ebben a cikkben a fordító tervezésének első szakaszát tárgyaljuk, ahol a magas szintű bemeneti program tokenek sorozatává alakul. Ezt a fázist lexikai elemzésnek nevezik a fordító tervezésében.
Tartalomjegyzék:
- a lexikális analízis definíciói
- példa a lexikális analízisre
- a lexikális analízis architektúrája
- reguláris kifejezések
- véges Automata
- kapcsolat a reguláris kifejezések és a véges automata között
- leghosszabb egyezési szabály
- lexikai hibák
- hibajavítási rendszerek
- lexikális analizátorok szükségessége
- lexikális analizátorok szükségessége
a lexikális elemzés az a folyamat, amikor egy karaktersorozatot konvertálnak egy Forrásprogramból, amelyet bemenetként vesznek fel egy tokenek sorozatába.
a lex egy olyan program, amely lexikai analizátorokat generál.
a lexikai elemző/lexer/szkenner egy olyan program, amely lexikai elemzést végez.
a lexikai elemző szerepe magában foglalja;
- bemeneti karakterek olvasása a forrásprogramból.
- a hibaüzenetek korrelációja a forrásprogrammal.
- fehér terek és megjegyzések csíkozása a forrásprogramból.
- bővítő makrók, ha megtalálhatók a forrásprogramban.
- az azonosított tokenek bevitele a szimbólumtáblába.
a Lexeme egy token példánya, vagyis a forrásprogramban szereplő karakterek sorozata a token megfelelő mintája szerint.
egy példa, mivel a kifejezés;
c = A + b * 5
a lexémák és tokenek;
| lexémák | tokenek |
|---|---|
| c | azonosító |
| = | hozzárendelési szimbólum |
| a | azonosító |
| + | +(kiegészítő szimbólum) |
| b | azonosító |
| * | *(szorzás szimbólum) |
| 5 | 5(szám) |
a lexikai elemző által előállított tokenek sorrendje lehetővé teszi az elemző számára, hogy elemezze a programozási nyelv.
a token egy lexéma által adott karaktersorozat, amelyet a programozási nyelv nyelvtanában egységként kezelnek.
egy programozási nyelvben ez magában foglalhatja;
- kulcsszavak
- operátorok
- írásjelek
- állandók
- azonosítók
- számok
a minta olyan szabály, amely megfelel a token által használt karakterek(lexémák) sorozatának. Reguláris kifejezésekkel vagy nyelvtani szabályokkal határozható meg.
egy példa a lexikai elemzés
Kód
#include<iostream>// exampleint main(){ int a, b; a = 7; return 0;}tokenek
| lexémák | tokenek |
|---|---|
| int | kulcsszó |
| fő | kulcsszó |
| ( | Üzemeltető |
| ) | Üzemeltető |
| { | Üzemeltető |
| int | kulcsszó |
| a | azonosító |
| , | Üzemeltető |
| b | azonosító |
| ; | Üzemeltető |
| a | azonosító |
| = | hozzárendelési szimbólum |
| 10 | 10(szám) |
| ; | Üzemeltető |
| return | kulcsszó |
| 0 | 0(szám) |
| ; | Üzemeltető |
| } | Üzemeltető |
nem tokenek
| Típus | tokenek |
|---|---|
| előfeldolgozó irányelv | #include<iostream> |
| megjegyzés | / / példa |
a lexikai elemzés folyamata két szakaszból áll.
- szkennelés – Ez magában foglalja a bemeneti karakterek olvasását, valamint a fehér terek és a Megjegyzések eltávolítását.
- tokenizálás-ez a tokenek előállítása kimenetként.
a lexikális elemző architektúrája
a lexikális elemző fő feladata a teljes forrásprogram beolvasása és a tokenek egyesével történő azonosítása.
a szkennerek az elemző kérésére tokenek előállítására kerülnek végrehajtásra.

lépések:
- “get next token” kerül elküldésre az értelmező a lexikai elemző.
- a lexikális analizátor addig vizsgálja a bemenetet, amíg a “következő token” meg nem található.
- a token visszakerül az elemzőhöz.
reguláris kifejezések
reguláris kifejezéseket használunk véges nyelvek kifejezésére a véges szimbólumok mintáinak meghatározásával.
a reguláris kifejezések által meghatározott nyelvtant reguláris nyelvnek, a reguláris nyelvtant pedig reguláris nyelvnek nevezik.
vannak olyan algebrai szabályok, amelyeket a reguláris kifejezések betartanak, amelyeket a reguláris kifejezések ekvivalens formákká történő manipulálására használnak.
műveletek.
az A és B nyelv egyesülése
a U B = {s | s van A-ban vagy s Van B-ben}
két nyelv összefűzése A és B van írva
AB = {SS | s van a-ban és s Van B-ben}
az a nyelv kleen lezárása
A* = ami nulla vagy több előfordulás az a nyelvben.
jelölések.
ha x és y reguláris kifejezések, amelyek az a(x) és B(y) nyelveket jelölik, akkor;
(x) egy reguláris kifejezés, amely az A(x) nyelvet jelöli.
Unió (x) / (y) egy reguláris kifejezés, amely a(x) B (y).
összefűzés (x) (y)egy reguláris kifejezés, amely a(x) b (y).
Kleen lezárás (x)* egy reguláris kifejezés, amely (a(x))*
Precedenciát és asszociativitást jelöl.
*’ összefűzés .’és / (pipe) balra asszociatív.
Kleen bezárása * van a legmagasabb elsőbbséget.
összefűzés (.) elsőbbséget élvez.
(cső) / a legalacsonyabb elsőbbséggel rendelkezik.
egy nyelv érvényes tokenjeinek ábrázolása reguláris kifejezésekben.
X egy reguláris kifejezés, ezért;
- x * jelentése nulla vagy több előfordulása x.
- x + jelentése egy vagy több előfordulása x, azaz{x, xx, xxx}
- x? legfeljebb egy előfordulást képvisel x ie {x}
- az összes kisbetűs ábécét képviseli az angol nyelven.
- az összes nagybetűs ábécét képviseli az angol nyelven.
- az összes természetes számot képviseli.
szimbólumok előfordulásának ábrázolása reguláris kifejezésekkel
Letter = vagy
Digit = vagy|0|1|2|3|4|5|6|7|8|9
Sign =
nyelvi tokenek ábrázolása reguláris kifejezések használatával.
decimális = (jel)?(digit)+
Identifier = (letter) (letter | digit)*
véges automaták
ez az öt sor (Q, Adapterek, Q0, qf, stb.) kombinációja, amely az állapotokra és a bemeneti szimbólumokon keresztüli átmenetekre összpontosít.
felismeri a mintákat azáltal, hogy beviszi a karakterláncot bemenetként, és ennek megfelelően megváltoztatja annak állapotát.
a véges automaták matematikai modellje a következőkből áll;
- véges halmaza Államok (Q)
- véges halmaza bemeneti szimbólumok(Xhamsteren)
- egy kezdőállam (q0)
- véges állapotok halmaza (qf)
- Átmeneti függvény(xhamsteren)
a véges automatákat a lexikális elemzésben használják a tokenek előállítására azonosítók, kulcsszavak és állandók formájában a bemeneti programból.
véges automata táplálja a reguláris kifejezés karakterláncot, és az állapot minden literálnál megváltozik.
ha a bemenet feldolgozása sikeres,az automata eléri a végső állapotot, és elfogadásra kerül, ellenkező esetben elutasításra kerül.
véges automaták felépítése
legyen L(r) szabályos nyelv néhány véges automata által F(A).
ezért;
- Államok: a Körök a fá állapotait képviselik, nevük pedig a körökbe van írva.
- indítási állapot: ez az az állapot, amelyen az automata elindul. Ez lesz egy nyíl felé mutat.
- köztes állapotok: ezeknek két nyílja van, az egyik rá mutat, a másik pedig a köztes állapotokra mutat.
- Végső Állapot: Az automaták várhatóan a végső állapotban lesznek, amikor a bemeneti karakterláncot sikeresen elemezték, és kettős körökkel ábrázolták, különben a bemenet elutasításra kerül. Tartalmazhat páratlan számú nyilat, amely felé mutat, és egy páros számot, amely arra mutat, azaz
páratlan nyilak = páros nyilak + 1. - átmenet: ha a kívánt szimbólum megtalálható a bemenetben, az egyik állapotból a másikba való átmenet megtörténik. Az automata vagy a következő állapotba lép, vagy továbbra is fennáll.
egy irányított nyíl mutatja az egyik állapotból a másikba történő mozgást, miközben egy nyíl a célállapot felé mutat.
ha az automata ugyanabban az állapotban marad, akkor egy állapotból önmagára mutató nyíl rajzolódik ki.
egy példa; Tegyük fel, hogy egy 3 jegyű bináris érték végződő 1 által elfogadott FA.
akkor FA = {Q (q0, qf), Ca (0,1), q0, QF, CA (6)}
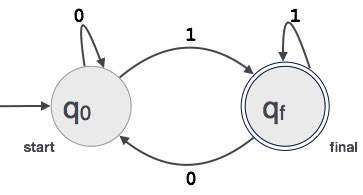
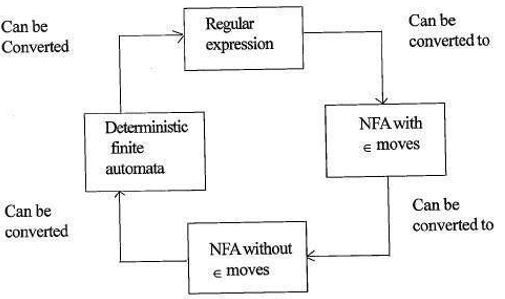
a reguláris kifejezések és a véges automaták közötti kapcsolat
a reguláris kifejezések és a véges automaták közötti kapcsolat a következő;
az alábbi ábra azt mutatja, hogy könnyen átalakítható;
- reguláris kifejezések nem determinisztikus véges automaták(NFA) val vel 6.
- a Nem-determinisztikus véges automaták a ∈ mozog nélkül ∈ mozog
- a Nem-determinisztikus véges automaták nélkül ∈ mozog, hogy Determinisztikus Véges Automaták(DFA).
- determinisztikus véges automaták a reguláris kifejezéshez.
a Lex elfogadja a reguláris kifejezéseket bemenetként, és visszaad egy programot, amely egy véges automatát szimulál a reguláris kifejezések felismerésére.
ezért a lex kombinálja a string pattern generation-t (reguláris kifejezések, amelyek meghatározzák az érdekes karakterláncokat a lex számára) és a string pattern recognition-t (egy véges automata, amely felismeri az érdekes karakterláncokat).
leghosszabb egyezési szabály
kimondja, hogy a beolvasott lexémát az összes rendelkezésre álló token közül a leghosszabb egyezés alapján kell meghatározni.
ez a kétértelműségek feloldására szolgál, amikor eldönti a következő tokent a bemeneti adatfolyamban.
a forráskód elemzése során a lexikális elemző betűről betűre vizsgálja a kódot, és amikor operátort, speciális szimbólumot vagy szóközt észlel, eldönti, hogy egy szó teljes-e.
példa:
int intvalue;a fentiek beolvasása közben az elemző nem tudja meghatározni, hogy az’ int ‘ kulcsszó int vagy az intvalue azonosító előtagja.
Szabályprioritást alkalmaznak, amelynek során egy kulcsszó elsőbbséget kap a felhasználói bevitellel szemben, ami azt jelenti, hogy a fenti példában az elemző hibát generál.
lexikai hibák
lexikai hiba akkor fordul elő, ha egy karaktersorozatot nem lehet érvényes tokenbe beolvasni.
ezeket a hibákat az azonosítók, kulcsszavak VAGY operátorok elírása okozhatja.
általában, bár nagyon ritka lexikai hibákat a token illegális karakterei okoznak.
hibák lehetnek;
- helyesírási hiba.
- két karakter átültetése.
- illegális karakterek.
- meghaladja az azonosító vagy numerikus állandók hosszát.
- karakter cseréje helytelen karakterrel
- egy karakter eltávolítása, amelynek jelen kell lennie.
hibajavítás jár;
- egy karakter eltávolítása a fennmaradó bemenetből
- két szomszédos karakter átültetése
- egy karakter törlése a fennmaradó bemenetből
- hiányzó karakter beszúrása a fennmaradó bemenetbe
- egy karakter cseréje egy másik karakterrel.
- Az egymást követő karakterek figyelmen kívül hagyása, amíg jogi token nem jön létre(pánik mód helyreállítása).
hiba helyreállítási rendszerek
Pánik mód helyreállítása.
ebben a hibajavítási sémában a páratlan minták törlődnek a fennmaradó bemenetről, amíg a lexikális analizátor nem talál egy jól kialakított tokent a fennmaradó bemenet elején.
a könnyebb megvalósítás előnye ennek a megközelítésnek.
azzal a korlátozással rendelkezik, hogy nagy mennyiségű bemenetet kihagynak anélkül, hogy ellenőriznék a további hibákat.
Helyi Korrekció.
ha hibát észlel egy pont beillesztése / törlése és / vagy csere műveleteket hajtanak végre, amíg egy jól formázott szöveget el nem érjük.
az analizátor újraindul az eredményül kapott új szöveg bevitelével.
globális korrekció.
ez egy továbbfejlesztett pánik mód hasznosítás előnyös, ha a helyi javítás nem sikerül.
magas idő – és térigénye van, ezért gyakorlatilag nem valósul meg.
lexikai analizátorok szükségessége
- javított fordító hatékonyság – a karakterek olvasására szolgáló speciális pufferelési technikák felgyorsítják a fordító folyamatát.
- a fordító tervezésének egyszerűsége – a szóközök és megjegyzések eltávolítása hatékony szintaktikai konstrukciókat tesz lehetővé a szintaxis analizátor számára.
- fordítóprogram hordozhatósága – csak a szkenner kommunikál a külvilággal.
- specializáció – speciális technikák használhatók a lexikális elemzési folyamat javítására
lexikális elemzéssel kapcsolatos problémák
- Lookahead
adott bemeneti karakterlánc, a karakterek egyenként olvashatók balról jobbra.
annak megállapításához, hogy egy token elkészült-e vagy sem, meg kell vizsgálnunk a következő karaktert.
példa: ‘= ‘ egy hozzárendelési operátor vagy az ‘==’ operátor első karaktere.
a Lookahead kihagyja a karaktereket a bemenetben, amíg egy jól formált tokent nem talál, ez azt mutatja, hogy a look ahead nem képes jelentős hibákat elkapni, kivéve az egyszerű hibákat, például az illegális szimbólumokat. - kétértelműségek
a lex-szel írt programok elfogadják a kétértelmű specifikációkat, ezért a leghosszabb egyezést választják, és ha több kifejezés egyezik a bemenettel, akkor a leghosszabb egyezést részesítik előnyben, vagy az egyeztetési szabályok közül az első szabályt részesítik előnyben. - fenntartott kulcsszavak
bizonyos nyelvekben vannak olyan fenntartott szavak, amelyek más programozási nyelvekben nincsenek fenntartva, pl. az elif a Pythonban fenntartott szó, de a C-ben nem. - Kontextusfüggőség
példa:
A do 10 l = 10.86 állítást figyelembe véve a DO10l azonosító, a DO nem kulcsszó.
és mivel az állítás DO 10 l = 10, 86, DO egy kulcsszó
az ilyen állítások lenne szükség jelentős előretekintés A felbontás.
Alkalmazások
- által használt fordítóprogramok létre megfelelt bináris futtatható elemzett kódot.
- a webböngészők HTML, CSS és java szkriptet tartalmazó weblap formázására és megjelenítésére használják.
ezzel a cikkel a OpenGenus, akkor kell egy erős ötlet lexikai elemzés Fordító tervezés.