この記事では、高レベルの入力プログラムがトークンのシーケンスに変換されるコンパイラ設計の最初の段階につ このフェーズは、コンパイラ設計における字句解析として知られています。
目次:
- 字句解析の定義
- 字句解析の例
- 字句解析のアーキテクチャ
- 正規表現
- 有限オートマトン
- 正規表現と有限オートマトンの関係
- 最長一致ルール
- 字句エラー
- エラー回復スキーム
- 字句解析の必要性
- 字句解析の必要性
字句解析は、入力として取られたソースプログラムから一連の文字をトークンのシーケンスに変換するプロセスです。
lexは字句解析器を生成するプログラムです。
字句解析器/字句解析器/スキャナは、字句解析を行うプログラムです。
字句解析器の役割は次のとおりです;
- ソースプログラムからの入力文字の読み取り。
- エラーメッセージとソースプログラムとの相関。
- ソースプログラムからの空白とコメントをストライピングします。
- ソースプログラムに展開マクロが見つかった場合。
- 識別されたトークンをシンボルテーブルに入力します。
字句は、トークンのインスタンス、つまり、トークンの一致パターンに従ってソースプログラムに含まれる一連の文字です。
式が与えられた例;
c=a+b*5
レクセムとトークンは次のとおりです;
| レキセムス | トークン |
|---|---|
| c | 識別子 |
| = | 割り当て記号 |
| a | 識別子 |
| + | +(加算記号) |
| b | 識別子 |
| * | *(乗算記号) |
| 5 | 5(番号) |
字句解析器によって生成されるトークンのシーケンスにより、パーサーは次の構文を分析できます。 プログラミング言語。
トークンは、字句によって与えられる有効な文字列であり、プログラミング言語の文法では単位として扱われます。
プログラミング言語では、これには次のものが含まれます;
- キーワード
- 演算子
- 句読点記号
- 定数
- 識別子
- 数字
パターンは、トークンで使用される一連の文字(語彙)に一致するルールです。 これは、正規表現または文法規則によって定義できます。
字句解析の一例
コード
#include<iostream>// exampleint main(){ int a, b; a = 7; return 0;}トークン
| レキセムス | トークン |
|---|---|
| int | キーワード |
| メイン | キーワード |
| ( | 演算子 |
| ) | 演算子 |
| { | 演算子 |
| int | キーワード |
| a | 識別子 |
| , | 演算子 |
| b<6201> | |
| ; | 演算子 |
| a | 識別子 |
| = | 割り当て記号 |
| 10 | 10(番号) |
| ; | 演算子 |
| 戻る | キーワード |
| 0 | 0(番号) |
| ; | |
| } | 演算子 |
非トークン
| タイプ | |
|---|---|
| プリプロセッサディレクティブ | #include<iostream> |
| コメント | //例 |
字句解析のプロセスは2つの段階で構成されています。
- スキャン-これには、入力文字の読み取りと空白とコメントの削除が含まれます。
- トークン化-これは出力としてのトークンの生成です。
字句解析器のアーキテクチャ
字句解析器の主なタスクは、ソースプログラム全体をスキャンし、トークンを一つずつ識別することです。
スキャナは、パーサーによって要求されたときにトークンを生成するように実装され

ステップ:
- “get next token”は、パーサから字句解析器に送信されます。
- 字句解析器は、”次のトークン”が見つかるまで入力をスキャンします。
- トークンがパーサーに返されます。
正規表現
有限のシンボルセットのパターンを定義することによって、有限の言語を表現するために正規表現を使用します。
正規表現で定義された文法は正規文法と呼ばれ、正規文法で定義された言語は正規言語と呼ばれます。
正規表現を同等の形式に操作するために使用される正規表現に従う代数規則があります。
二つの言語AとBの和集合は
A U B={s|sはAまたはsはBにあります}
二つの言語AとBの連結は
AB={ss|sはAにあり、sはBにあります}
言語Aのkleenクロージャは
a*=と書かれています。
表記。
xとyが言語A(x)とB(y)を表す正規表現であれば、
(x)はA(x)を表す正規表現です。
Union(x)|(y)は、A(x)B(y)を表す正規表現です。
連結(x)(y)は、a(X)B(y)を凹ませる正規表現です。
Kleen closure(x)*は、(A(x))*
の優先順位と結合性を示す正規表現です。
*’連結。’と/(パイプ)は左結合です。
Kleen closure*は最も高い優先順位を持ちます。
)が優先されます。
(パイプ)|の優先順位が最も低くなります。
正規表現で言語の有効なトークンを表します。
Xは正規表現であるため、;
- x*はxのゼロ以上の出現を表します。
- x+はxの1つ以上の出現を表します。{x,xx,xxx}
- x? {x}
- は、英語のすべての小文字のアルファベットを表します。
- は、英語のすべての大文字のアルファベットを表します。
- はすべての自然数を表す。
正規表現を使用してシンボルの出現を表す
Letter=または
Digit=または|0|1|2|3|4|5|6|7|8|9
Sign=
は、正規表現を使用して言語トークンを表します。
(digit)+
Identifier=(letter)(letter|digit)*
有限オートマトン
これは、入力シンボルを介した状態と遷移に焦点を当てた五つのタプル(Q,Π,q0,qf,δ)の組み合わせです。
シンボルの文字列を入力としてパターンを認識し、それに応じて状態を変更します。
有限オートマトンの数学モデルは以下のもので構成される;
- 状態の有限集合(Q)
- 入力シンボルの有限集合(Λ)
- 一つの開始状態(q0)
- 最終状態の集合(qf)
- 遷移関数(δ)
- 遷移関数(δ)
- 遷移関数(δ)
- 遷移関数(δ)
- 遷移関数(δ)
- 遷移関数(δ)
- 遷移関数(δ))
有限オートマトンは、入力プログラムから識別子、キーワード、定数の形式でトークンを生成するために字句解析で使用されます。
有限オートマトンは正規表現文字列を供給し、リテラルごとに状態が変更されます。
入力が正常に処理された場合、オートマトンは最終状態に達し、それ以外の場合は拒否されます。
有限オートマトンの構築
L(r)をある有限オートマトンF(A)による正規言語とする。
;
- 状態:円はFAの状態を表し、その名前は円の内側に書かれています。
- 開始状態:オートマトンが開始する状態です。 それはそれを指す矢印を持つことになります。
- 中間状態:これらには2つの矢印があり、1つはそれを指し、もう1つは中間状態を指しています。
- 最終状態: 入力文字列が正常に解析され、それ以外の場合は入力が拒否されると、オートマトンは最終状態になることが期待されます。 奇数の矢印と偶数の矢印、つまり
odd arrows=even arrows+1が含まれていてもよい。 - 遷移:入力に目的のシンボルが見つかった場合、ある状態から別の状態への遷移が起こります。 オートマトンは、次の状態に移動するか、または持続します。
有向矢印は、ある状態から別の状態への移動を表示し、矢印は目的地の状態に向かって指します。
オートマトンが同じ状態のままであれば、状態からそれ自身を指す矢印が描画されます。
例;1で終わる3桁のバイナリ値がFAによって受け入れられると仮定します。
このとき、FA={Q(q0,qf),√(0,1),q0,qf,δ}
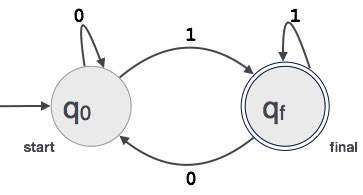
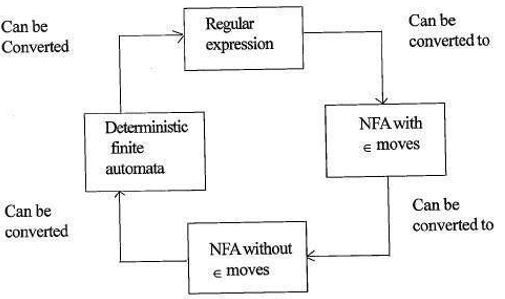
正規表現と有限オートマトンの関係
正規表現と有限オートマトンの関係は次のとおりです;
以下の図は、変換が容易であることを示しています;
- 非決定論的有限オートマトン(NFA)への正規表現。
- 非決定論的有限オートマトンがσなしに移動する
- 非決定論的有限オートマトンがΣなしに移動する
- 非決定論的有限オートマトンが決定論的有限オートマトン(DFA)に移動する。
- 正規表現への決定論的有限オートマトン。
Lexは正規表現を入力として受け入れ、正規表現を認識するために有限オートマトンをシミュレートするプログラムを返します。
したがって、lexは文字列パターン生成(対象の文字列をlexに定義する正規表現)と文字列パターン認識(対象の文字列を認識する有限オートマトン)を結合します。
最長一致ルール
スキャンされた字句は、利用可能なすべてのトークンの中で最も長い一致に基づいて決定されるべきであると述べています。
これは、入力ストリーム内の次のトークンを決定するときのあいまいさを解決するために使用されます。
ソースコードの分析中、字句解析器は文字ごとにコードをスキャンし、演算子、特殊記号、または空白が検出されると、単語が完全であるかどうかを決定します。
:
int intvalue;上記のスキャン中、アナライザは’int’がキーワードintであるか、識別子intvalueの接頭辞であるかを判断できません。
ルールの優先度が適用され、キーワードがユーザー入力よりも優先されます。
字句エラー
文字シーケンスを有効なトークンにスキャンできない場合に字句エラーが発生します。
これらのエラーは、識別子、キーワード、演算子のスペルミスが原因で発生する可能性があります。
一般的に、非常に珍しい字句エラーは、トークン内の不正な文字によって引き起こされます。
エラーは次のようになります;
- スペルミス。
- 二つの文字の転置。
- 不正な文字。
- 識別子または数値定数の長さを超えています。
- 正しくない文字での文字の置換
- 存在する必要がある文字の削除。
;
- 残りの入力から一つの文字を削除する
- 隣接する二つの文字を転置する
- 残りの入力から一つの文字を削除する
- 残りの入力に欠けている文字を挿入する
- 文字を別の文字に置き換える。
- 正当なトークンが形成されるまで連続した文字を無視します(パニックモードの回復)。
エラー回復スキーム
パニックモード回復。
このエラー回復スキームでは、字句解析器が残りの入力の先頭に整形式のトークンを見つけるまで、残りの入力から不一致のパターンが削除されます。
実装が容易であることは、このアプローチの利点である。
追加のエラーをチェックせずに大量の入力をスキップするという制限があります。
ローカル修正。
ある時点でエラーが検出された場合、整形式のテキストが達成されるまで、挿入/削除および/または置換操作が実行されます。
結果の新しいテキストを入力として、アナライザが再起動されます。
グローバル補正。
ローカル修正が失敗した場合に優先される拡張パニックモード回復です。
それは高い時間とスペースの要件を持っているので、それは実用的に実装されていません。
字句アナライザの必要性
- コンパイラの効率の向上-文字を読み取るための特殊なバッファリング技術により、コンパイラのプロセスが高速化され
- コンパイラ設計のシンプルさ-空白とコメントを削除すると、シンタックスアナライザの効率的な構文構造が可能になります。
- コンパイラの移植性-スキャナのみが外部の世界と通信します。
- 特殊化-特殊化された技術を使用して、字句解析プロセスを改善することができます
字句解析の問題
- 先読み
入力文字列を指定すると、文字は左から右に一つずつ読み込まれます。
トークンが終了したかどうかを判断するには、次の文字を調べる必要があります。
例:’=’は代入演算子または’==’演算子の最初の文字ですか。
先読みは整形式のトークンが見つかるまで入力内の文字をスキップしますが、これは先読みが不正なシンボルなどの単純なエラーを除いて重大なエ - Ambiguities
lexで書かれたプログラムはあいまいな仕様を受け入れるため、最長の一致を選択し、複数の式が入力に一致する場合は、最長の一致が優先されるか、一致ルールの中で最初のルールが優先されます。 - 予約キーワード
特定の言語には、他のプログラミング言語では予約されていない予約語があります。elifはpythonでは予約語ですが、Cでは予約語ではありません。 - コンテキスト依存関係
例:
ステートメントDO10l=10.86を指定すると、Do10Lは識別子であり、doはキーワードではありません。
そして、文DO10l=10,86を考えると、DOはキーワード
そのような文は、解決のためにかなりの先読みを必要とするでしょう。
アプリケーション
- コンパイラによって使用される解析されたコードから準拠したバイナリ実行可能ファイルを作成します。
- html、CSS、javaスクリプトを解析されたwebページをフォーマットして表示するためにwebブラウザで使用されます。
OpenGenusのこの記事では、コンパイラ設計における字句解析の強力なアイデアを持っている必要があります。