La oss være smertelig ærlig, når bedriften ikke er representert På Internett, er det ikke-eksisterende til verden. Videre, hvis du ikke har et nettsted, du mister en god mulighet til å tiltrekke seg flere kvalitet fører. Enhver bedrift fra en bedriftsgigant Som Amazon til Et enkeltpersonfirma forsøker å ha et nettsted og innhold som appellerer til publikum. Oppdage deg og din bedrift online stopper ikke der. Bak nettsteder er det en hel «usynlig for det menneskelige øye» verden der web crawlere spiller en viktig rolle.
Innhold
- Hva Er En Web Crawler Og Indeksering?
- Hvordan Fungerer Et Nettsøk?
- Hvordan Fungerer En Web Crawler?
- Hva Er De Viktigste Web Crawler Typene?
- Hva Er Eksempler på Søkeroboter?
- Hva er En Googlebot?
- Web Crawler vs Web Scraper-Hva Er Forskjellen?
- Tilpasset Web Crawler-Hva Er Det?
- Innpakning
Hva Er En Web Crawler Og Indeksering?
La oss starte med en web crawler definisjon:
en web crawler (også kjent som en web spider, spider bot, web bot, eller bare en crawler) er et dataprogram som brukes av en søkemotor for å indeksere nettsider og innhold over Hele World Wide Web.
Indeksering er ganske viktig, da Det hjelper brukerne å finne relevante spørsmål innen sekunder. Søkeindekseringen kan sammenlignes med bokindekseringen. For eksempel, hvis du åpner siste sider i en lærebok, finner du en indeks med en liste over spørringer i alfabetisk rekkefølge og sider der de er nevnt i læreboken. Det samme prinsippet understreker søkeindeksen, men i stedet for sidenummerering viser en søkemotor deg noen lenker der du kan lete etter svar på forespørselen din.
den signifikante forskjellen mellom søke-og bokindeksene er at den førstnevnte er dynamisk, derfor kan den endres, og sistnevnte er alltid statisk.
Hvordan Fungerer Et Nettsøk?
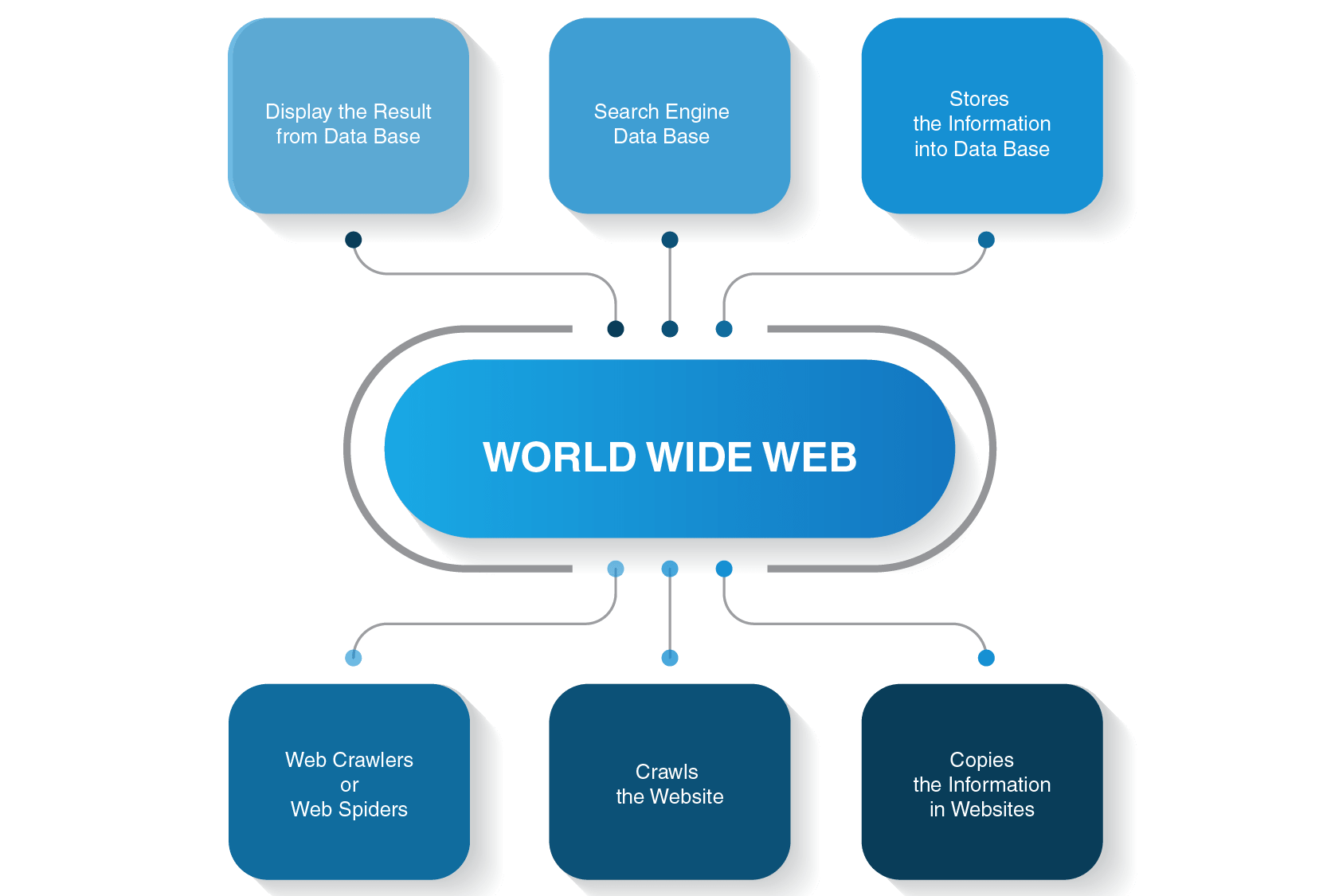
før du drar inn i detaljene om hvordan en robotrobot fungerer, la oss se hvordan hele søkeprosessen utføres før du får svar på søket ditt.
for eksempel, hvis du skriver «hva er avstanden Mellom Jorden og Månen» og trykk enter, vil en søkemotor vise deg en liste over relevante sider. Som oftest, det tar tre store skritt for å gi brukerne den nødvendige informasjonen til sine søk:
- en web edderkopp kryper innhold på nettsteder
- det bygger en indeks for en søkemotor
- søkealgoritmer rangerer de mest relevante sidene
Man må også huske på to viktige punkter:
- Du gjør ikke søkene dine i sanntid, da det er umulig
Det er mange nettsteder på World Wide Web, og mange flere blir opprettet selv nå når du leser denne artikkelen. Det er derfor det kan ta evigheter for en søkemotor for å komme opp med en liste over sider som ville være relevant for søket. For å øke hastigheten på prosessen med å søke, gjennomsøker en søkemotor sidene før de vises til verden.
- du gjør ikke søkene Dine På World Wide Web
faktisk utfører du ikke søk på World Wide Web, men i en søkeindeks, og dette er når en web crawler går inn på slagmarken.
Kontakt Oss Nå!
Hvordan Fungerer En Web Crawler?
Det er mange søkemotorer der ute − Google, Bing, Yahoo!, Duckduckgo, Baidu, Yandex, Og mange andre. Hver av dem bruker sin spider bot til å indeksere sider.
de starter gjennomsøkingsprosessen fra de mest populære nettstedene. Deres primære formål med webboter er å formidle kjernen i hva hver sideinnhold handler om. Dermed søker web edderkopper ord på disse sidene og bygger deretter en praktisk liste over disse ordene som vil bli brukt av en søkemotor neste gang du vil finne informasjon om søket ditt.
Alle sider på Internett er forbundet med hyperkoblinger, slik at sideedderkopper kan oppdage disse koblingene og følge dem til de neste sidene. Webboter stopper bare når de finner alt innhold og tilkoblede nettsteder. Deretter sender de den registrerte informasjonen en søkeindeks, som er lagret på servere over hele verden. Hele prosessen ligner en ekte edderkoppnett hvor alt er sammenflettet.
Crawling stopper ikke umiddelbart når sidene er indeksert. Søkemotorer bruker regelmessig web edderkopper for å se om noen endringer er gjort på sider. Hvis det er en endring, vil indeksen til en søkemotor bli oppdatert tilsvarende.
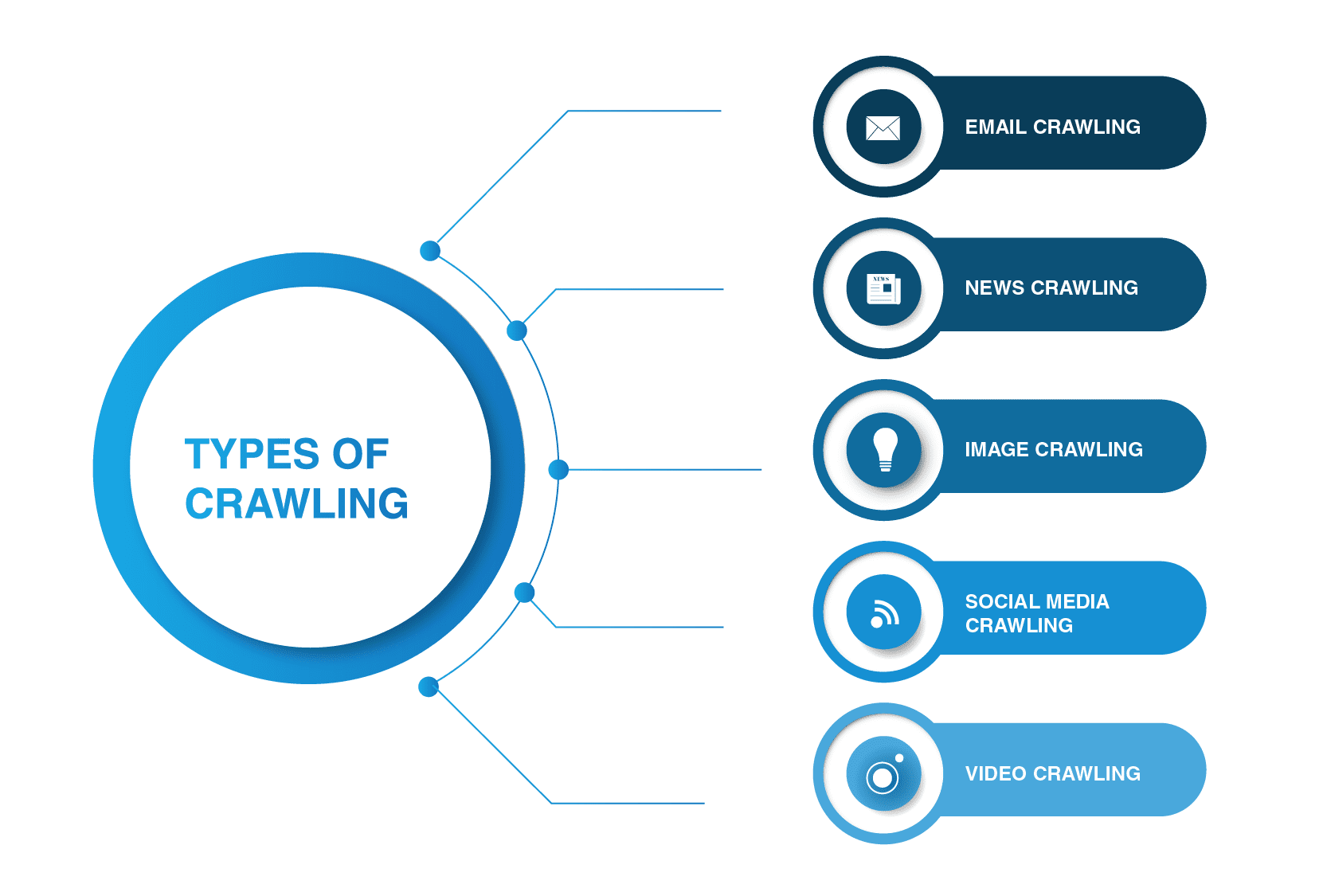
Hva Er De Viktigste Typer Web Crawler?
søkeroboter er ikke begrenset til søkemotoredderkopper. Det finnes andre typer web crawling der ute.
- e-postkryp
e-postkryping er spesielt nyttig i utgående generering av kundeemner, da denne typen gjennomsøking hjelper til med å trekke ut e-postadresser. Det er verdt å nevne at denne typen gjennomsøking er ulovlig da den bryter personvernet og ikke kan brukes uten brukerens tillatelse.
- Nyheter krypende
med bruk av Internett, kan nyheter fra Hele verden spres raskt rundt På Nettet, og for å trekke ut data fra ulike nettsteder kan være ganske uhåndterlig.
det er mange web crawlere som kan takle denne oppgaven. Slike crawlere kan hente data fra nytt, gammelt og arkivert nyhetsinnhold og lese RSS-feeder. De trekker ut følgende informasjon: dato for publisering, forfatterens navn, overskrifter, hovedavsnitt, hovedtekst og publiseringsspråk.
- bildekryptering
som navnet tilsier, brukes denne typen gjennomsøking på bilder. Internett er fullt av visuelle representasjoner. Dermed hjelper slike bots folk med å finne relevante bilder i en mengde bilder over Nettet.
- sosiale medier gjennomgang
sosiale medier gjennomgang er ganske interessant, da ikke alle sosiale medieplattformer tillater å bli gjennomsøkt. Du bør også huske på at slik type gjennomgang kan være ulovlig hvis det bryter data privacy compliance. Likevel er det mange sosiale medier plattformleverandører som er fine med kravlesøk. For Eksempel, Pinterest og Twitter tillate spider bots å skanne sine sider hvis de ikke er brukersensitive og ikke avsløre noen personlig informasjon. Facebook, LinkedIn er strenge om denne saken.
- video gjennomgang
Noen ganger er det mye lettere å se en video enn å lese mye innhold. Hvis Du bestemmer deg for å legge Inn Youtube, Soundcloud, Vimeo eller annet videoinnhold på nettstedet ditt, kan det indekseres av noen web crawlere.
Hva Er Eksempler på Søkeroboter?
mange søkemotorer bruker sine egne søkeroboter. For eksempel er de vanligste web crawlers eksemplene:
- Alexabot
Amazon web crawler Alexabot brukes til identifisering av webinnhold og tilbakekobling. Hvis Du vil holde noe av informasjonen din privat, kan Du ekskludere Alexabot fra å gjennomsøke nettstedet ditt.
- Yahoo! Slurp Bot
yahoo crawler Yahoo! Slurp Bot brukes til indeksering og skraping av nettsider for å forbedre personlig innhold for brukere.
- Bingbot
Bingbot er En Av De mest populære web edderkopper drevet Av Microsoft. Det hjelper en søkemotor, Bing, for å skape den mest relevante indeksen for sine brukere.
- DuckDuck Bot
DuckDuckGo er trolig en av de mest populære søkemotorene som ikke sporer historien din og følger deg på hvilke nettsteder du besøker. Dens DuckDuck Bot web crawler bidrar til å finne de mest relevante og beste resultatene som vil tilfredsstille en brukers behov.
- Facebook Ekstern Hit
Facebook Har også sin crawler. For Eksempel, Når En Facebook-bruker ønsker å dele en lenke til en ekstern innholdsside med en annen person, skraper crawleren HTML-koden på siden og gir dem begge tittelen, en tagg av videoen eller bildene av innholdet.
- Baiduspider
denne søkeroboten drives av den dominerende kinesiske søkemotoren − Baidu. Som alle andre bot, reiser den gjennom en rekke nettsider og ser etter hyperkoblinger for å indeksere innhold for motoren.
- Exabot
fransk søkemotor Exalead bruker Exabot for indeksering av innhold slik at det kan inkluderes i motorens indeks.
- Yandex Bot
denne bot tilhører den største russiske søkemotoren Yandex. Du kan blokkere det fra å indeksere innholdet ditt hvis du ikke planlegger å drive virksomhet der.
Hva er En Googlebot?
som det ble sagt ovenfor, har nesten alle søkemotorer sine edderkoppbots, Og Google Er ikke noe unntak. Googlebot er en google crawler drevet av den mest populære søkemotoren i verden, som brukes til indeksering av innhold for denne motoren.
Som Hubspot, en kjent CRM-leverandør, sier I sin blogg, Har Google mer enn 92,42% av markedsandelen, Og mobiltrafikken er over 86%. Så, hvis du vil få mest mulig ut av søkemotoren for bedriften din, kan du finne ut mer informasjon på webspindelen, slik at dine fremtidige kunder kan oppdage innholdet ditt takket Være Google.
Googlebot kan være av to typer-en desktop bot og en mobile app crawlers, som simulerer brukeren på disse enhetene. Den bruker samme kravlesøk prinsippet som alle andre web edderkopp, som å følge lenker og skanning innhold tilgjengelig på nettsteder. Prosessen er også helautomatisk og kan være tilbakevendende, noe som betyr at den kan besøke samme side flere ganger med ikke-regelmessige intervaller.
hvis du er klar til å publisere innhold, vil Det ta dager For google crawler å indeksere det. Hvis du er eier av nettstedet, kan du manuelt fremskynde prosessen ved å sende inn en indekseringsforespørsel Via Hent Som Google eller oppdatere nettstedets sitemap.
du kan også bruke roboter.txt (Eller Robots Exclusion Protocol) for å «gi instruksjoner» til en spider bot, inkludert Googlebot. Der kan du tillate eller forby crawlere å besøke bestemte sider på nettstedet ditt. Vær imidlertid oppmerksom på at denne filen lett kan nås av tredjeparter. De vil se hvilke deler av nettstedet du begrenset fra indeksering.
Web Crawler vs Web Scraper-Hva Er Forskjellen?
mange mennesker bruker web crawlere og web skraper om hverandre. Likevel er det en viktig forskjell mellom disse to. Hvis den tidligere handler mest med metadata av innhold, som koder, overskrifter, søkeord og andre ting, stjeler sistnevnte «innhold» fra et nettsted for å bli lagt ut på andres online ressurs.
en webskraper «jakter også» for spesifikke data. For eksempel, hvis du trenger å trekke ut informasjon fra et nettsted der det er informasjon som aksjemarkedstrender, Bitcoin-priser eller noe annet, kan du hente data fra disse nettstedene ved å bruke en nettskraping bot.
hvis du gjennomsøker nettstedet ditt, og du vil sende inn innholdet ditt for indeksering, eller har en intensjon om at andre skal finne det — det er helt lovlig, ellers er skraping av andres og selskapers nettsteder mot loven.
Tilpasset Web Crawler-Hva Er Det?
en tilpasset søkerobot er en bot som brukes til å dekke et bestemt behov. Du kan bygge din spider bot for å dekke enhver oppgave som må løses. For eksempel, hvis du er en entreprenør eller markedsfører eller en annen profesjonell som handler med innhold, kan du gjøre det enklere for dine kunder og brukere å finne informasjonen de vil ha på nettstedet ditt. Du kan opprette en rekke webboter til ulike formål.
hvis du ikke har noen praktisk erfaring med å bygge din tilpassede web crawler, kan du alltid kontakte en programvareutviklingsleverandør som kan hjelpe deg med det.
Innpakning
nettsideroblere er en integrert del av en hvilken som helst større søkemotor som brukes til indeksering og oppdagelse av innhold. Mange søkemotorfirmaer har sine bots, For eksempel Er Googlebot drevet Av bedriftsgiganten Google. Bortsett fra det, er det flere typer kravlesøk som brukes til å dekke spesifikke behov, som video, bilde eller sosiale medier kravlesøk.
Med tanke på hva spider bots kan gjøre, er de svært viktige og fordelaktige for bedriften din fordi web crawlere avslører deg og din bedrift til verden og kan få inn nye brukere og kunder.
hvis DU ønsker å opprette en tilpasset søkerobot, kan DU kontakte LITSLINK, en erfaren leverandør av webutviklingstjenester, for mer informasjon.