En este artículo, analizamos la primera fase en el diseño del compilador, donde el programa de entrada de alto nivel se convierte en una secuencia de tokens. Esta fase se conoce como Análisis Léxico en el Diseño del Compilador.
Índice:
- Definiciones para Análisis Léxico
- Un ejemplo de Análisis Léxico
- Arquitectura de analizador léxico
- Expresiones regulares
- Autómatas finitos
- Relación entre expresiones regulares y autómatas finitos
- Regla de coincidencia más larga
- Errores léxicos
- Esquemas de recuperación de errores
- Necesidad de analizadores léxicos
- Necesidad de analizadores léxicos
El análisis léxico es el proceso de convertir una secuencia de caracteres de un programa fuente que se toma como entrada a una secuencia de tokens.
Un lex es un programa que genera analizadores léxicos.
Un analizador/analizador léxico es un programa que realiza análisis léxico.
Las funciones del analizador léxico implican;
- Lectura de caracteres de entrada del programa fuente.
- Correlación de mensajes de error con el programa fuente.
- Rayas de espacios en blanco y comentarios del programa fuente.
- Macros de expansión si se encuentran en el programa de origen.
- Introducir tokens identificados en la tabla de símbolos.
Lexeme es una instancia de un token, es decir, una secuencia de caracteres incluidos en el programa de origen de acuerdo con el patrón coincidente de un token.
Un ejemplo, Dada la expresión;
c = a + b * 5
Los lexemas y los tokens son;
| los Lexemas | Tokens |
|---|---|
| c | identificador de |
| = | asignación de símbolos |
| un | identificador de |
| + | +(además de símbolo) |
| b | identificador de |
| * | *(símbolo de multiplicación) |
| 5 | 5(número de) |
La secuencia de tokens producido por el analizador léxico permite que el analizador para analizar la sintaxis de un lenguaje de programación.
Un token es una secuencia válida de caracteres dada por un lexema, se trata como una unidad en la gramática del lenguaje de programación.
En un lenguaje de programación, esto puede incluir;
- Palabras clave
- Operadores
- Símbolos de puntuación
- Constantes
- Identificadores
- Números
Un patrón es una regla que coincide con una secuencia de caracteres(lexemas) utilizados por el token. Se puede definir mediante expresiones regulares o reglas gramaticales.
Un ejemplo de Análisis Léxico
Código
#include<iostream>// exampleint main(){ int a, b; a = 7; return 0;}Tokens
| los Lexemas | Tokens |
|---|---|
| int | palabra clave |
| principal | palabra clave |
| ( | operador |
| ) | operador |
| { | operador |
| int | palabra clave |
| un | identificador de |
| , | operador |
| b | identificador de |
| ; | operador |
| un | identificador de |
| = | asignación de símbolos |
| 10 | 10(número de) |
| ; | operador |
| volver | palabra clave |
| 0 | 0(número de) |
| ; | |
| } | operador |
No Tokens
| Tipo | Tokens |
|---|---|
| directiva de preprocesador | #include<iostream> |
| comentario | // ejemplo |
El proceso de análisis léxico constituye de dos etapas.Escaneo
- : Esto implica la lectura de caracteres de entrada y la eliminación de espacios en blanco y comentarios.
- Tokenización: Es la producción de tokens como salida.
Arquitectura del analizador léxico
La tarea principal del analizador léxico es escanear todo el programa de origen e identificar tokens uno por uno.
Los escáneres se implementan para producir tokens cuando el analizador los solicita.

Pasos:
- «obtener el siguiente token» se envía desde el analizador sintáctico al analizador léxico.
- El analizador léxico escanea la entrada hasta que se encuentre el «siguiente token».
- El token se devuelve al analizador sintáctico.
Expresiones regulares
Utilizamos expresiones regulares para expresar lenguajes finitos mediante la definición de patrones para un conjunto finito de símbolos.
La gramática definida por expresiones regulares se conoce como gramática regular y el lenguaje definido por gramática regular se conoce como lenguaje regular.
Hay reglas algebraicas obedecidas por expresiones regulares utilizadas para manipular expresiones regulares en formas equivalentes.
Operaciones.
La unión de dos idiomas A y B se escribe como
A U B = {s | s está en A o s está en B}
La concatenación de dos idiomas A y B se escribe como
AB = {ss | s está en A y s está en B}
El cierre kleen de un idioma A se escribe como
A*=, que es cero o más ocurrencias del idioma A.
Notaciones.
Si x e y son expresiones regulares que denotan los lenguajes A(x) y B(y),
(x) es una expresión regular que denota A(x).
Union(x)|(y) es una expresión regular que denota A(x) B (y).
Concatenación(x) (y) es una expresión regular que denta A(x)B (y).
Kleen closure (x) * es una expresión regular que denota(A (x))*
Precedencia y asociatividad.
*’ concatenación .’y / (tubo) son asociativos a la izquierda.
El cierre Kleen * tiene la prioridad más alta.
Concatenación (.) sigue en precedencia.
(pipe) | tiene la precedencia más baja.
Representando tokens válidos de un idioma en expresiones regulares.
X es una expresión regular, por lo tanto;
- x* representa cero o más apariciones de x.
- x+ representa una o más apariciones de x, es decir, {x, xx, xxx}
- x? representa como máximo una ocurrencia de x ie {x}
- representa todos los alfabetos en minúsculas en el idioma inglés.
- representan todos los alfabetos en mayúsculas en el idioma inglés.
- representan todos los números naturales.
Representación de la ocurrencia de símbolos utilizando expresiones regulares
Letter = o
Digit = o|0|1|2|3|4|5|6|7|8|9
Sign =
Representa tokens de idioma utilizando expresiones regulares.
Decimal = (signo)?(digit)+
Identifier = (letter) (letter | digit)*
Autómatas finitos
Esta es la combinación de cinco tuplas (Q, Σ, q0, qf, δ) que se centran en estados y transiciones a través de símbolos de entrada.
Reconoce patrones tomando la cadena de símbolo como entrada y cambia su estado en consecuencia.
El modelo matemático para autómatas finitos consiste en;
- Conjunto finito de estados (Q)
- Conjunto finito de símbolos de entrada (Σ)
- Un estado de inicio (q0)
- Conjunto de estados finales (qf)
- Función de transición (δ)
Los autómatas finitos se utilizan en el análisis léxico para producir tokens en forma de identificadores, palabras clave y constantes desde el programa de entrada.
Finite automata alimenta la cadena de expresión regular y el estado cambia para cada literal.
Si la entrada se procesa correctamente, los autómatas alcanzan el estado final y se aceptan, de lo contrario, se rechazan.
Construcción de Autómatas Finitos
Sea L (r) un lenguaje regular por algunos autómatas finitos F(A).
Por lo tanto;
- Estados: Los círculos representan los estados de FA y sus nombres están escritos dentro de los círculos.
- Estado de inicio: Este es el estado en el que se inicia el autómata. Tendrá una flecha apuntando hacia ella.
- Estados intermedios: Estos tienen dos flechas, una apuntando hacia él y otra apuntando desde los estados intermedios.
- Estado final: Se espera que los autómatas estén en el estado final cuando la cadena de entrada se haya analizado correctamente y se haya representado mediante círculos dobles, de lo contrario, la entrada se rechazará. Puede contener un número impar de flechas apuntando hacia ella y un número par apuntando hacia ella, es decir,
flechas impares = flechas pares + 1. - Transición :Cuando se encuentra un símbolo deseado en la entrada, se producirá la transición de un estado a otro. Los autómatas se mueven al siguiente estado o persisten.
Una flecha dirigida mostrará el movimiento de un estado a otro mientras que una flecha apunta hacia el estado de destino.
Si los autómatas permanecen en el mismo estado, se dibuja una flecha que apunta desde un estado hacia sí mismo.
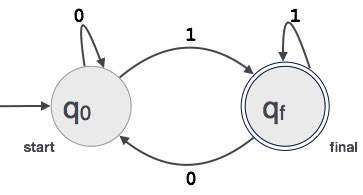
Un ejemplo; Supongamos que FA acepta un valor binario de 3 dígitos que termina en 1.
Luego FA ={Q (q0, qf), Σ (0,1), q0, qf, δ}
Relación entre expresiones regulares y autómatas finitos
La relación entre expresiones regulares y autómatas finitos es la siguiente;
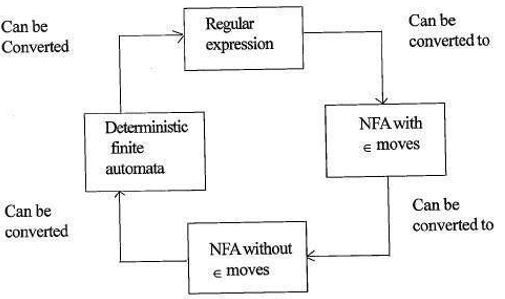
La siguiente figura muestra que es fácil de convertir;
- Expresiones regulares a autómatas finitos No deterministas (NFA) con movimientos de∈.
- Autómatas finitos no deterministas con ∈ se mueve a sin ∈ se mueve
- Autómatas finitos no deterministas sin ∈ se mueve a Autómatas Finitos Deterministas (DFA).
- Autómatas Finitos Deterministas a Expresión Regular.
Un Lex aceptará expresiones regulares como entrada y devolverá un programa que simula un autómata finito para reconocer las expresiones regulares.
Por lo tanto, lex combinará la generación de patrones de cadena (expresiones regulares que definen las cadenas de interés para lex) y el reconocimiento de patrones de cadena (un autómata finito que reconoce las cadenas de interés).
Regla de coincidencia más larga
Establece que el lexema escaneado debe determinarse en función de la coincidencia más larga entre todos los tokens disponibles.
Esto se usa para resolver ambigüedades al decidir el siguiente token en el flujo de entrada.
Durante el análisis del código fuente, el analizador léxico escaneará el código letra por letra y, cuando se detecte un operador, un símbolo especial o un espacio en blanco, decidirá si una palabra está completa.
Ejemplo:
int intvalue;Al escanear lo anterior, el analizador no puede determinar si ‘int’ es una palabra clave int o el prefijo del identificador intvalue.
Se aplica la prioridad de regla mediante la cual se dará prioridad a una palabra clave sobre la entrada del usuario, lo que significa que en el ejemplo anterior el analizador generará un error.
Errores léxicos
Se produce un error léxico cuando una secuencia de caracteres no se puede escanear en un token válido.
Estos errores pueden deberse a errores ortográficos de identificadores, palabras clave u operadores.
Generalmente, aunque los errores léxicos son muy poco comunes, son causados por caracteres ilegales en un token.Los errores
pueden ser;
- Error de ortografía.
- Transposición de dos caracteres.
- caracteres Ilegales.
- Longitud superior de las constantes identificativas o numéricas.
- Sustitución de un personaje con un carácter incorrecto
- Eliminación de un personaje que debe estar presente.
La recuperación de errores implica;
- Eliminar un carácter de la entrada restante
- Transponer dos caracteres adyacentes
- Eliminar un carácter de la entrada restante
- Insertar el carácter que falta en la entrada restante
- Reemplazar un carácter por otro carácter.
- Ignorar caracteres sucesivos hasta que se forme un token legal (recuperación en modo pánico).
Esquemas de recuperación de errores
Recuperación en modo pánico.
En este esquema de recuperación de errores, los patrones no coincidentes se eliminan de la entrada restante hasta que el analizador léxico pueda encontrar un token bien formado al principio de la entrada restante.
Una implementación más sencilla es una ventaja de este enfoque.
Tiene la limitación de que se omite una gran cantidad de entrada sin verificar errores adicionales.
Corrección local.
Cuando se detecta un error en un punto, se ejecutan operaciones de inserción/eliminación y/o reemplazo hasta que se logra un texto bien formado.
El analizador se reinicia con el nuevo texto resultante como entrada.
Corrección global.
Es un modo de recuperación de pánico mejorado preferido cuando falla la corrección local.
Tiene altos requisitos de tiempo y espacio, por lo que no se implementa prácticamente.
Necesidad de analizadores léxicos
- Eficiencia mejorada del compilador: las técnicas de almacenamiento en búfer especializadas para leer caracteres aceleran el proceso del compilador.
- Simplicidad del diseño del compilador: La eliminación de espacios en blanco y comentarios habilitará construcciones sintácticas eficientes para el analizador de sintaxis.
- Portabilidad del compilador: solo el escáner se comunica con el mundo externo.
- Especialización: se pueden utilizar técnicas especializadas para mejorar el proceso de análisis léxico
Problemas con el análisis léxico
- Lookahead
Dada una cadena de entrada, los caracteres se leen de izquierda a derecha uno por uno.
Para determinar si un token está terminado o no, tenemos que mirar el siguiente carácter.
Ejemplo: Es ‘ = ‘un operador de asignación o el primer carácter en el operador’==’.
Lookahead omite caracteres en la entrada hasta que se encuentre un token bien formado, esto demuestra que look ahead no puede detectar errores significativos excepto errores simples como símbolos ilegales. - Ambigüedades
Los programas escritos con lex aceptarán especificaciones ambiguas y, por lo tanto, elegirán la coincidencia más larga y cuando varias expresiones coincidan con la entrada, se prefiere la coincidencia más larga o se prioriza la primera regla entre las reglas coincidentes. - Palabras clave reservadas
Ciertos lenguajes tienen palabras reservadas que no están reservadas en otros lenguajes de programación, por ejemplo, elif es una palabra reservada en python pero no en C. - Dependencia de contexto
Ejemplo:
Dada la instrucción DO 10 l = 10.86, DO10l es un identificador y DO no es una palabra clave.
Y dada la instrucción DO 10 l = 10, 86, DO es una palabra clave
, tales instrucciones requerirían una visión de futuro sustancial para la resolución.
Las aplicaciones
- Utilizadas por los compiladores crean ejecutables binarios cumplidos a partir de código analizado.
- Utilizado por los navegadores web para formatear y mostrar una página web que se analiza HTML, CSS y java script.
Con este artículo en OpenGenus, debe tener una idea sólida del Análisis Léxico en el Diseño del Compilador.