クラウド、ハイブリッドIT、仮想化、ストレージエリアネットワークなどで構成される複雑なネットワークでは、多面的なIT問題を特定して診断することが困難な場合があります。 たとえば、パフォーマンスの悪いアプリケーションやサーバーなどの問題が表面化した場合、調査には重要な問題の特定にかなりの時間がかか 問題は、ストレージ、ネットワーク接続、ユーザーアクセス、またはリソースと構成の混在にある可能性があります。
この問題を調査するには、パフォーマンス分析(PerfStack™)ダッシュボードを使用してトラブルシューティングプロジェクトを作成し、複数のSolarWinds製品とエンティティ
パフォーマンス分析ダッシュボードでは、次の操作を実行できます:
- ステータス、イベント、統計など、複数の指標タイプを単一のビューで比較および分析します。
- ノード、インターフェイス、ボリューム、アプリケーションなど、複数のエンティティのメトリックを単一のビューで比較および分析します。
- Orionプラットフォーム全体からのデータを単一の共有タイムラインで相関させます。
- オンプレミス、クラウド、およびその間のすべてのハイブリッドデータを視覚化します。
- 問題の履歴データを確認するために、チームや専門家とトラブルシューティングプロジェクトを共有します。
VMANの場合、アプリケーション分析やハイブリッド環境の可能性は無限大です:
- 環境内のVmの履歴データを視覚的に調べる
- ハイブリッド環境でのリソース割り当ての問題を確認する
- 仮想サーバー(ホスト、クラスター、データストア、およびVm)、オンプレミスサーバー、およびクラウドインスタンスによって送受信されるネットワークトラフィックをトラブルシューティングするためのデータの相関
次の例は、VMのパフォーマンスが発生する根本原因を特定する方法を示しています問題。 このシナリオでは、仮想ホストでリソースとパフォーマンスの問題が発生し、ユーザーの応答とアクセスが遅くなります。 この問題はアラートをトリガーし、アプリケーション所有者に通知し、システム管理者とネットワーク管理者に問題をエスカレートさせました。
新しいトラブルシューティングプロジェクトを作成して問題を調査し、ホストと関連するすべての仮想環境システムのメトリックを比較して、使用
-
Orion Webコンソールで、マイダッシュボード>ホーム>パフォーマンス分析を選択します。
これにより、パフォーマンス分析またはPerfStackダッシュボードが開き、メトリックパレットで監視対象のアプリケーションおよびサーバーから取得されたメトリッ 各グラフには複数の指標を保持して、データを直接相関させることができます。
-
新しい分析プロジェクトで、エンティティの追加をクリックします。
開始するには、困っているVMを見つけて追加する必要があります。 検索フィールドにsydと入力すると、その名前を共有する仮想サーバーのリストが表示されます。 必要に応じて、[タイプ]または[ステータス]を展開して選択し、リストをフィルタリングします。
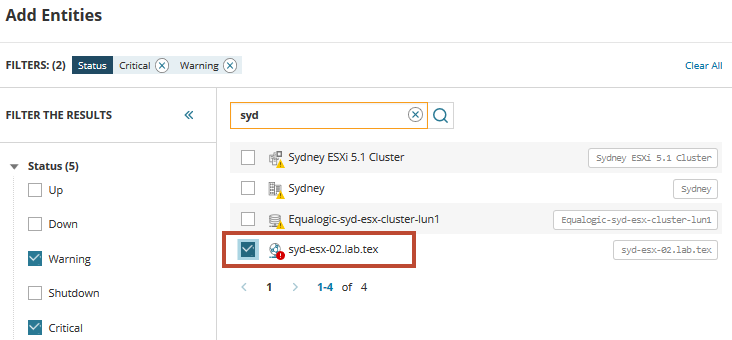
リストから、仮想ホストが問題に遭遇し、アラートをトリガーしていることがわかります。 ホストを選択し、ダッシュボードメトリックパレットに追加します。 Related entitiesアイコンをクリックすると、ホストに関連するすべてのサーバーとサービスが表示されます。
この選択したノードに関連するすべてのノード、アプリケーション、サーバーなどに興味がありますか? 関連する図形アイコンをクリックします。
 関連するすべてのエンティティがメトリックパレットに表示され、問題の原因となる可能性のあるメトリックオプ
関連するすべてのエンティティがメトリックパレットに表示され、問題の原因となる可能性のあるメトリックオプ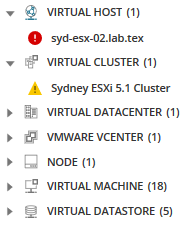
-
表示するsydホストノードを選択し、ダッシュボードにドラッグアンドドロップするメトリックを選択します。 それらを同じグラフにドラッグして、指標間の値を比較することができます。
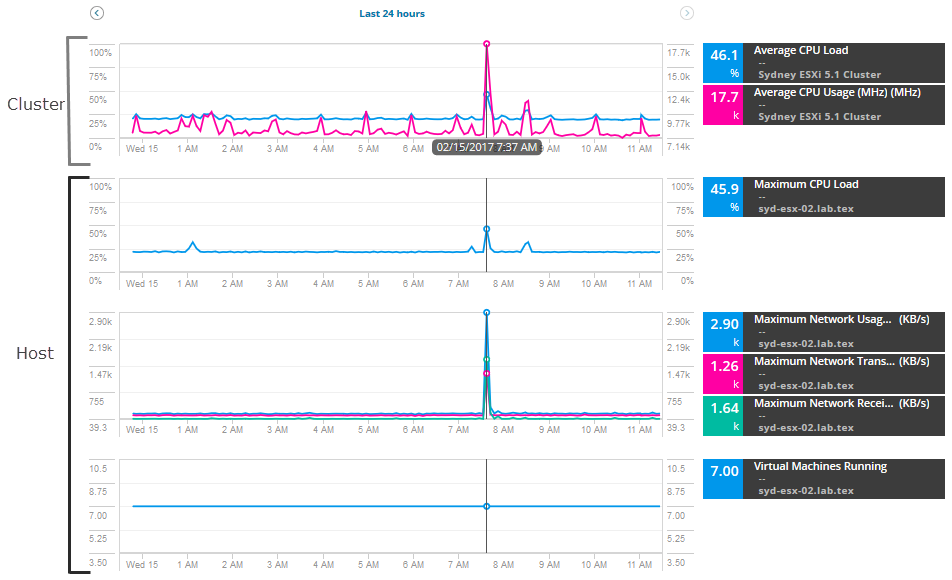
調査を開始するには、ホストとクラスターの一連のメトリックをプルし、メトリックを比較してスパイクや使用率の高いものを見つけます。 このシナリオでは、次のホストメトリクスを追加します:
- 最大ネットワーク使用量
- 最大ネットワーク送信レート
- 最大ネットワーク受信レート
- 実行中の仮想マシン
クラスターに対して、次のメトリッ:
- 平均CPU負荷
- 平均CPU使用率
チャートとグラフには、過去12時間のメトリックのデータとアラートが表示されます。 日付と時刻を展開して、アラートの過程で追加の履歴指標を表示することができます。
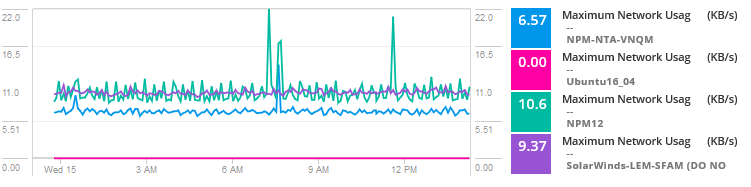
ホスト上のVmの使用状況指標を追加して、ネットワークの使用状況とアクティビティを比較します。
-
データを分析すると、この問題は、リソースを消費し、ホストを共有するVmのボトルネックや問題を引き起こす高トラフィックを経験する仮想マシンのい 基本的に、別のサーバー、サービス、またはアプリケーションは、より高い帯域幅、ディスクI/O、CPU、およびこの特定のアプリケーションの問題を引き起こす他のリソー
この情報は、ネットワーク管理者とシステム管理者に、遅延の問題をさらに調査して解決するための方向性を提供します。 解決するために、リソースを再割り当てしたり、高消費のアプリケーションを別の場所に移動したりできます。
-
“保存”をクリックし、プロジェクトに名前を付けます。
プロジェクトは、設定された日付と時刻の範囲で選択された指標をダッシュボードとして保存します。
保存すると、URLは共有可能なリンクになります。 システム管理者およびネットワーク管理者および製品所有者から送信されたチケットまたは電子メールで、保存されたダッシュボードへのリンクをコピーして共有します。 このリンクにアクセスして、収集されたデータを確認し、トラブルシューティングを実行できます。
リソースを再割り当てしてネットワークを変更した後、ダッシュボードを再度開き、ポーリングされたメトリックの変更と新しい使用傾向を確認します。