Avec des réseaux complexes composés de cloud, d’informatique hybride, de virtualisation, de réseaux de stockage, etc., les problèmes informatiques à multiples facettes peuvent être difficiles à identifier et à diagnostiquer. Lorsqu’un problème apparaît, par exemple une application ou un serveur aux performances médiocres, l’enquête peut prendre un temps considérable pour localiser le problème principal. Le problème peut être lié au stockage, à la connectivité réseau, à l’accès des utilisateurs ou à un mélange de ressources et de configurations.
Pour étudier le problème, créez des projets de dépannage à l’aide du tableau de bord d’analyse des performances (PerfStack™) qui corrélent visuellement les données historiques de plusieurs produits et types d’entités SolarWinds dans une seule vue.
Avec les tableaux de bord d’analyse des performances, vous pouvez effectuer les opérations suivantes:
- Comparez et analysez plusieurs types de mesures dans une seule vue, y compris l’état, les événements et les statistiques.
- Comparez et analysez les métriques de plusieurs entités dans une seule vue, y compris les nœuds, les interfaces, les volumes, les applications, etc.
- Corrélez les données de l’ensemble de la plate-forme Orion sur une seule ligne temporelle partagée.
- Visualisez les données hybrides sur site, dans le cloud et tout le reste.
- Partagez un projet de dépannage avec vos équipes et vos experts pour examiner les données historiques d’un problème.
Pour VMAN, les possibilités sont infinies pour l’analyse d’applications et les environnements hybrides:
- Parcourez visuellement les données historiques des machines virtuelles de votre environnement
- Vérifiez les problèmes d’allocation de ressources dans des environnements hybrides
- Corrélez les données pour résoudre le trafic réseau envoyé et reçu par des serveurs virtuels (hôtes, clusters, banques de données et machines virtuelles), des serveurs sur site et des instances cloud
L’exemple suivant vous montre comment identifier une cause première d’un problème de VM rencontrant des problèmes de performances. Dans ce scénario, un hôte virtuel a rencontré un problème de ressources et de performances au point où les utilisateurs rencontrent des réponses et un accès plus lents. Le problème a déclenché une alerte, qui a averti le propriétaire de votre application, qui a transmis le problème aux administrateurs système et réseau.
Créez un nouveau projet de dépannage pour étudier le problème afin de comparer les métriques de l’hôte et de tous les systèmes d’environnement virtuel associés afin de suivre les tendances et les pics d’utilisation.
-
Dans la Console Web Orion, sélectionnez Mes Tableaux de bord > Accueil > Analyse des performances.
Cela ouvre le tableau de bord Analyse des performances, ou PerfStack, pour créer des tableaux et des graphiques à l’aide de mesures extraites d’applications et de serveurs surveillés dans la palette de mesures. Chaque graphique peut contenir plusieurs métriques pour corréler directement les données.
-
Dans le Nouveau projet d’analyse, cliquez sur Ajouter des entités.
Pour commencer, vous devez localiser et ajouter la machine virtuelle en détresse. Dans le champ de recherche, entrez syd pour afficher une liste de serveurs virtuels partageant ce nom. Développez et sélectionnez Types ou Statut pour filtrer la liste si nécessaire.
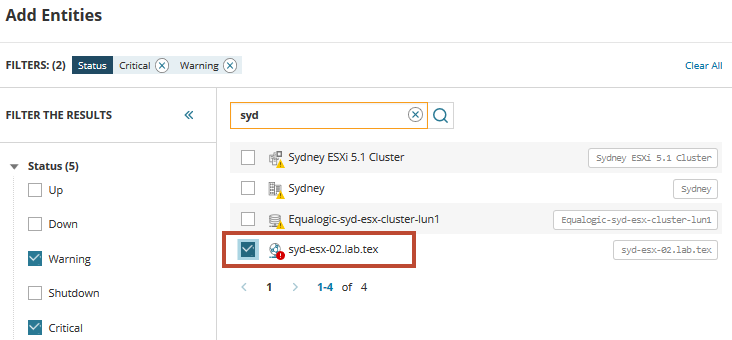
Dans la liste, nous trouvons l’hôte virtuel rencontrant les problèmes et déclenchant des alertes. Sélectionnez l’hôte et ajoutez-le à la palette de mesures du tableau de bord. Cliquez sur l’icône Entités associées pour afficher tous les serveurs et services associés à l’hôte.
Intéressé par tous les nœuds, applications, serveurs associés et plus encore à ce nœud sélectionné ? Cliquez sur l’icône Entités associées.
 Toutes les entités associées s’affichent dans la palette de mesures offrant plus d’options pour les mesures pouvant causer des problèmes.
Toutes les entités associées s’affichent dans la palette de mesures offrant plus d’options pour les mesures pouvant causer des problèmes.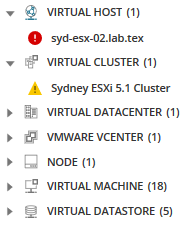
-
Sélectionnez le nœud hôte syd à afficher et sélectionnez les mesures à glisser-déposer sur le tableau de bord. Vous pouvez les faire glisser dans le même graphique pour comparer les valeurs entre les métriques.
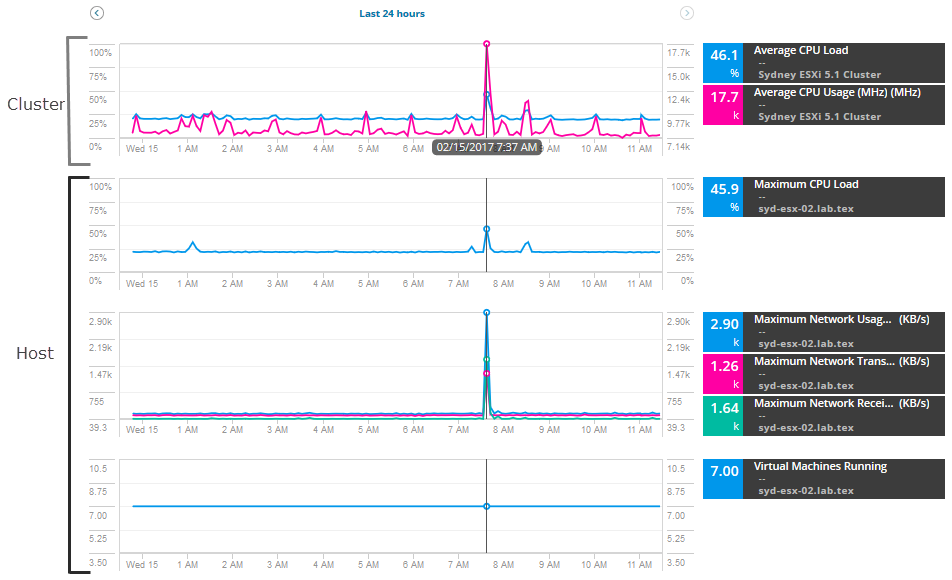
Pour commencer à étudier, extrayez une série de mesures pour l’hôte et le cluster, en comparant les mesures pour trouver des pics ou une utilisation élevée. Pour ce scénario, ajoutez ces métriques d’hôte:
- Utilisation Maximale du Réseau
- Taux de Transmission Maximal du Réseau
- Taux de Réception Maximal du Réseau
- Machines Virtuelles Exécutées
Pour le cluster, ajoutez ces mesures:
- Charge CPU moyenne
- Utilisation CPU moyenne
Les tableaux et graphiques affichent des données et des alertes pour les 12 dernières heures de mesures. Vous pouvez étendre la date et l’heure pour afficher des mesures historiques supplémentaires au cours de l’alerte.
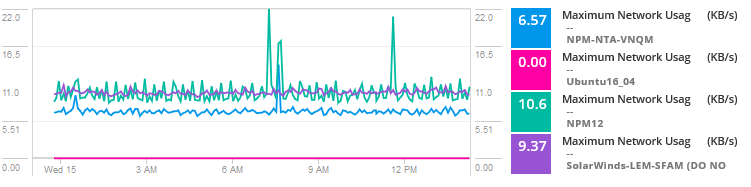
Ajoutez des métriques d’utilisation pour les machines virtuelles sur l’hôte pour comparer l’utilisation et l’activité du réseau.
-
En analysant les données, le problème semble être un voisin bruyant pour l’une des machines virtuelles consommant des ressources et connaissant un trafic élevé, provoquant des goulots d’étranglement et des problèmes pour les machines virtuelles partageant l’hôte. Fondamentalement, un autre serveur, service ou application consomme une bande passante plus élevée, des E / S de disque, un processeur et d’autres ressources provoquant des problèmes pour cette application spécifique.
Ces informations donnent à vos administrateurs réseau et système une orientation pour une enquête plus approfondie et la résolution des problèmes de latence. Pour résoudre ce problème, ils peuvent réaffecter des ressources ou déplacer l’application à forte consommation vers un autre emplacement.
-
Cliquez sur Enregistrer et donnez un nom au projet.
Le projet enregistre en tant que tableau de bord avec les mesures sélectionnées dans la plage de date et d’heure définie.
Une fois enregistrée, l’URL devient un lien partageable. Copiez et partagez le lien vers le tableau de bord enregistré dans les tickets ou les e-mails envoyés par les administrateurs système et réseau et le propriétaire du produit. Ils peuvent accéder au lien pour examiner les données collectées et résoudre les problèmes.
Après avoir réaffecté des ressources et apporté des modifications au réseau, rouvrez le tableau de bord pour vérifier les modifications et les nouvelles tendances d’utilisation des métriques interrogées.