データベーススナップショ
例によって説明すれば、より明確になります。
たとえば、Adventureworks2014データベースのスナップショットを取得します。 私たちはこのスナップショットを読んでいます。 Adventureworks2014データベースはまだ変更されていません。 私たちの選択は、元のデータベースに変更がないため、元のデータベースに移動します。
元のデータベースで変更が発生した場合、これらの変更はスナップショット用のディスク上の専用スペース(スパースファイルと呼ばれます)に書き込まれ
データを読みたいとき、元のデータベースでデータが変更されている場合、データの変更されていないバージョンがスパースファイルから読み込まれます。 このようにして、写真はそのままになります。
スナップショットを取得してもすぐにディスク領域を占有しませんが、元のデータベースの変更が増えるにつれてスパースファイルのサイズが増加します。 スパースファイルのサイズが大きくなり、ディスクにスペースが残っていない場合は、スナップショットが疑わしいものになるため、スナップショッ
主にミラーリング技術で使用されています。
私の記事”SQL Server上のデータベースミラーリング”を読むことをお勧めします。 ミラーリングでは、セカンダリデータベースから読み取ることはできません。 セカンダリデータベースから読み取りたい場合は、セカンダリデータベースのスナップショットでこれを行うことができます。
このようにして、セカンダリデータベースからレポートクエリを作成することで、プライマリデータベースのレポートに負担をかけることはありません。
または、バッチ更新または削除操作を実行する前にデータベースのスナップショットを取得できます。 誤った更新または削除操作は、snapshotを使用して元に戻すことができます。 これは、バックアップから戻るよりもはるかに高速な方法です。
Snapshotはデータベースと同じインスタンス上にある必要があります。
2つの例を続けてみましょう。
最初の例では、ミラー化されたデータベースのセカンダリデータベースから読み取ることができるスナップショットを取得します。
2番目の例では、誤った更新操作を逆にするためにsnapshotを取得します。
例1:
まず、ミラー化されたデータベースは同期である必要があります。 したがって、セカンダリデータベースのイメージは次のようになります。
![]()
次に、次のスクリプトを使用してスナップショットを作成します。 データベース内のすべてのファイルを指定する必要があります。
この例では、2つのファイルがありました。 これら2つのファイルのスナップショットを作成しました。 ファイルグループとファイルに精通していない場合は、私の記事”SQL Serverでデータベースを作成する方法”を読むことができます。
|
1
2
3
4
5
|
データベースAdventureworks2014_Snapshot ON
(NAME=Adventureworks2012_Data,FILENAME=’C:\DB\Data\AdventureWorks2012_Data…..ss’ ),
( 名前=Adventureworks2014_Deneme,ファイル名=’C:\DB\Data\AdventureWorks2014_Deneme…..ss’)
Adventureworks2014のスナップショットとして;
GO
|
私はmsdnから次のスクリプトを手に入れました。
次のスクリプトを使用すると、ディスク上のスナップショットのサイズと、それが拡大できる最大サイズを見つけることができます。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
DB_NAMEを選択します(sd.source_database_id)として、
sd.name として、
mf.name として、
size_on_disk_bytes/1024として、
mf2。サイズ/128として
からsys.master_files mf
SYSを結合します。データベースsd
mfにあります。database_id=sd.database_id
sysを結合します。master_files mf2
をsd上に配置します。source_database_id=mf2.database_id
およびmf。file_id=mf2.file_id
クロス適用sys.dm_io_virtual_file_stats(sd.database_id,mf.ここで、mf.is_sparse=1
およびmf2.is_sparse=0
順に並べ替えます1;
|
スクリプトを実行したときに次の結果セットが返されました。 これら2つのデータファイルのサイズを256mbに設定しました。
そのため、スナップショットは最大256MBに拡張できます。
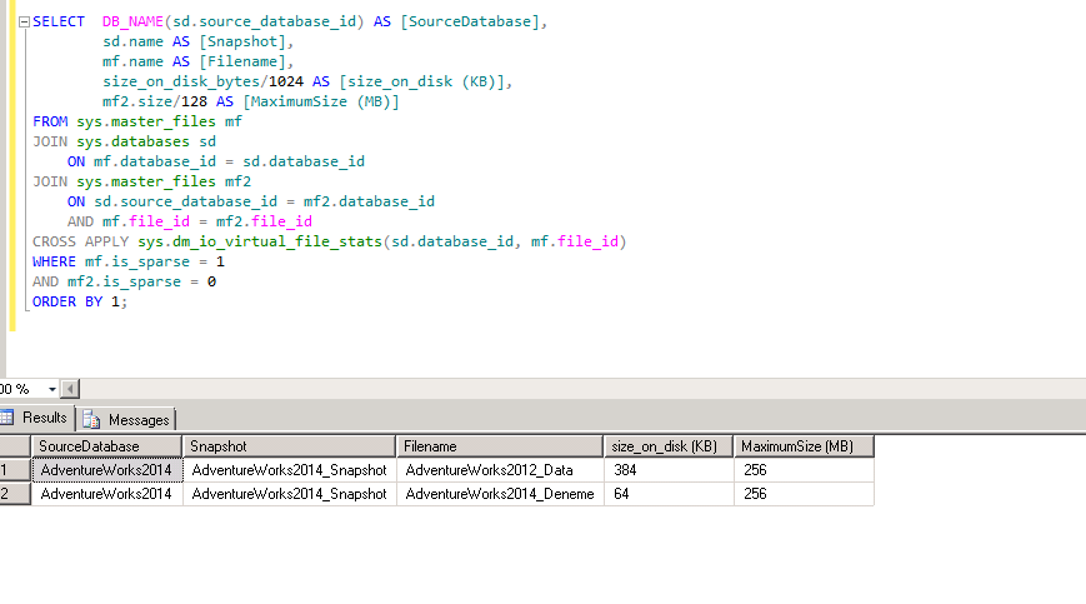
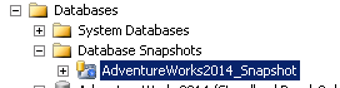
スナップショットを作成しました。
スナップショットからは、SSMSのDatabases->Database Snapshotsセクションからデータベースであるかのように読み取ることができます。
通常、ミラーリング時にセカンダリデータベースから読み取ることはできません。 ただし、セカンダリデータベースのスナップショットから読み取ることができます。
例2:
以下のスクリプトをプライマリデータベースで実行してみましょう。
|
1
2
3
4
5
|
データベースAdventureworks2014_Snapshot ON
(NAME=Adventureworks2012_Data,FILENAME=’C:\DB\Data\AdventureWorks2012_Data…..ss’ ),
( 名前=Adventureworks2014_Deneme,ファイル名=’C:\DB\Data\AdventureWorks2014_Deneme…..ss’)
Adventureworks2014のスナップショットとして;
|
スナップショットを取得した後、次のスクリプトを使用して、テーブル内のレコードを削除します。 以前にAdventureworks2014データベースで作成したSnapshot_Denemeという名前のテーブルからレコードを削除しています。
|
1
|
Snapshot_Denemeから削除
|
削除処理の後、次のスクリプトの助けを借りて、削除されたレコードを復元できます。
しかし、スナップショットを取った後に別の操作を行った場合、それらの変更は失われます。
|
1
2
3
|
use master
GO
RESTORE DATABASE Adventureworks2014FROM DATABASE_SNAPSHOT=’Adventureworks2014_Snapshot’
|


著者:dbtut
私たちは10年以上のデータベース管理とBIの経験を持つチームです。 私達のExpertises: Oracle, SQL Server, PostgreSQL, MySQL, MongoDB, Elasticsearch, Kibana, Grafana.