En este artículo escrito por un proveedor de una solución de monitoreo de seguridad, el argumento principal (a menudo repetido en otras publicaciones y varias ferias comerciales) fue que parchear sistemas OT es difícil. El autor sostiene que, dado que es difícil, deberíamos recurrir a otros métodos para mejorar la seguridad. Su teoría es activar una tecnología de alerta como la suya y emparejar las alarmas pendientes con un equipo de respuesta a incidentes de seguridad. En otras palabras, simplemente acepte que el parche es difícil, ríndase y invierta más dinero en aprender antes (¿tal vez?) y respondiendo más vigorosamente.
Sin embargo, esta conclusión (parchear es difícil, así que no te molestes) es defectuosa por un par de razones. Sin mencionar que también pasa por alto un factor muy grande que complica significativamente cualquier respuesta o remediación que deba considerarse.
La primera razón por la que este es un consejo peligroso es que simplemente no puede ignorar los parches. Debe hacer lo que pueda, cuando pueda, y cuando el parche no sea una opción, pase al plan B, C y D. No hacer nada significa que todos y cada uno de los incidentes relacionados con el ciberespacio que se abran paso en su entorno producirán el máximo daño. Esto se parece mucho a la defensa M& M de hace 20 años. Esta es la idea de que su solución de seguridad debe ser dura y crujiente por fuera, pero suave y masticable por dentro.
La segunda razón por la que este consejo es defectuoso es la suposición de que el personal de seguridad de OT (para respuesta a incidentes o parches) es fácil de encontrar e implementar. Esto no es cierto, de hecho, uno de los incidentes de seguridad de ICS a los que se hace referencia en el artículo señala que, si bien un parche estaba disponible y listo para instalar, ¡no había expertos de ICS disponibles para supervisar la instalación del parche! Si no podemos liberar a nuestros expertos en seguridad para que implementen una protección previa a eventos conocida como parte de un programa proactivo de administración de parches, ¿por qué creemos que podemos encontrar el presupuesto para un equipo completo de respuesta a incidentes después del hecho cuando ya es demasiado tarde?
Finalmente, la pieza que falta de este argumento es que los desafíos para la administración de parches OT/ICS se exacerban aún más por la cantidad y complejidad de los activos y la arquitectura en una red OT. Para ser claros, cuando se lanza un nuevo parche o vulnerabilidad, la capacidad de la mayoría de las organizaciones para comprender cuántos activos están en el alcance y dónde se encuentran es un desafío. Pero se requerirá el mismo nivel de conocimiento y perfiles de activos de cualquier equipo de respuesta a incidentes para ser eficaz. Incluso su consejo de ignorar la práctica de los parches no le permite evitar tener que construir un inventario contextual sólido (¡la base para los parches!) como base de su programa de ciberseguridad de OT.
Entonces, ¿qué debemos hacer? En primer lugar, debemos tratar de remendar. Hay tres cosas que un programa de administración de parches ICS maduro debe incluir para tener éxito:
- Inventario contextual en tiempo real
- Automatización de la corrección (tanto archivos de parches como protecciones ad hoc)
- Identificación y aplicación de controles compensadores
Inventario contextual en tiempo real para la administración de parches
La mayoría de los entornos de TO utilizan herramientas de parches basadas en análisis, como WSUS/SCCM, que son bastante estándar pero no demasiado perspicaz para mostrarnos qué activos tenemos y cómo están configurados. Lo que realmente se necesita son perfiles de activos sólidos con su contexto operativo incluido. ¿Qué quiero decir con esto? IP de activos, modelo, sistema operativo, etc. es una lista muy superficial de lo que podría estar en el alcance del último parche. Lo que es más valioso es el contexto operativo, como la criticidad de los activos para operaciones seguras, la ubicación de los activos, el propietario de los activos, etc. con el fin de contextualizar adecuadamente nuestro riesgo emergente, ya que no todos los activos de TO son iguales. Entonces, ¿por qué no proteger primero los sistemas críticos o identificar sistemas de prueba adecuados (que reflejen los sistemas de campo críticos) y reducir estratégicamente el riesgo?
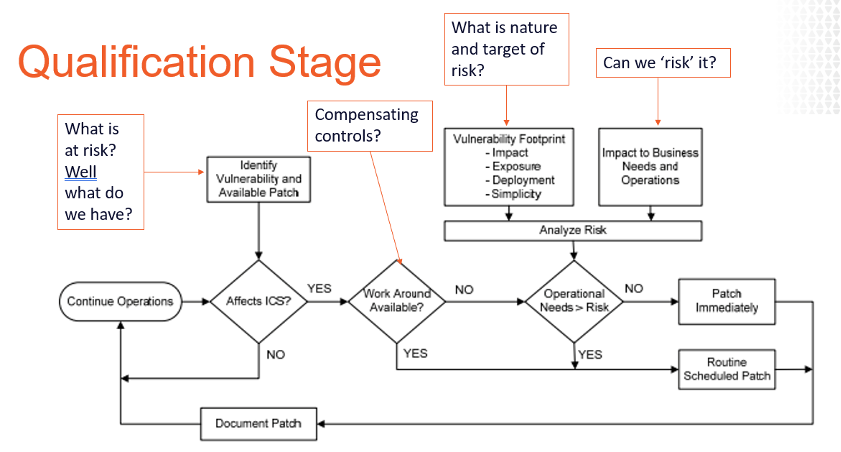
Y mientras creamos estos perfiles de activos, necesitamos incluir tanta información como sea posible sobre los activos más allá de la IP, la dirección Mac y la versión del sistema operativo. Información como software instalado, usuarios / cuenta, puertos, servicios, configuración del registro, controles de privilegios mínimos, AV, lista blanca y estado de copia de seguridad, etc. Este tipo de fuentes de información aumentan significativamente nuestra capacidad de priorizar y elaborar estrategias de forma precisa cuando surgen nuevos riesgos. ¿Quieres pruebas? Eche un vistazo al flujo de análisis habitual que se ofrece a continuación. ¿De dónde obtendrá los datos para responder a las preguntas en las diversas etapas? Conocimiento Tribal? ¿Instinto? ¿Por qué no data?
Automatizar la corrección para la aplicación de parches de software
Otro desafío de aplicación de parches de software es la implementación y preparación para implementar parches (o controles de compensación) en los puntos finales. Una de las tareas que más tiempo consume en la administración de parches de TO es el trabajo de preparación. Por lo general, incluye identificar los sistemas de destino, configurar la implementación del parche, solucionar problemas cuando fallan o escanear primero, empujar el parche y volver a escanear para determinar el éxito.
Pero, ¿y si, por ejemplo, la próxima vez que aparezca un riesgo como BlueKeep, pudiera cargar previamente sus archivos en los sistemas de destino para prepararse para los siguientes pasos? Usted y su equipo de seguridad de TO más pequeño y ágil podrían planificar estratégicamente a qué sistemas industriales realizó actualizaciones de parches primero, segundo y tercero en función de cualquier número de factores en sus perfiles de activos sólidos, como la ubicación o la criticidad de los activos.
Yendo un paso más allá, imagínese si la tecnología de administración de parches no requiriera un escaneo primero, sino que ya hubiera mapeado el parche a activos dentro del alcance y, a medida que los instalaba (ya sea de forma remota para bajo riesgo o en persona para alto riesgo), esas tareas verificaban su éxito y reflejaban ese progreso en su panel de control global.
Para todos sus activos de alto riesgo que no puede o no desea parchear en este momento, podría crear un puerto, servicio o cambio de usuario/cuenta como un control de compensación ad hoc. Por lo tanto, para una vulnerabilidad como BlueKeep, puede deshabilitar el escritorio remoto o la cuenta de invitado. Este enfoque reduce de forma inmediata y significativa el riesgo actual y también permite más tiempo para prepararse para el parche final. Esto me lleva a las acciones de ‘retroceso’ de qué hacer cuando parchear no es una opción: controles de compensación.
¿Qué son los controles de compensación?
Los controles de compensación son simplemente acciones y configuraciones de seguridad que puede y debe implementar en lugar de (o mejor dicho, también) parches. Por lo general, se implementan de forma proactiva (siempre que sea posible), pero se pueden implementar en un evento o como medidas temporales de protección, como deshabilitar el escritorio remoto mientras se aplica un parche a BlueKeep, que explico en el estudio de caso al final de este blog.
Identifique y aplique controles de compensación en seguridad de TO
Los controles de compensación toman muchas formas, desde la lista blanca de aplicaciones hasta mantener actualizado el antivirus. Pero en este caso, quiero centrarme en ICS endpoint management como un componente de soporte clave de la administración de parches de TO.
Los controles de compensación pueden y deben utilizarse tanto de forma proactiva como situacional. No sería una sorpresa para nadie en seguridad cibernética de OT descubrir cuentas de administración inactivas y software innecesario o no utilizado instalado en los puntos de conexión. Tampoco es ningún secreto que los principios de endurecimiento de los sistemas de mejores prácticas no son tan universales como nos gustaría.
Para proteger verdaderamente nuestros sistemas de TO, también necesitamos endurecer nuestras preciadas posesiones. Un perfil de activos robusto y en tiempo real permite a las organizaciones industriales eliminar de manera precisa y eficiente la fruta que cuelga poco (es decir, usuarios inactivos, software innecesario y parámetros de endurecimiento del sistema) para reducir significativamente la superficie de ataque.
En el desafortunado evento, tenemos una amenaza emergente (como BlueKeep) agregar controles compensatorios temporales es factible. Un estudio de caso rápido para resaltar mi punto:
- Se libera la vulnerabilidad BlueKeep.
- El equipo central deshabilita de inmediato el escritorio remoto en todos los activos de campo y envía correos electrónicos al equipo de campo que requieran solicitudes específicas de sistema por sistema para que el servicio de escritorio remoto se habilite durante el período de riesgo.
- El equipo central carga previamente los archivos de parches en todos los activos dentro del alcance, sin acción, solo prepárese.
- El equipo central se reúne para decidir el plan de acción más razonable por la criticidad de los activos, la ubicación, la presencia o ausencia de controles compensadores (es decir, un riesgo crítico en un activo de alto impacto que falló en su última copia de seguridad va a la parte superior de la lista. Es probable que un activo de bajo impacto con lista blanca en vigor y una copia de seguridad completa buena reciente puedan esperar).
- Comienza la implementación de parches y el progreso se actualiza en vivo en informes globales.
- Cuando sea necesario, los técnicos de OT están en la consola supervisando la implementación del parche.
- El cronograma y la comunicación de esta necesidad están planificados y priorizados por los datos utilizados por el equipo central.
Así es como se debe manejar el manejo de parches de TO. Y cada vez más organizaciones están empezando a poner en marcha este tipo de programas.
Sea proactivo con controles de compensación
La administración de parches de ICS es difícil, sí, pero simplemente renunciar a intentarlo tampoco es una buena respuesta. Con un poco de previsión, es fácil proporcionar las tres herramientas más poderosas para controles de parcheo y/o compensación más fáciles y efectivos. Insight le muestra lo que tiene, cómo está configurado y cuán importante es para usted. El contexto le permite priorizar (el primer intento de parche, el segundo le permite saber cómo y dónde aplicar los controles de compensación). La acción le permite corregir, proteger, desviar, etc. Confiar solo en el monitoreo es admitir que espera un incendio y comprar más detectores de humo podría minimizar el daño. ¿Qué enfoque cree que preferiría su organización?