questa conclusione (la patch è difficile, quindi non preoccuparti) è difettosa per un paio di motivi. Per non parlare, sorvola anche su un fattore molto grande che complica in modo significativo qualsiasi risposta o rimedio che dovrebbe essere considerato.
La prima ragione per cui questo è un consiglio pericoloso è che semplicemente non puoi ignorare le patch. Devi fare quello che puoi, quando puoi, e quando la patch non è un’opzione, passi al piano B, C e D. Non fare nulla significa che qualsiasi e tutti gli incidenti informatici che si fanno strada nel tuo ambiente produrranno il massimo danno. Questo suona molto come la difesa M&M di 20 anni fa. Questa è l’idea che la tua soluzione di sicurezza dovrebbe essere dura e croccante all’esterno, ma morbida e gommosa all’interno.
La seconda ragione per cui questo consiglio è difettoso è il presupposto che il personale di sicurezza OT (per risposta agli incidenti o patch) sia facile da trovare e distribuire! Questo non è vero – infatti, uno degli incidenti di sicurezza ICS a cui si fa riferimento nell’articolo sottolinea che mentre una patch era disponibile e pronta per l’installazione, non c’erano esperti ICS disponibili per supervisionare l’installazione della patch! Se non riusciamo a liberare i nostri esperti di sicurezza per distribuire la protezione pre-evento nota come parte di un programma proattivo di gestione delle patch, perché pensiamo di poter trovare il budget per un team completo di risposta agli incidenti dopo il fatto quando è troppo tardi?
Infine, il pezzo mancante da questo argomento è che le sfide alla gestione delle patch OT/ICS sono ulteriormente esacerbate dalla quantità e dalla complessità delle risorse e dell’architettura in una rete OT. Per essere chiari, quando viene rilasciata una nuova patch o vulnerabilità, la capacità della maggior parte delle organizzazioni di capire quante risorse sono nell’ambito e dove sono è una sfida. Ma lo stesso livello di insight e profili di asset sarà richiesto a qualsiasi team di risposta agli incidenti per essere efficace. Anche il suo consiglio di ignorare la pratica delle patch non può permetterti di evitare di dover costruire un inventario robusto e contestuale (la base per le patch!) come fondamento del vostro programma di sicurezza informatica OT.
Quindi, cosa dovremmo fare? Prima di tutto, dobbiamo cercare di rattoppare. Ci sono tre cose che un programma di gestione delle patch ICS maturo deve includere per avere successo:
- in tempo Reale, contestuale inventario
- Automazione di bonifica (entrambi i file patch e ad-hoc protezioni)
- Identificazione e l’applicazione di controlli compensativi
in tempo Reale contestuale di magazzino per la gestione delle patch
la Maggior parte OT ambienti di utilizzare la funzione di scansione basato su patch strumenti come WSUS/SCCM che sono abbastanza standard, ma non troppo perspicace per mostrarci ciò che le risorse che abbiamo e come sono configurati. Ciò che è veramente necessario è profili di asset robusti con il loro contesto operativo incluso. Cosa intendo con questo? Asset IP, modello, sistema operativo, ecc. è un elenco molto superficiale di ciò che potrebbe essere in campo per l’ultima patch. Ciò che è più prezioso è il contesto operativo come la criticità degli asset per operazioni sicure, la posizione degli asset, il proprietario degli asset, ecc. al fine di contestualizzare correttamente il nostro rischio emergente perché non tutti gli asset OT sono creati uguali. Quindi, perché non proteggere prima i sistemi critici o identificare sistemi di test adatti (che riflettono i sistemi di campo critici) e ridurre strategicamente il rischio?
E mentre stiamo costruendo questi profili di asset, abbiamo bisogno di includere quante più informazioni possibili sulle risorse oltre a IP, indirizzo Mac e versione del sistema operativo. Informazioni come software installato, utenti / account, porte,servizi, impostazioni del registro, controlli dei privilegi minimi, AV, whitelist e stato del backup, ecc. Questi tipi di fonti di informazione aumentano in modo significativo la nostra capacità di dare priorità e strategie alle nostre azioni quando emergono nuovi rischi. Vuoi delle prove? Dai un’occhiata al solito flusso di analisi offerto di seguito. Dove otterrete i dati per rispondere alle domande nelle varie fasi? Conoscenza tribale? Istinto? Perché non i dati?
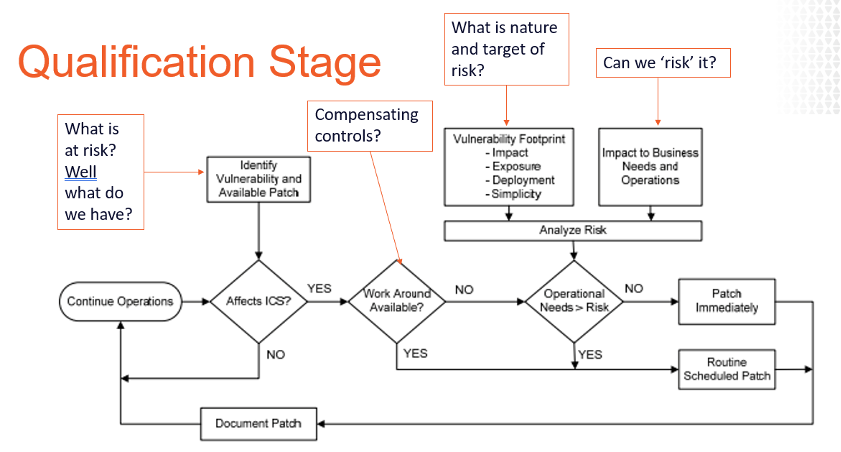
Automatizzare la correzione per l’applicazione di patch software
Un’altra sfida per l’applicazione di patch software è la distribuzione e la preparazione per distribuire patch (o controlli di compensazione) agli endpoint. Uno dei compiti più dispendiosi in termini di tempo nella gestione delle patch OT è il lavoro di preparazione. In genere include l’identificazione dei sistemi di destinazione, la configurazione della distribuzione delle patch, la risoluzione dei problemi quando falliscono o la scansione prima, il push della patch e la nuova scansione per determinare il successo.
Ma cosa succede se, ad esempio, la prossima volta che appare un rischio come BlueKeep, potresti precaricare i tuoi file sui sistemi di destinazione per prepararti ai prossimi passi? Tu e il tuo team di sicurezza OT più piccolo e agile potreste pianificare strategicamente i sistemi industriali a cui avete eseguito gli aggiornamenti delle patch per primo, secondo e terzo in base a qualsiasi numero di fattori nei vostri profili di asset solidi come la posizione o la criticità degli asset.
Facendo un ulteriore passo avanti, immagina se la tecnologia di gestione delle patch non richiedesse prima una scansione, ma piuttosto avesse già mappato la patch alle risorse in-scope e quando le hai installate (da remoto per basso rischio o di persona per alto rischio), quelle attività hanno verificato il loro successo e hanno riflesso i progressi nella tua dashboard globale?
Per tutte le risorse ad alto rischio che non è possibile o non si desidera correggere in questo momento, è possibile creare una modifica di porta, servizio o utente/account come controllo di compensazione ad hoc. Quindi, per una vulnerabilità come BlueKeep, è possibile disabilitare il desktop remoto o l’account guest. Questo approccio riduce immediatamente e significativamente il rischio attuale e consente anche più tempo per prepararsi all’eventuale patch. Questo mi porta alle azioni di “ripiegamento” di cosa fare quando la patch non è un controllo di compensazione delle opzioni.
Cosa sono i controlli di compensazione?
I controlli di compensazione sono semplicemente azioni e impostazioni di sicurezza che puoi e dovresti distribuire al posto di (o meglio) patch. In genere vengono distribuiti in modo proattivo (ove possibile), ma possono essere distribuiti in un evento o come misure temporanee di protezione come la disabilitazione del desktop remoto mentre si patch per BlueKeep, che espando nel caso di studio alla fine di questo blog.
Identificare e applicare i controlli di compensazione in OT security
I controlli di compensazione assumono molte forme dalla whitelist delle applicazioni e dal mantenimento dell’antivirus aggiornato. Ma in questo caso, voglio concentrarmi sulla gestione degli endpoint ICS come componente chiave di supporto della gestione delle patch OT.
I controlli di compensazione possono e devono essere utilizzati sia in modo proattivo che situazionale. Non sarebbe una sorpresa per nessuno nella sicurezza informatica OT scoprire account amministratore dormienti e software non necessario o inutilizzato installato sugli endpoint. Inoltre, non è un segreto che i principi di indurimento del sistema best practice non siano così universali come vorremmo.
Per proteggere veramente i nostri sistemi OT, dobbiamo anche indurire i nostri beni preziosi. Un profilo di asset robusto e in tempo reale consente alle organizzazioni industriali di eliminare in modo accurato ed efficiente i frutti a bassa sospensione (ad esempio utenti dormienti, software non necessari e parametri di indurimento del sistema) per ridurre significativamente la superficie di attacco.
Nello sfortunato caso, abbiamo una minaccia emergente (come BlueKeep) l’aggiunta di controlli di compensazione temporanei è fattibile. Un caso di studio rapido per evidenziare il mio punto:
- Vulnerabilità BlueKeep viene rilasciato.
- Il team centrale disattiva immediatamente desktop remoto su tutte le risorse di campo e le e-mail team di campo che richiedono richieste specifiche su base sistema per sistema per l’abilitazione del servizio desktop remoto durante il periodo di rischio.
- Il team centrale pre-carica i file di patch su tutte le risorse in-scope – nessuna azione, basta prepararsi.
- Il team centrale si riunisce per decidere il piano d’azione più ragionevole per criticità patrimoniale, posizione, presenza o assenza di controlli compensativi (ad esempio, un rischio critico su un asset ad alto impatto che ha fallito il suo ultimo backup va in cima alla lista. Una risorsa a basso impatto con whitelist in vigore e un buon backup completo recente può probabilmente attendere).
- Inizia il rollout delle patch e i progressi vengono aggiornati in tempo reale nel reporting globale.
- Ove necessario, i tecnici OT sono alla console supervisionando la distribuzione delle patch.
- Il programma e la comunicazione di questa necessità sono completamente pianificati e prioritari dai dati utilizzati dal team centrale.
Ecco come deve essere gestita la gestione delle patch OT. E sempre più organizzazioni stanno iniziando a mettere in atto questo tipo di programma.
Sii proattivo con i controlli di compensazione
La gestione delle patch ICS è difficile, sì, ma anche rinunciare a provare non è una buona risposta. Con un po ‘ di lungimiranza, è facile fornire i tre strumenti più potenti per controlli di patch e/o compensazione più facili ed efficaci. Insight ti mostra ciò che hai, come è configurato e quanto sia importante per te. Contesto consente di priorità (primo tentativo di patch-secondo consente di sapere come e dove applicare i controlli di compensazione). L’azione consente di correggere, proteggere, deviare, ecc. Fare affidamento solo sul monitoraggio è ammettere che ci si aspetta un incendio e l’acquisto di più rilevatori di fumo potrebbe ridurre al minimo i danni. Quale approccio pensi che la tua organizzazione preferirebbe?