이 기사는 데이터 과학 블로그톤의 일부로 게시되었습니다.
“세상에서 가장 큰 종교는 종교가 아니다.”-페르난도 토레스
소개
축구는 모두에게 사랑 받고 있으며 그 아름다움은 예측할 수없는 성격에 있습니다. 이 게임과 강하게 관련된 한 가지는 팬,누가 게임을 이길 것인지에 대한 게임 전에 우울하고 토론하는 것입니다. 그리고 일부 팬들은 심지어 경기 전에 스코어 라인을 추측하는 한계로 이동합니다. 그래서 논리적으로 이러한 질문 중 일부에 대답 해 봅시다.
푸아송을 알기
앞서 축구는 예측할 수 없는 경기라고 말씀드렸듯이,이전 골이나 팀 또는 다른 요소들에 대한 의존성이 전혀 없는 완전히 무작위적인 경기에서 어느 순간이라도 골이 발생할 수 있습니다. 잠깐,나는”무작위”라고 말했다. 무작위로 발생하는 이벤트의 확률을 찾는 데 사용되는 통계 분포가 있기 때문에 포아송 분포입니다.
친구가 게임 당 평균 2 골이 발생한다고 가정 해 봅시다. 그렇다면 경기에서 두 골을 볼 수있는 실제 기회는 무엇입니까? 여기에 우리의 구조에 온다 푸아송 분포 관찰의 확률을 찾는 데 도움이’엔’이벤트(읽기’엔’목표)고정 된 기간에 우리는 발생 이벤트의 기대와 함께 제공 주어진(기간 당 평균 이벤트). 수학적으로 한번 봅시다
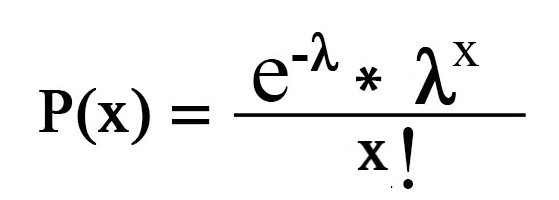
(6865>
득점 기회
이제이 방정식으로 몇 가지 질문에 답해 보겠습니다.하지만 먼저 데이터가 필요합니다.이를 위해 1872 년부터 2020 년까지 국제 축구 결과를 다운로드했습니다. 우리의 데이터 세트의 샘플은 다음과 같습니다.
코드:
data.head(3)
.png)
우리가 90 분 안에 예상 할 수있는 평균 목표를 찾는 것으로 시작합시다.
이를 위해 21 세기(2000-2020)에 재생 된 경기에 대한 데이터를 필터링하는 별도의 데이터 세트를 만들고 총 번호를 찾기 위해 홈_점수 및 예상_점수를 추가했습니다. 각 경기에서 발생하는 목표의 다음 우리가 경기에서 기대할 수있는 평균 목표를 얻기 위해 총 목표 열의 평균을 촬영.
코드:
data=data+datadata=data.apply(lambda x : int(str.split(x,'-')))rec_data=data.loc>=2000)]rec_data.iloc]print(rec_data.total_goals.mean())
2.744112130054189
이 기대치를 포이손 배분 공식에서 제시하면 경기에서 3 골을 볼 수 있는 실제 기회가 무엇인지 알 수 있습니다.
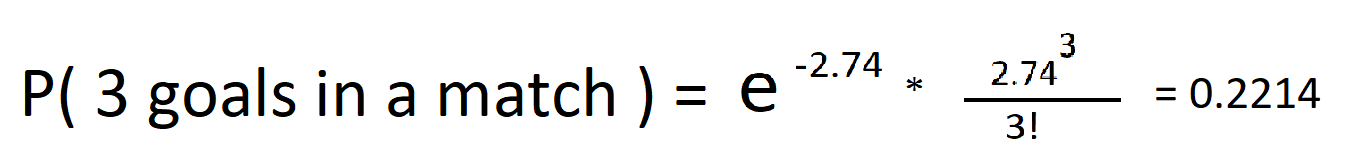
와우,단지 22%의 확률로. 아니오의 확률을 그려봅시다 더 나은 그림을 얻기 위하여 성냥안에 목표의.
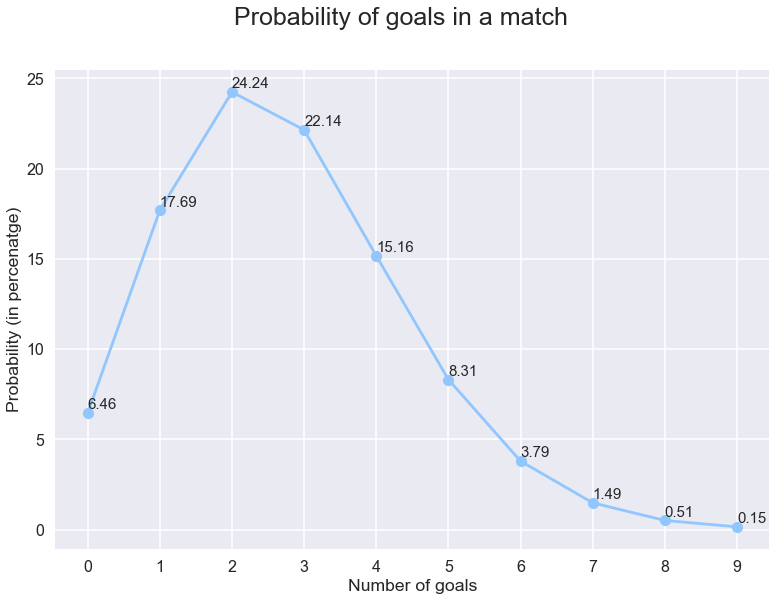
이제 이것으로부터,우리는 단순히’엑스’의 확률과’엑스’보다 작은 숫자를 추가하여’엑스’또는 더 적은 수의 목표를 볼 확률을 계산할 수 있습니다.그리고 이것을 1 에서 빼면 우리는 경기에서’엑스’이상의 목표를 볼 확률을 얻을 수 있습니다. 이것도 그려봅시다.
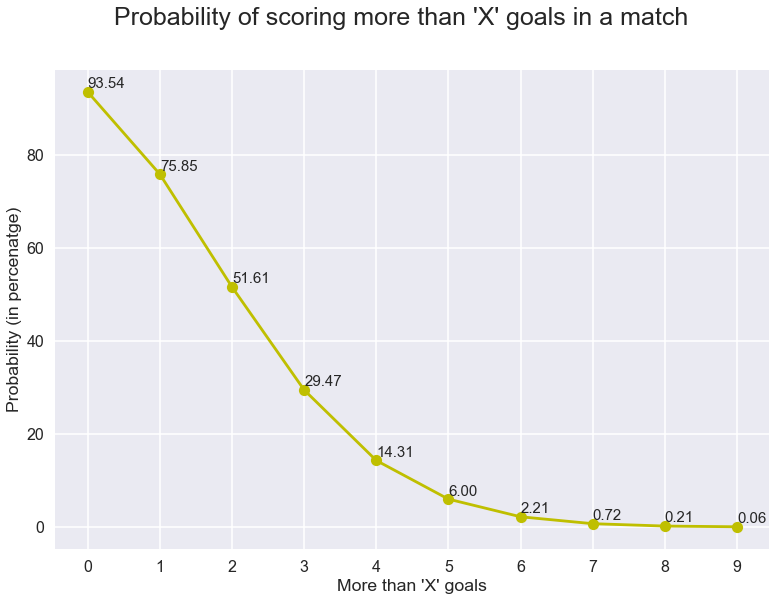
기다림은 끝났다…
이제 당신은 전체 게임에 앉아 싶어하지 않는 참을성이 친구가 있다고 가정. 그리고 그는 경기 도중 당신에게 와서 그가 목표를보기 위해 기다릴 필요가 않습니다 얼마나 많은 시간을 묻습니다. 와우,그 어려운 질문 권리입니다,하지만 걱정하지,통해 앉아 물어 10000 게임 각 목표 사이의 시간을 참고. 그냥 농담,분명히,그는 흥분 것입니다. 실제로 나는 시뮬레이션 10000 일치 및 평균 시간을 발견.
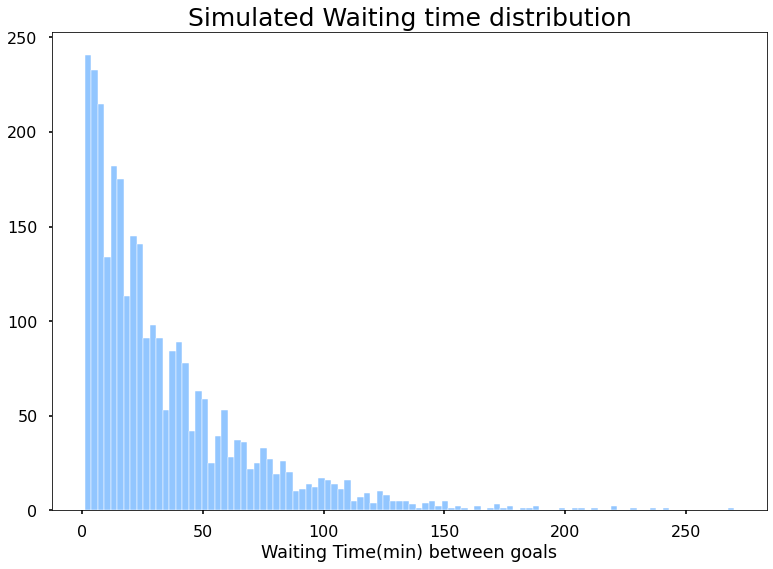
가장 가능성이 높은 대기 시간은 2 분입니다. 그러나 기대 이제 내가 무엇을 찾고,내가 원하는 평균 시간을 기다려야한 목표가 있다면 나를 보고 게임에서 임의의 시간입니다. 이를 위해 각 인스턴스가 10000 게임을보고 그 10000 게임에서 목표 사이의 평균 대기 시간을 계산하고 우리를보고하는 10000 인스턴스를 취할 것입니다. 마지막으로 각 인스턴스에서 10000 개의 보고서를 플로팅하고 예상 평균 대기 시간을 찾습니다.
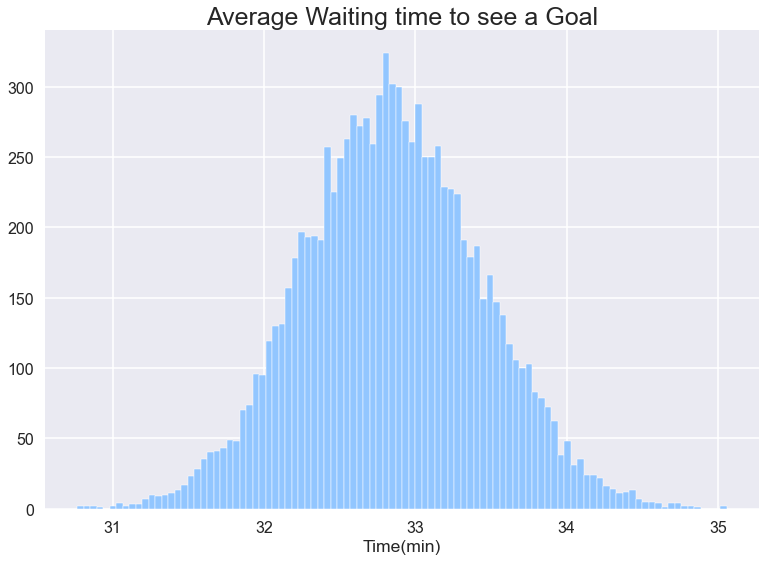
우리는 약 33 분을 기다려야 할 것 같습니다. 우리가 더 기다려야 할 수도 있지만,이 고전 대기 시간 역설이다.
스코어 라인 예측
마지막으로,우리가 시작한 질문과 가장 흥미로운 질문을 할 수 있습니다.
이를 위해 두 팀 간의 이력(홈팀과 원정팀으로 간주)을 사용하여 홈팀의 예상 골로 평균 _홈 _스코어를 원정팀의 예상 골로,평균 _아웨이 _스코어를 원정팀의 예상 골로 간주하고 포아송 분포를 사용하여 스코어라인을 예측합니다. 팀 간의 만남이 적은 경우,우리는 몇 가지 요인을 고려할 것입니다
역사 전반에 걸쳐 홈 팀이 득점 한 홈 골 평균.
=역사를 통해 원정 팀이 득점 한 원정 골 평균.
홈 팀의 홈 경기에서 실점 한 골 평균.
교류=원정 팀의 원정 경기에서 실점 한 골 평균.따라서,원정팀의 예상 점수는(원정팀+교류)/2
로 계산됩니다. 예상 점수는 우리가 그들 사이의 게임에서 득점 할 것으로 예상 목표의 평균 수입니다.
코드:
import pandas as pdimport numpy as npfrom scipy import stats
def PredictScore(): home_team = input("Enter Home Team: ") ht = (''.join(home_team.split())).lower() away_team = input("Enter Away Team: ") at = (''.join(away_team.split())).lower() if len(data) > 20: avg_home_score = data.home_score.mean() avg_away_score = data.away_score.mean() home_goal = int(stats.mode(np.random.poisson(avg_home_score,100000))) away_goal = int(stats.mode(np.random.poisson(avg_away_score,100000))) else: avg_home_goal_conceded = data.away_score.mean() avg_away_goal_scored = data.away_score.mean() away_goal = int(stats.mode(np.random.poisson(1/2*(avg_home_goal_conceded+avg_away_goal_scored),100000))) avg_away_goal_conceded = data.home_score.mean() avg_home_goal_scored = data.home_score.mean() home_goal = int(stats.mode(np.random.poisson(1/2*(avg_away_goal_conceded+avg_home_goal_scored),100000))) avg_total_score = int(stats.mode( np.random.poisson((data.total_goals.mean()),100000))) print(f'Expected total goals are {avg_total_score}') print(f'They have played {len(data)} matches') print(f'The scoreline is {home_team} {home_goal}:{away_goal} {away_team}')
브라질을 홈팀으로,멕시코를 원정팀으로 해보자.
코드:
PredictScore()
.png)
푸아송 분포는 우리에게 브라질이 2-0 스코어 라인으로 승리 할 것이라는 예측을 제공합니다. 나는 그물을 수색하고 그들 사이의 마지막 경기가 2018 년 7 월 2 일에 열렸고 스코어 라인은 브라질이 2-0 으로 승리했다고 밝혔다. 글쎄,난 운이 좋았어,당신은하지 않을 수 있습니다.
결론
더 이상 걱정하지 않으려면 여기 내 코드가 있습니다. 또한이 게임을 예측하는 단지 기본적인 방법입니다,요즘 분류 알고리즘은 스코어를 예측하는 결과와 회귀 알고리즘을 예측하는 데 사용됩니다. 하지만 그 다음 재미를 가지고 노는 때까지,다른 날에 대한 주제입니다. 안녕!