i denne artikkelen skrevet av en leverandør av en sikkerhetsovervåkingsløsning, var hovedargumentet (ofte ekko i andre publikasjoner og ulike messer) at patching OT-systemer er vanskelig. Forfatteren hevder at siden det er vanskelig, bør vi vende oss til andre metoder for å forbedre sikkerheten. Hans teori er å slå på en varslingsteknologi som hans og koble de ventende alarmer med et sikkerhetshendelsesrespons team. Med andre ord, bare godta patching er vanskelig, gi opp, og hell mer penger til å lære tidligere(kanskje ?) og reagerer mer kraftig.
men denne konklusjonen (patching er vanskelig, så ikke bry deg) er feil av et par grunner. For ikke å nevne, glatter han også over en veldig stor faktor som betydelig kompliserer enhver respons eller utbedring som bør vurderes.
den første grunnen til at dette er farlig råd er at du bare ikke kan ignorere patching. Du må gjøre det du kan, når du kan, og når patching ikke er et alternativ, flytter du til plan B, C og D. Å gjøre ingenting betyr at alle cyberrelaterte hendelser som kommer seg inn i miljøet ditt, vil gi maksimal skade. Dette høres mye ut Som m&m forsvaret Fra 20 år siden. Dette er ideen om at sikkerhetsløsningen din skal være hard og knasket på utsiden, men myk og seig på innsiden.
den andre grunnen til at dette rådet er feil, er antagelsen om AT ot-sikkerhetspersonell (for hendelsesrespons eller patching) er enkle å finne og distribuere! Dette er ikke sant-faktisk, EN AV ICS sikkerhetshendelser referert i artikkelen påpeker at mens en patch var tilgjengelig og klar for installasjon, det var ingen ICS eksperter tilgjengelig for å overvåke oppdateringen installasjon! Hvis vi ikke kan frigjøre sikkerhetsekspertene våre til å distribuere kjent beskyttelse før hendelsen som en del av et proaktivt patchadministrasjonsprogram, hvorfor tror vi at vi kan finne budsjettet for et fullstendig hendelsesresponsteam i ettertid når det er for sent?
Endelig er det manglende stykket fra dette argumentet at utfordringene TIL ot / ICS patch management blir ytterligere forverret av mengden og kompleksiteten av eiendeler og arkitektur i ET ot-nettverk. For å være klar, når en ny oppdatering eller sårbarhet er utgitt, er de fleste organisasjoners evne til å forstå hvor mange eiendeler som er i omfang og hvor de er en utfordring. Men det samme nivået av innsikt og aktivaprofiler vil være nødvendig for alle hendelsesresponsteam for å være effektive. Selv hans råd om å ignorere praksisen med patching kan ikke la deg unngå å måtte bygge en robust, kontekstuell beholdning (grunnlaget for patching!) som grunnlag for DITT ot cyber security-program.
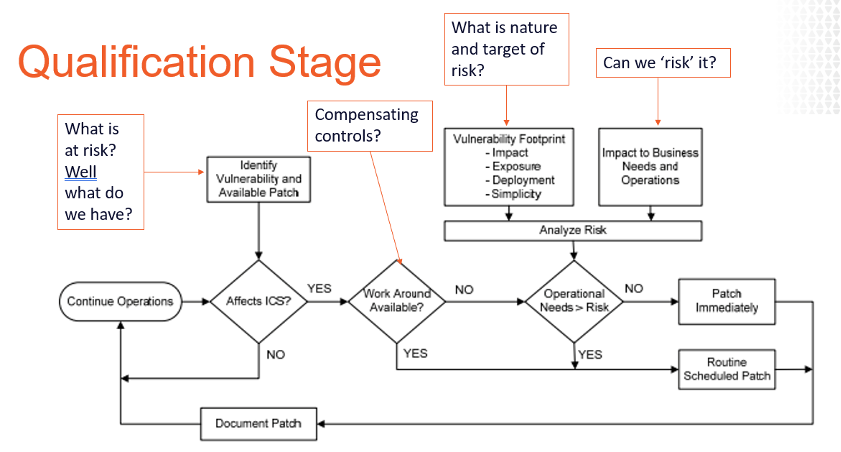
Så, hva skal vi gjøre? Først og fremst må vi prøve å lappe. Det er tre ting som en moden ICS patch management program må inneholde for å lykkes:
- Real-time, kontekstuell inventar
- Automatisering av utbedring (både patch-filer og ad hoc-beskyttelse)
- Identifikasjon og anvendelse av kompenserende kontroller
Real-time kontekstuell inventar for patch management
De Fleste ot-miljøer bruker skannebaserte patching verktøy SOM WSUS/SCCM som er ganske standard, men ikke altfor innsiktsfull for å vise oss hvilke eiendeler vi har og hvordan de er konfigurert. Det som virkelig trengs er robuste ressursprofiler med deres operasjonelle kontekst inkludert. Hva mener jeg med dette? Aktiva IP, modell, OS, etc. er en veldig overfladisk liste over hva som kan være i omfang for den nyeste oppdateringen. Hva er mer verdifullt er den operasjonelle konteksten som aktivakritikalitet til sikker drift, eiendelplassering, eiendomseier, etc. for å riktig kontekstualisere vår nye risiko fordi ikke alle ot eiendeler er skapt like. Så hvorfor ikke først beskytte de kritiske systemene eller identifisere egnede testsystemer(som reflekterer kritiske feltsystemer) og strategisk redusere risiko?
og mens vi bygger disse aktivaprofilene, må vi inkludere så mye informasjon som mulig om eiendelene utover IP, Mac-adresse og OS-versjon. Informasjon som installert programvare, brukere / konto, porter, tjenester, registerinnstillinger, minst privilegiekontroller, av, hvitelisting og backup status etc. Denne typen informasjonskilder øker vår evne til nøyaktig å prioritere og strategisere våre handlinger når ny risiko oppstår. Vil du ha bevis? Ta en titt på den vanlige analysestrømmen som tilbys nedenfor. Hvor vil du få dataene til å svare på spørsmålene på de ulike stadiene? Tribal kunnskap? Instinkt? Hvorfor ikke data?
Automatiser utbedring av programvarepatching
en annen programvarepatchingutfordring er distribusjonen og forberedelsen til å distribuere oppdateringer (eller kompenserende kontroller) til endepunktene. En av DE mest tidkrevende oppgavene I ot patch management er prep-arbeidet. Det inkluderer vanligvis å identifisere målsystemer, konfigurere oppdateringen distribusjon, feilsøking når de mislykkes eller skanning først, skyve oppdateringen, og re-skanning for å fastslå suksess.
men hva om, for eksempel, neste gang en risiko Som BlueKeep dukket opp, kan du forhåndslaste filene dine på målsystemene for å forberede deg på de neste trinnene? Du og ditt mindre, mer smidige ot-sikkerhetsteam kan strategisk planlegge hvilke industrisystemer du rullet patchoppdateringer til første, andre og tredje basert på en rekke faktorer i dine robuste ressursprofiler som ressursplassering eller kritikk.
tenk deg Om patchadministrasjonsteknologien ikke krever en skanning først, men allerede hadde kartlagt patchen til eiendeler i omfang, og etter hvert som du installerte dem (enten eksternt for lav risiko eller personlig for høy risiko), bekreftet disse oppgavene deres suksess og reflekterte den fremgangen i ditt globale dashbord?
for alle høyrisikoaktivaene dine som du ikke kan eller ikke vil lappe akkurat nå, kan du i stedet opprette en port -, tjeneste-eller bruker – /kontoendring som en ad hoc-kompenseringskontroll. Så for et sikkerhetsproblem som BlueKeep, kan du deaktivere eksternt skrivebord eller gjestekontoen. Denne tilnærmingen umiddelbart og reduserer nåværende risiko betydelig, og gir også mer tid til å forberede seg på den eventuelle oppdateringen. Dette bringer meg til ‘fall back’ handlinger av hva du skal gjøre når patching ikke er et alternativ-kompenserende kontroller.
Hva er kompenserende kontroller?
Kompenserende kontroller Er ganske enkelt handlinger og sikkerhetsinnstillinger du kan og bør distribuere i stedet for (eller heller så vel som) patching. De distribueres vanligvis proaktivt (hvor det er mulig), men kan distribueres i en hendelse eller som midlertidige beskyttelsesforanstaltninger som deaktivering av eksternt skrivebord mens du lapper For BlueKeep, som jeg utvider i casestudien på slutten av denne bloggen.
Identifiser og bruk kompenseringskontroller i OT-sikkerhet
Kompenseringskontroller tar mange skjemaer fra programvitelisting og holder antivirusprogrammet oppdatert. Men i dette tilfellet vil jeg fokusere PÅ ICS endpoint management som en viktig støttekomponent i ot patch management.
Kompenserende kontroller kan og bør brukes både proaktivt og situasjonelt. Det ville ikke være noen overraskelse for NOEN I ot cyber security å oppdage sovende administratorkontoer og unødvendig eller ubrukt programvare installert på endepunkter. Det er heller ingen hemmelighet at beste praksis system herding prinsipper er ikke på langt nær så universell som vi ønsker.
for å virkelig beskytte VÅRE OT-systemer, må vi også herde våre dyrebare eiendeler. En sanntids, robust ressursprofil gjør det mulig for industrielle organisasjoner å nøyaktig og effektivt rydde ut lavthengende frukt (dvs. sovende brukere, unødvendig programvare og systemherdingsparametere) for å redusere angrepsflaten betydelig.
i den uheldige hendelsen, har vi en voksende trussel (Som BlueKeep) legge midlertidige kompenserende kontroller er gjennomførbart. En rask case studie for å markere poenget mitt:
- BlueKeep sårbarhet er utgitt.
- det sentrale teamet deaktiverer umiddelbart eksternt skrivebord på alle feltressurser og e-postfeltteam som krever at spesifikke forespørsler på system-for-system-basis for eksternt skrivebordstjeneste skal aktiveres i risikoperioden.
- Sentralt team forhåndslaster oppdateringsfiler på alle eiendeler i omfang – ingen handling, bare forbered deg.
- det sentrale teamet samles for å bestemme den mest fornuftige handlingsplanen etter aktivakritikalitet, plassering, tilstedeværelse eller fravær av kompenserende kontroller (dvs.en kritisk risiko på en høy effekt eiendel som mislyktes sin siste backup går til toppen av listen. En lav effekt ressurs med hvitelisting i kraft og en nylig god full backup kan sannsynligvis vente).
- Utrulling Av Oppdateringer begynner, og fremdriften oppdateres live i global rapportering.
- DER det er nødvendig, ER OT-teknikere på konsollen som overvåker patch-distribusjonen.
- tidsplanen og kommunikasjonen av dette behovet er fullt planlagt og prioritert av dataene som brukes av sentralteamet.
Dette er hvordan ot patch management bør håndteres. Og flere og flere organisasjoner begynner å sette denne typen program på plass.
Vær proaktiv med kompenserende kontroller
ICS patch management er vanskelig, ja, men bare å gi opp å prøve er heller ikke et godt svar. Med litt framsyn er det enkelt å gi de tre kraftigste verktøyene for enklere og mer effektiv patching og / eller kompenserende kontroller. Innsikt viser deg hva du har, hvordan det er konfigurert, og hvor viktig det er for deg. Kontekst lar deg prioritere (første forsøk på å lappe-andre lar deg vite hvordan og hvor du skal bruke kompenserende kontroller). Handlingen lar deg korrigere, beskytte, avlede osv. Å bare stole på overvåking er å innrømme at du forventer brann og kjøpe flere røykvarslere kan minimere skaden. Hvilken tilnærming tror du din organisasjon foretrekker?