あなたのビジネスがインターネット上で表現されていないとき、それは世界に存在しない、痛いほど正直にしましょう。 さらに、ウェブサイトを持たなければ、より多くの質の鉛を引き付ける十分な機会を失っている。 Amazonのような企業の巨人から一人の会社までのあらゆるビジネスは、視聴者にアピールするウェブサイトとコンテンツを持つよう努めています。 オンラインであなたとあなたの会社を発見することはそこに停止しません。 ウェブサイトの背後には、webクローラーが重要な役割を果たす”人間の目には見えない”世界全体があります。
目次
- Webクローラーとインデックスとは何ですか?
- ウェブ検索はどのように機能しますか?
- Webクローラーはどのように機能しますか?
- 主なWebクローラの種類は何ですか?
- ウェブクローラの例は何ですか?
- グーグルボットとは何ですか?
- ウェブクローラーとウェブスクレーパー—違いは何ですか?
- カスタムWebクローラー—それは何ですか?
- ラップアップ
Webクローラーとインデックスとは何ですか?
webクローラーの定義から始めましょう:
webクローラー(また、webスパイダー、スパイダーボット、webボット、または単にクローラーとして知られている)は、World Wide Web全体でwebページやコンテンツをインデックス化する
インデックス作成は、ユーザーが数秒以内に関連するクエリを見つけるのに役立つため、非常に不可欠なプロセスです。 検索索引付けは、本の索引付けと比較することができます。 たとえば、教科書の最後のページを開くと、アルファベット順のクエリのリストと、教科書に記載されているページがあるインデックスが見つかります。 同じ原則は、検索インデックスを強調しますが、ページ番号の代わりに、検索エンジンは、あなたがあなたのお問い合わせへの回答を探すことができ、い
検索インデックスとブックインデックスの大きな違いは、前者は動的であるため、変更することができ、後者は常に静的であることです。
ウェブ検索はどのように機能しますか?
クローラロボットの動作の詳細に飛び込む前に、検索クエリへの回答を得る前に、検索プロセス全体がどのように実行されるかを見てみましょう。
たとえば、「地球と月の距離は何ですか」と入力してenterキーを押すと、検索エンジンに関連するページのリストが表示されます。 通常、検索に必要な情報をユーザーに提供するには、次の3つの主要な手順が必要です:
- ウェブスパイダーは、ウェブサイト上のコンテンツをクロールする
- 検索エンジンのインデックスを構築する
- 検索アルゴリズムは、最も関連性の高いページをランク付けする
また、二つの本質的なポイントを念頭に置く必要がある。:
World Wide Webにはたくさんのウェブサイトがあり、この記事を読んでいるときには今でも多くのウェブサイトが作成されています。 そういうわけでそれはあなたの問い合わせに関連しているページのリストを思い付くためにサーチエンジンのための永劫を取ることができる。 検索のプロセスを高速化するために、検索エンジンは、世界にそれらを示す前にページをクロールします。
- ワールド-ワイド-ウェブでは検索しません
確かに、ワールド-ワイド-ウェブでは検索しませんが、検索インデックスで検索します。
今すぐお問い合わせください!
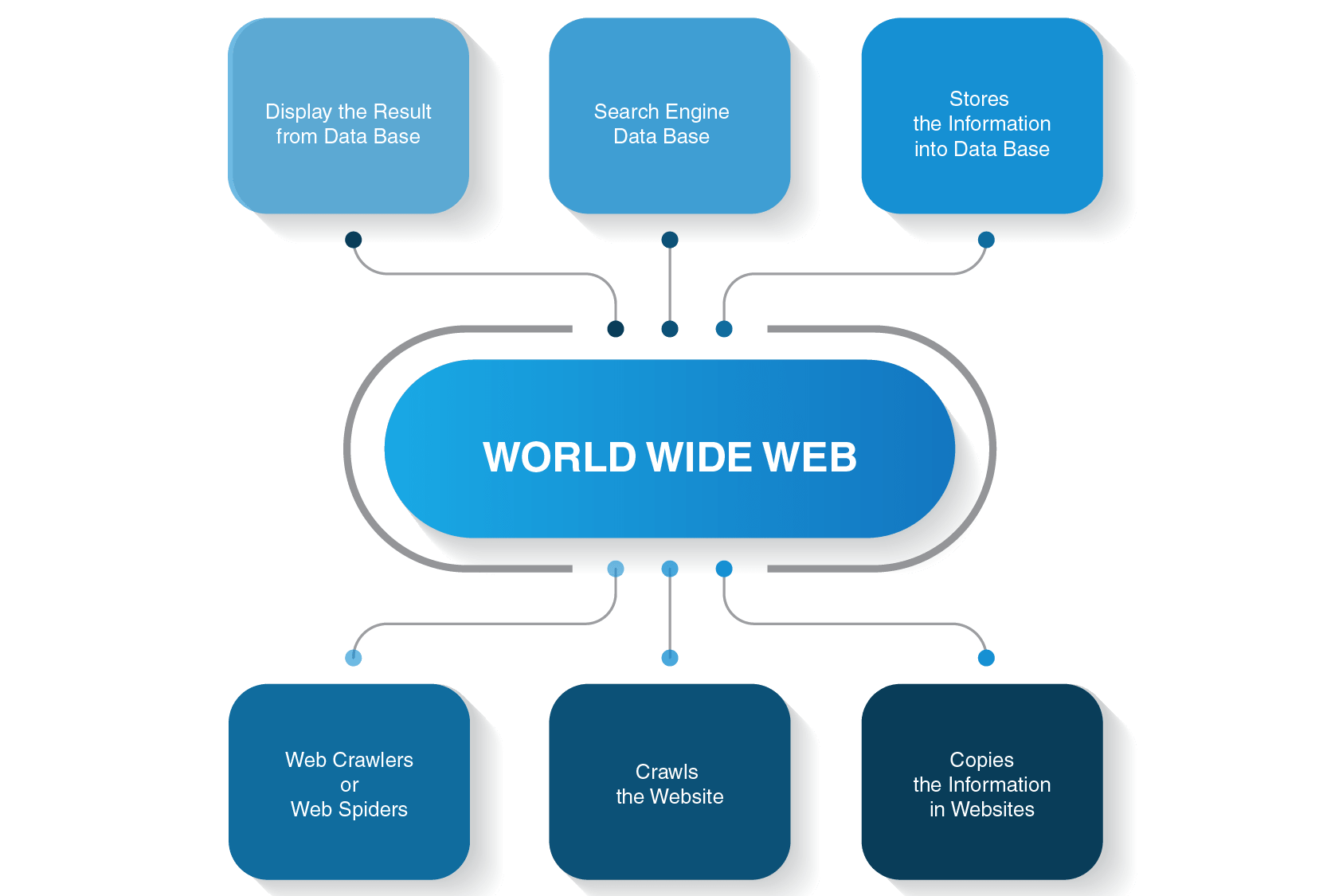
Webクローラーはどのように機能しますか?
そこには多くの検索エンジンがあります−Google、Bing、Yahoo!、Duckduckgo、百度、Yandexの、および他の多く。 それらの各々は、インデックスページにそのスパイダーボットを使用しています。
彼らは最も人気のあるウェブサイトからクロールプロセスを開始します。 ウェブボットの主な目的は、各ページのコンテンツがすべてに約あるものの要点を伝えることです。 従って、網のくもはこれらのページの単語を追求し、次にあなたの問い合わせについての情報を見つけたいと思うときサーチエンジンによって次の時
インターネット上のすべてのページはハイパーリンクで接続されているので、サイトのクモはそれらのリンクを発見し、次のページに従うことができます。 Webボットは、すべてのコンテンツと接続されたwebサイトを見つけたときにのみ停止します。 その後、記録された情報に検索インデックスが送信され、世界中のサーバーに保存されます。 全体のプロセスは、すべてが絡み合っている現実の蜘蛛の巣に似ています。
ページがインデックス化されると、クロールはすぐには停止しません。 調査エンジンは周期的にどの変更でもページになされたかどうか見るのに網のくもを使用する。 変更がある場合は、それに応じて検索エンジンのインデックスが更新されます。
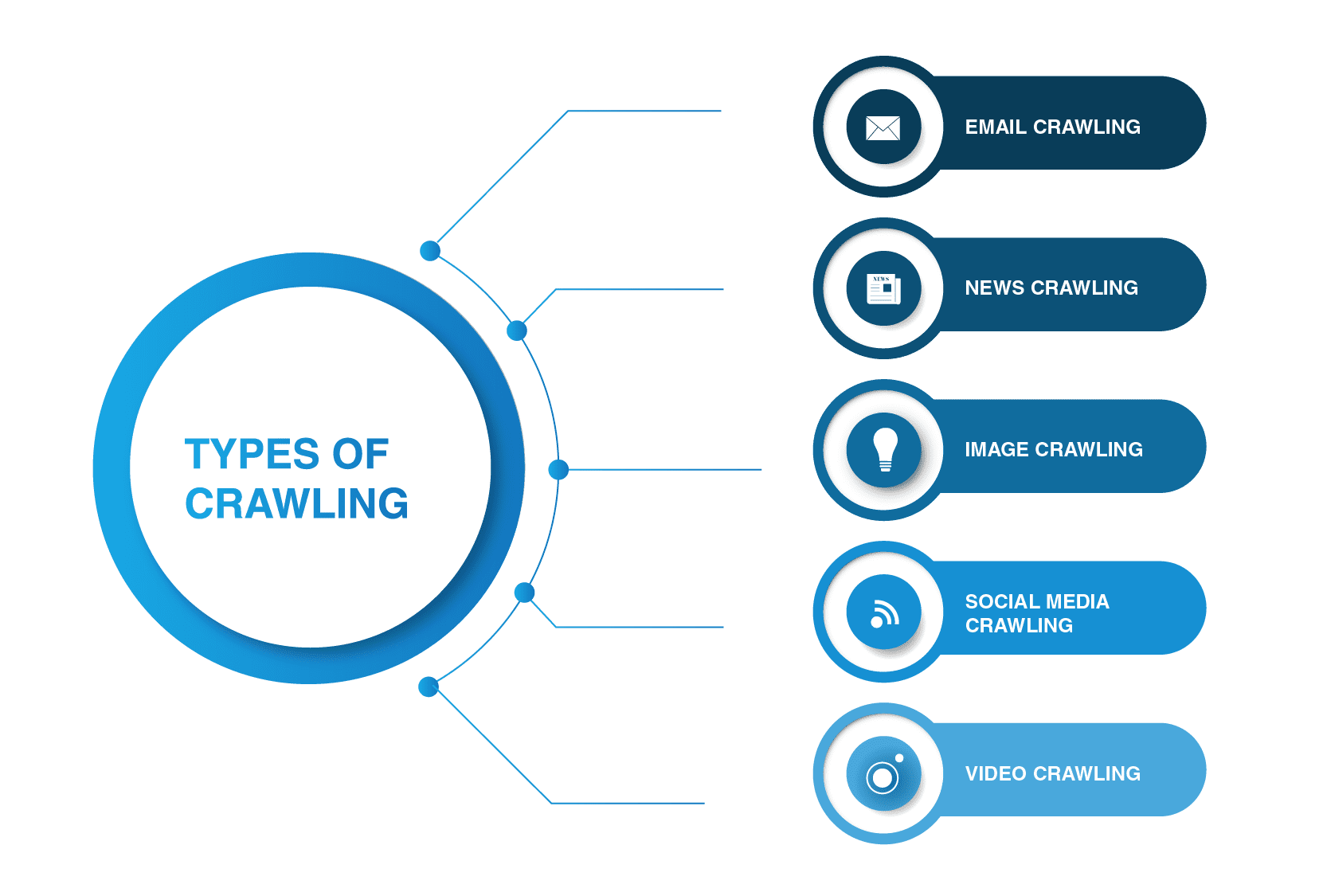
主なWebクローラーの種類は何ですか?
網のクローラーはサーチエンジンのくもに限られない。 そこに這う他のタイプの網がある。
- 電子メールクロール
電子メールクロールは、このタイプのクロールが電子メールアドレスを抽出するのに役立つため、送信リード生成で特に便利です。 この種のクロールは個人のプライバシーを侵害し、ユーザーの許可なしに使用することはできないため、違法であることに言及する価値があります。
- ニュースクロール
インターネットの出現により、世界中のニュースがウェブ上に急速に広がり、様々なウェブサイトからデータを抽出することは非常に手に負
このタスクに対処できるwebクローラはたくさんあります。 このようなクローラーは、新しい、古い、アーカイブされたニュースコンテンツからデータを取得し、RSSフィードを読むことができます。 次の情報が抽出されます: 出版の日付、著者の名前、見出し、鉛のパラグラフ、主要なテキストおよび出版の言語。
- 画像のクロール
名前が示すように、このタイプのクロールは画像に適用されます。 インターネットは視覚的な表現でいっぱいです。 したがって、このようなボットは、人々がウェブ上の画像の茄多で関連する画像を見つけるのに役立ちます。
- ソーシャルメディアクロール
ソーシャルメディアクロールは、すべてのソーシャルメディアプラットフォームがクロールできるわけではないため、非常に興味深い問題です。 このようなタイプのクロールは、データプライバシーの遵守に違反すると違法になる可能性があることにも留意する必要があります。 それでも、クロールで罰金である多くのソーシャルメディアプラットフォームプロバイダがあります。 たとえば、PinterestやTwitterでは、ユーザーに敏感ではなく、個人情報を開示していない場合、spiderボットがページをスキャンすることができます。 Facebook、LinkedInのは、この問題に関して厳格です。
- 動画クロール
多くのコンテンツを読むよりも、ビデオを見る方がはるかに簡単な場合があります。 Youtube、Soundcloud、Vimeo、またはその他のビデオコンテンツをwebサイトに埋め込むことにした場合、一部のwebクローラーでインデックスを作成できます。
Webクローラの例は何ですか?
多くの検索エンジンが独自の検索ボットを使用しています。 たとえば、最も一般的なwebクローラの例は次のとおりです:
- Alexabot
Amazon web crawler Alexabotは、webコンテンツの識別とバックリンクの検出に使用されます。 あなたの情報の一部を非公開にしたい場合は、Alexabotをあなたのウェブサイトのクロールから除外することができます。
- Yahoo! スラップボット
ヤフークローラーヤフー! Slurp Botは、ユーザーのためのパーソナライズされたコンテンツを強化するために、webページのインデックス化とスクレーピングのために使用されます。
- Bingbot
Bingbotは、Microsoftを搭載した最も人気のあるwebスパイダーの一つです。 これは、検索エンジン、Bingは、そのユーザーのための最も関連性の高いインデックスを作成するのに役立ちます。
- DuckDuck Bot
DuckDuckGoは、おそらくあなたの履歴を追跡し、あなたが訪問しているどのようなサイトであなたをフォローしていない最も人気のある検索エン そのDuckDuckボットウェブクローラーは、ユーザーのニーズを満たす最も関連性の高い最良の結果を見つけるのに役立ちます。
- Facebook外部ヒット
Facebookもクローラーを持っています。 たとえば、Facebookユーザーが外部コンテンツページへのリンクを他のユーザーと共有したい場合、クローラーはページのHTMLコードを掻き集め、コンテンツのタイトル、ビデオのタッ、または画像を両方に提供します。facebookユーザーが外部コンテンツページへのリンクを他のユーザーと共有したい場合、クローラーはページのHTMLコードを掻き集め、コンテンツのタイトル、ビデオのタグ、または画像を両方に提供します。
- Baiduspider
このクローラーは、支配的な中国の検索エンジン−百度によって運営されています。 他のボットと同様に、さまざまなwebページを移動し、エンジンのコンテンツをインデックス化するためのハイパーリンクを探します。
- Exabot
フランスの検索エンジンExaleadは、エンジンのインデックスに含めることができるように、コンテンツのインデックス化にExabotを使用しています。
- Yandex Bot
このボットは、最大のロシアの検索エンジンYandexに属しています。 あなたがそこにビジネスを行うことを計画していない場合は、コンテンツのインデックスからそれをブロックすることができます。
Googlebotとは何ですか?
上記のように、ほとんどすべての検索エンジンがスパイダーボットを持っており、Googleも例外ではありません。 Googlebotは、このエンジンのコンテンツのインデックス作成に使用される、世界で最も人気のある検索エンジンを搭載したgoogleクローラーです。
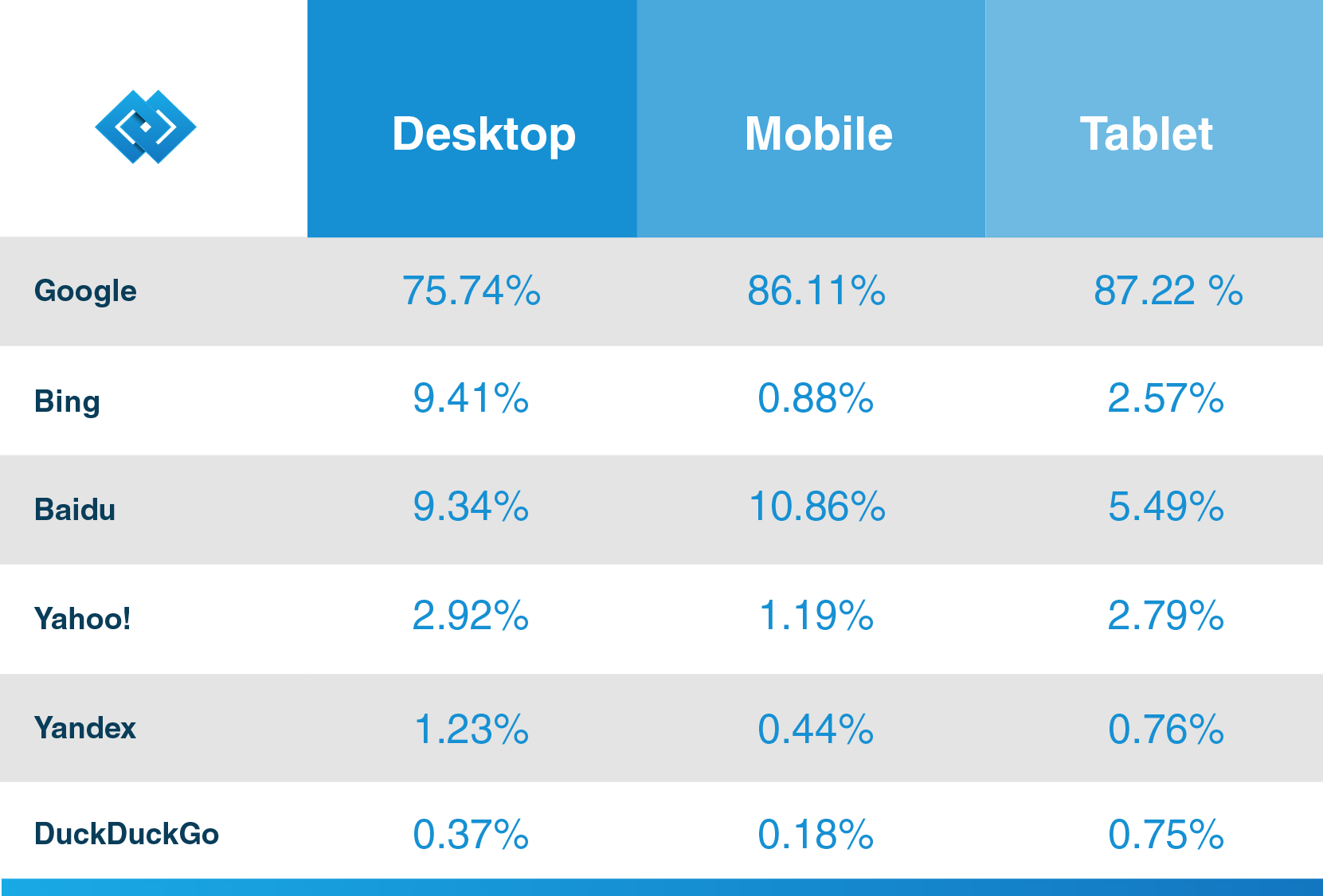
有名なCRMベンダーであるHubspotがブログで述べているように、Googleは検索市場シェアの92.42%以上を持ち、モバイルトラフィックは86%を超えています。 あなたのビジネスのための検索エンジンを最大限に活用したいのであれば、あなたの将来の顧客がGoogleのおかげであなたのコンテンツを発見できる
Googlebotには、デスクトップボットとモバイルアプリのクローラーの二つのタイプがあります。 これは、他のwebスパイダーと同じクロール原則を使用しています,以下のリンクやウェブサイト上で利用可能なスキャンコンテンツのような. このプロセスは完全に自動化されており、定期的ではない間隔で同じページに数回アクセスできることを意味します。
コンテンツを公開する準備ができている場合は、Googleクローラーがインデックスを作成するまでに数日かかります。 あなたがウェブサイトの所有者である場合は、手動でGoogleとしてフェッチを介してインデックス作成要求を送信するか、ウェブサイトのサイトマップを更新することにより、プロセスを高速化することができます。
ロボットを使うこともできます。txt(またはRobots Exclusion Protocol)は、googlebotを含むスパイダーボットに”指示を与える”ためのものです。 そこにクローラーがあなたのウェブサイトのある特定のページを訪問することを許可するか、または禁止することができる。 ただし、このファイルには第三者が簡単にアクセスできることに注意してください。 彼らはあなたがインデックス作成から制限されたサイトのどの部分が表示されます。
WebクローラーとWebスクレーパー—違いは何ですか?
多くの人がウェブクローラーとウェブスクレーパーを同じ意味で使用しています。 それにもかかわらず、これら二つの間に本質的な違いがあります。 前者がタグ、見出し、キーワード、およびその他のもののようなコンテンツのメタデータを主に扱う場合、後者は他の誰かのオンラインリソースに投稿される
ウェブスクレーパーも特定のデータを”狩る”。 たとえば、株式市場の動向、ビットコイン価格などの情報があるwebサイトから情報を抽出する必要がある場合は、web scraping botを使用してこれらのwebサイトか
あなたのウェブサイトをクロールし、インデックス作成のためにコンテンツを提出したい場合、または他の人がそれを見つけるつもりがある場合—それは完全に合法であり、そうでなければ他の人や企業のウェブサイトを掻き集めることは法律に違反しています。
カスタムWebクローラー—それは何ですか?
カスタムwebクローラーは、特定のニーズをカバーするために使用されるボットです。 あなたが解決する必要がある任意のタスクをカバーするためにあなたのスパイダーボットを構築することができます。 例えば、企業家またはmarketerまたは内容を取扱う他のどの専門家でも、あなたの顧客およびユーザーがあなたのウェブサイトでほしい情報を見つけること さまざまな目的のためにさまざまなwebボットを作成できます。
カスタムwebクローラーの構築に関する実務経験がない場合は、いつでもソフトウェア開発サービスプロバイダーに連絡することができます。
ラップアップ
ウェブサイトのクローラは、コンテンツのインデックス作成と発見に使用される主要な検索エンジンの不可欠な部分です。 多くの検索エンジン企業は、例えば、googlebotは、企業の巨大なGoogleによって供給され、彼らのボットを持っています。 それとは別に、ビデオ、画像、ソーシャルメディアのクロールなど、特定のニーズをカバーするために利用されるクロールの複数の種類があります。
スパイダーボットが何をすることができるかを考慮すると、webクローラーはあなたとあなたの会社を世界に明らかにし、新しいユーザーや顧客をもたらすことができるため、彼らはあなたのビジネスにとって非常に不可欠で有益です。
カスタムwebクローラーを作成する場合は、経験豊富なweb開発サービスプロバイダーであるLITSLINKにお問い合わせください。