この記事は、データサイエンスBlogathonの一部として公開されました。
“世界最大の宗教は宗教でさえありません。”-フェルナンド-トーレス
はじめに
サッカーはすべてに愛され、その美しさは予測不可能な性質にあります。 強くこのゲームに関連付けられていることの一つは、そのファンであります,陰気とゲームに勝つ人の上にゲームの前に議論. そして、一部のファンは試合前にスコアラインを推測する限界に行くことさえあります。 それでは、これらの質問のいくつかに論理的に答えようとしましょう。
ポアソンを知る
まあ、私は以前のサッカーは予測不可能なゲームであると言ったように、目標は、以前の目標やチームやその他の要因に依存しない完全に無作為に試合中の任意の時点で発生する可能性があります。 待って私は”ランダム”と言いました。 ランダムに発生するイベントの確率を見つけるために使用される統計に分布があるため、ポアソン分布。
あなたの友人がゲームごとに平均2ゴールが起こると言っているとしますが、彼は正しいですか? 右の場合は、試合で二つのゴールを見ての実際のチャンスは何ですか? ここでは、発生するイベント(期間ごとの平均イベント)の期待を提供することを考えると、一定期間内に”n”イベント(”n”ゴールを読む)を観察する確率を見つ 一度数学的に見てみましょう
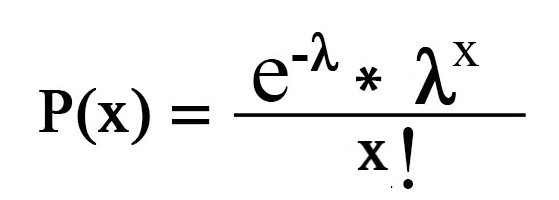
(ここで、ε=期間ごとの平均イベント)
得点の可能性
さて、この式でいくつかの質問に答えましょうが、最初にデータが必要なので、このために1872年から2020年までの国際サッカーの結果をKaggleからダウンロードしました。 私たちのデータセットのサンプルを以下に示します。
:
data.head(3)
.png)
90分以内に期待できる平均的な目標を見つけることから始めましょう。このために、21世紀(2000-2020)でプレイされた試合のデータをフィルタリングする別のデータセットを作成し、home_scoreとaway_scoreを追加して合計番号を確認しました。 各試合で発生したゴールの平均値を取得し、合計ゴール列の平均値を取得して、試合で期待できる平均ゴールを取得します。
:
data=data+datadata=data.apply(lambda x : int(str.split(x,'-')))rec_data=data.loc>=2000)]rec_data.iloc]print(rec_data.total_goals.mean())
2.744112130054189
さて、この期待をPoissson分布式に入れて、試合で3ゴールを見る実際の可能性は何かを見てみましょう。
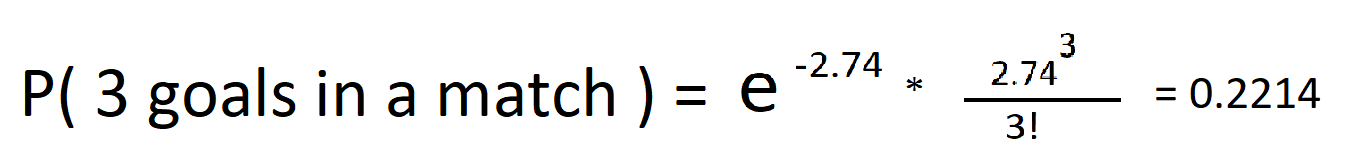
うわー、わずか22%のチャンスです。 いいえの確率をプロットしてみましょう。 より良い画像を取得するために試合での目標の。
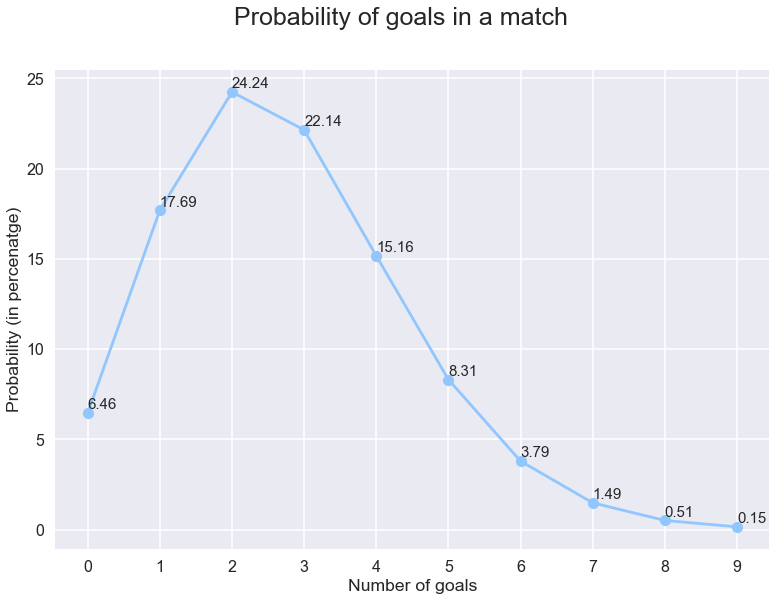
これから、’x’の確率と’x’より小さい数値を追加するだけで、’x’以下のゴール数を見る確率を計算することができます。そして、これを1から減算するだけで、試合で’x’以上のゴールを見る確率を得ることができます。 これもプロットしましょう。
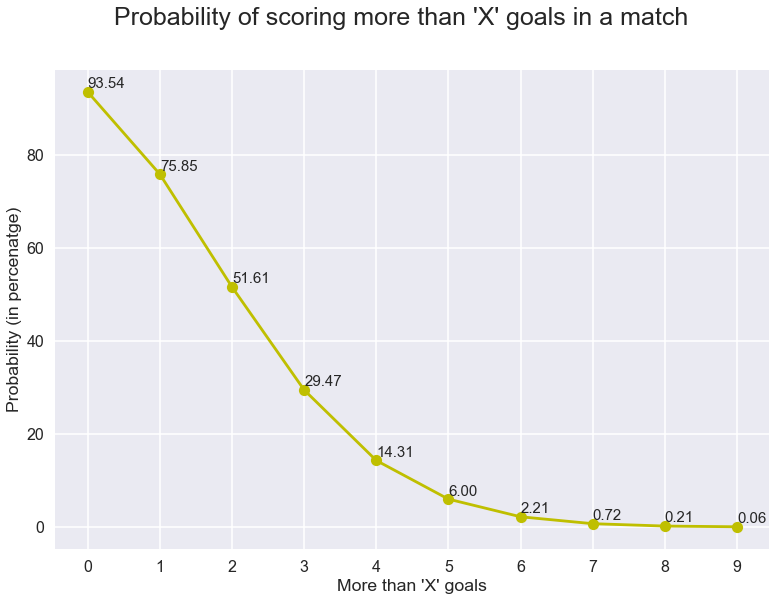
待ちは終わった…
今、あなたはゲーム全体のために座ってしたくないせっかちな友人を持っていると仮定します。 そして、彼は試合中にあなたに来て、彼はゴールを見るのを待たなければならないどのくらいの時間を尋ねます。 Woah、それは右の厳しい質問ですが、心配しないで、10000ゲームを介して座って、各目標の間の時間に注意するように彼に依頼してください。 冗談だ、明らかに、彼はフリークアウトだろう。 実際に私は10000試合をシミュレートし、平均時間を見つけました。
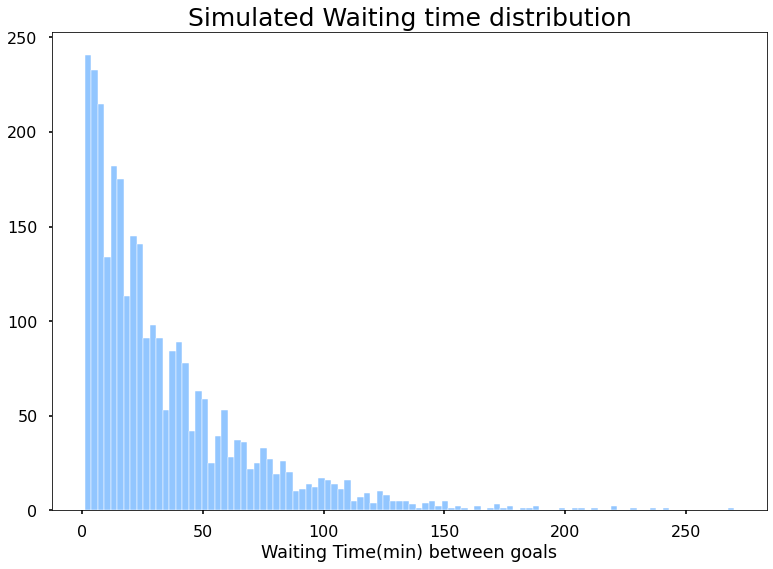
最も可能性の高い待ち時間は2分です。 しかし、これは実際に私が探していたものではなく、私はランダムな時間にゲームを見始めるとゴールを見るのを待たなければならない平均時間が欲しい。 各インスタンスが10000ゲームを見ており、その10000ゲームのゴール間の平均待ち時間を計算して報告している10000インスタンスを取ります。 最後に、私は私のインスタンスのそれぞれからそれらの10000のレポートをプロットし、予想される平均待ち時間を見つけることになります。
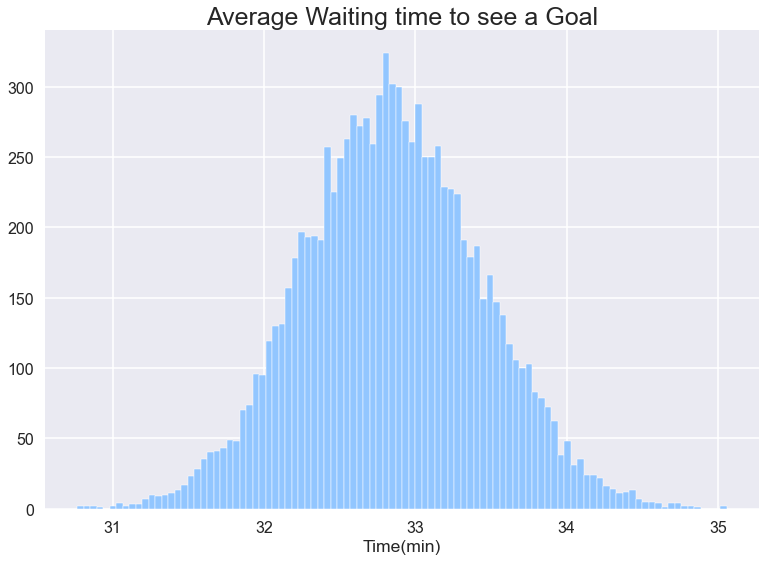
約33分待たなければならないようです。 しかし、私たちはより多くを待たなければならないかもしれません、これは古典的な待ち時間パラドックスです。
スコアラインの予測
最後に、私たちが始めた質問と、誰が勝つのか、正確にはどのようなスコアラインになるのかという最も刺激的な質問をしましょう。
このために、2つのチーム間の履歴を使用し(ホームチームとアウェイチームと考えてみましょう)、average_home_scoreをホームチームの期待目標として、average_away_scoreをアウェーチームの チーム間の出会いが少ない場合は、いくつかの要因
HS=歴史を通じてホームチームが得点したホームゴールの平均を考慮します。
AS=歴史を通じてアウェイチームが得点したアウェイゴールの平均。
HC=ホームチームがホーム試合で失点したゴールの平均。
AC=アウェイチームがアウェイ試合で失点したゴールの平均。
だから、ホームチームの期待スコアは次のように計算されます(HS+AC)/2
だから、アウェイチームの期待スコアは次のように計算されます(AS+HC)/2
待って、期待スコアは予測スコアではありません。 期待されるスコアは、それらの間のゲームで得点すると予想されるゴールの平均数です。
:
import pandas as pdimport numpy as npfrom scipy import stats
def PredictScore(): home_team = input("Enter Home Team: ") ht = (''.join(home_team.split())).lower() away_team = input("Enter Away Team: ") at = (''.join(away_team.split())).lower() if len(data) > 20: avg_home_score = data.home_score.mean() avg_away_score = data.away_score.mean() home_goal = int(stats.mode(np.random.poisson(avg_home_score,100000))) away_goal = int(stats.mode(np.random.poisson(avg_away_score,100000))) else: avg_home_goal_conceded = data.away_score.mean() avg_away_goal_scored = data.away_score.mean() away_goal = int(stats.mode(np.random.poisson(1/2*(avg_home_goal_conceded+avg_away_goal_scored),100000))) avg_away_goal_conceded = data.home_score.mean() avg_home_goal_scored = data.home_score.mean() home_goal = int(stats.mode(np.random.poisson(1/2*(avg_away_goal_conceded+avg_home_goal_scored),100000))) avg_total_score = int(stats.mode( np.random.poisson((data.total_goals.mean()),100000))) print(f'Expected total goals are {avg_total_score}') print(f'They have played {len(data)} matches') print(f'The scoreline is {home_team} {home_goal}:{away_goal} {away_team}')
ブラジルをホームチームに、メキシコをアウェイチームにしてみましょう。
:
PredictScore()
.png)
ポアソン分布は、私たちにブラジルが2-0のスコアラインで勝利の予測を与えます。 私はネットを検索し、それらの間の最後の試合が2Jul2018で行われ、スコアラインはブラジルが2-0で勝ったと言います。 まあ、私は幸運だった、あなたはしないかもしれません。
結論
あなたはさらに心配を探求したい場合は、ここに私のコードです。 さらに、これはゲームを予測する単なる基本的な方法であり、今日では分類アルゴリズムが結果を予測するために使用され、回帰アルゴリズムがスコアラインを予測するために使用されています。 しかし、それはそれまでこれで遊んで楽しい時を過す、別の日の話題です。 アディオス!