Con redes complejas que consisten en nube, TI híbrida, virtualización, redes de área de almacenamiento, etc., los problemas de TI multifacéticos pueden ser difíciles de identificar y diagnosticar. Cuando surge un problema, por ejemplo, una aplicación o un servidor de mal rendimiento, la investigación puede tardar mucho tiempo en localizar el problema principal. El problema podría estar en el almacenamiento, la conectividad de red, el acceso de usuarios o una combinación de recursos y configuraciones.
Para investigar el problema, cree proyectos de solución de problemas con el panel de análisis de rendimiento (PerfStack™) que correlacione visualmente los datos históricos de varios productos y tipos de entidades de SolarWinds en una sola vista.
Con los paneles de análisis de rendimiento, puede hacer lo siguiente:
- Compare y analice varios tipos de métricas en una sola vista, incluidos el estado, los eventos y las estadísticas.
- Compare y analice métricas para varias entidades en una sola vista, incluidos nodos, interfaces, volúmenes, aplicaciones y más.
- Correlacione los datos de toda la plataforma Orion en una única línea de tiempo compartida.
- Visualice datos híbridos para locales, en la nube y todo lo demás.
- Comparta un proyecto de solución de problemas con sus equipos y expertos para revisar los datos históricos de un problema.
Para VMAN, las posibilidades son infinitas para el análisis de aplicaciones y los entornos híbridos:
- Recorrer visualmente los datos históricos de las máquinas virtuales de su entorno
- Verificar los problemas de asignación de recursos en entornos híbridos
- Correlacionar datos para solucionar problemas de tráfico de red enviado y recibido por servidores virtuales (hosts, clústeres, almacenes de datos y máquinas virtuales), servidores locales e instancias en la nube
El siguiente ejemplo muestra cómo identificar la causa raíz de una máquina virtual experimentar problemas de rendimiento. En este escenario, un host virtual encontró un problema de recursos y rendimiento hasta el punto en que los usuarios encuentran respuestas y acceso más lentos. El problema desencadenó una alerta, que notificó al propietario de la aplicación, que lo elevó a los administradores del sistema y de la red.
Cree un nuevo proyecto de solución de problemas para investigar el problema y comparar métricas para el host y todos los sistemas de entorno virtual relacionados para rastrear tendencias y picos de uso.
-
En la Consola Web de Orion, seleccione Mis paneles > Inicio > Análisis de rendimiento.
Esto abre el panel de análisis de rendimiento, o PerfStack, para crear gráficos y tablas utilizando métricas extraídas de aplicaciones y servidores monitorizados en la paleta de métricas. Cada gráfico puede contener varias métricas para correlacionar directamente los datos.
-
En el Nuevo proyecto de Análisis, haga clic en Agregar entidades.
Para comenzar, debe localizar y agregar la máquina virtual en peligro. En el campo de búsqueda, ingrese syd para mostrar una lista de servidores virtuales que comparten ese nombre. Expanda y seleccione Tipos o Estado para filtrar la lista si es necesario.
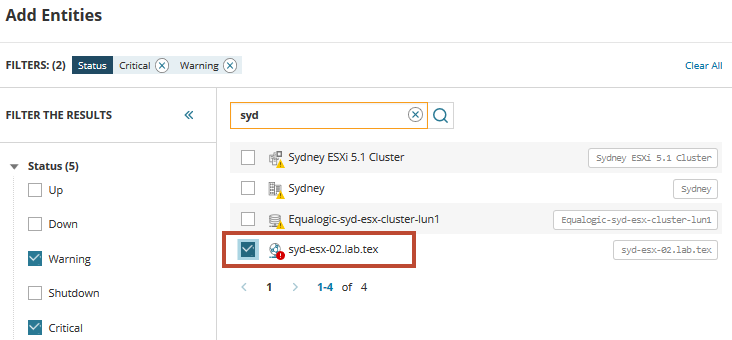
En la lista, encontramos el host virtual que encuentra los problemas y activa las alertas. Seleccione el host y agréguelo a la paleta métrica del panel. Haga clic en el icono entidades relacionadas para mostrar todos los servidores y servicios relacionados al host.
¿Está interesado en todos los nodos, aplicaciones, servidores y más asociados a este nodo seleccionado? Haga clic en el icono entidades relacionadas.
 Todas las entidades relacionadas se muestran en la paleta de métricas, lo que proporciona más opciones para las métricas que posiblemente causen problemas.
Todas las entidades relacionadas se muestran en la paleta de métricas, lo que proporciona más opciones para las métricas que posiblemente causen problemas.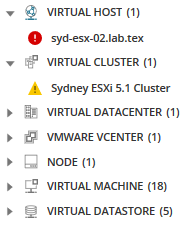
-
Seleccione el nodo de host syd para ver y seleccione métricas para arrastrar y soltar en el panel. Puede arrastrarlos al mismo gráfico para comparar valores entre métricas.
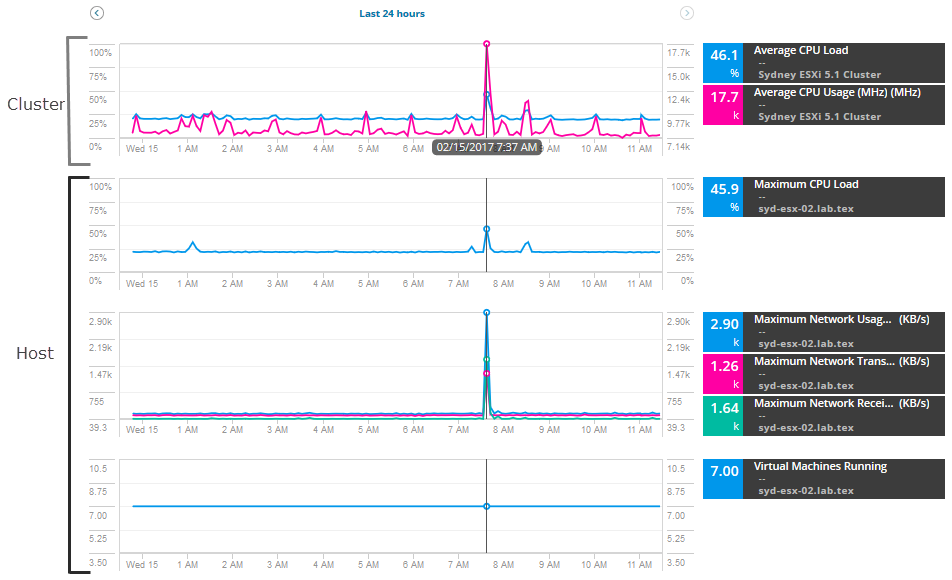
Para comenzar a investigar, obtenga una serie de métricas para el host y el clúster, comparando métricas para encontrar picos o un uso elevado. Para este escenario, agregue estas métricas de host:
- Uso máximo de Red
- Velocidad Máxima de Transmisión de Red
- Velocidad Máxima de Recepción de Red
- Máquinas virtuales que ejecutan
Para el clúster, agregue estas métricas:
- Carga media de CPU
- Uso medio de CPU
Se muestran los cuadros y gráficos con datos y alertas de las últimas 12 horas de métricas. Puede ampliar la fecha y la hora para ver métricas históricas adicionales a lo largo de la alerta.
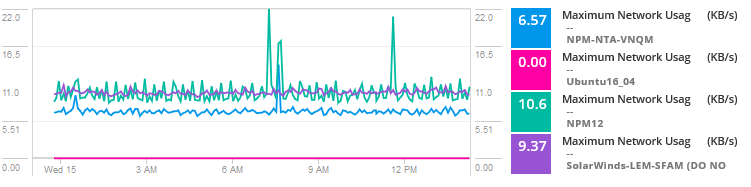
Agregue métricas de uso para las máquinas virtuales en el host para comparar el uso y la actividad de la red.
-
Al analizar los datos, el problema parece ser un vecino ruidoso para una de las máquinas virtuales que consume recursos y experimenta un alto tráfico que causa cuellos de botella y problemas para las máquinas virtuales que comparten el host. Básicamente, otro servidor, servicio o aplicación consume mayor ancho de banda, E/S de disco, CPU y otros recursos que causan problemas para esta aplicación específica.
Esta información proporciona a los administradores de redes y sistemas una orientación para investigar más a fondo y resolver problemas de latencia. Para resolverlo, pueden reasignar recursos o mover la aplicación de alto consumo a otra ubicación.
-
Haga clic en Guardar y asigne un nombre al proyecto.
El proyecto se guarda como un panel con las métricas seleccionadas en el intervalo de fecha y hora establecido.
Cuando se guarda, la URL se convierte en un enlace que se puede compartir. Copie y comparta el enlace al panel guardado en tickets o correos electrónicos enviados por los administradores del sistema y la red y el propietario del producto. Pueden acceder al enlace para revisar los datos recopilados y solucionar problemas.
Después de reasignar recursos y realizar cambios en la red, vuelva a abrir el panel para verificar los cambios y las nuevas tendencias de uso de las métricas encuestadas.