i denne artikkelen diskuterer vi den første fasen i kompilatordesign hvor høyt inngangsprogram konverteres til en sekvens av tokens. Denne fasen er kjent Som Leksikalsk Analyse I Kompilatordesign.
Innholdsfortegnelse:
- Definisjoner For Leksikalsk Analyse
- Et eksempel På Leksikalsk Analyse
- Arkitektur av leksikalsk analysator
- Regulære Uttrykk
- Endelig Automat
- Forholdet mellom regulære uttrykk og endelig automat
- Lengste Samsvarsregel
- Leksikalske feil
- feilgjenopprettingsordninger
- Behov For Leksikalske Analysatorer
Leksikalsk Analyse Er Prosessen Med Å Konvertere En Sekvens Av Tegn Fra Et Kildeprogram Som Tas Som Inngang Til En Sekvens Av Tokens.
en lex er et program som genererer leksikalske analysatorer.
en leksikalsk analysator/lexer / scanner er et program som utfører leksikalsk analyse.
rollene til leksikalsk analysator medfører;
- Lesing av inndata tegn fra kildeprogrammet.
- Korrelasjon av feilmeldinger med kildeprogrammet.
- Striping mellomrom og kommentarer fra kildeprogrammet.
- Utvidelsesmakroer hvis de finnes i kildeprogrammet.
- Angi identifiserte tokens til symboltabell.
Lexeme er en forekomst av et token, det vil si en sekvens av tegn som er inkludert i kildeprogrammet i henhold til det matchende mønsteret til et token.
Et eksempel, Gitt uttrykket;
c = a + b * 5
lexemene og tokenene er;
| Lexemer | Polletter |
|---|---|
| c | identifikator |
| = | oppgave symbol |
| en | identifikator |
| + | +(tillegg symbol) |
| b | identifikator |
| * | *(multiplikasjonssymbol) |
| 5 | 5(antall) |
sekvensen av tokens produsert av den leksikalske analysatoren gjør det mulig for parseren å analysere syntaksen til en programmeringsspråk.
et token er en gyldig sekvens av tegn gitt av et lexeme, det behandles som en enhet i grammatikken til programmeringsspråket.
i et programmeringsspråk kan dette omfatte;
- Nøkkelord
- Operatorer
- Tegnsymboler
- Konstanter
- Identifikatorer
- Tall
et mønster er en regel som samsvarer med en sekvens av tegn(lexemer) som brukes av token. Det kan defineres av regulære uttrykk eller grammatikkregler.
et eksempel På Leksikalsk Analyse
Kode
#include<iostream>// exampleint main(){ int a, b; a = 7; return 0;}Tokens
| Lexemer | Polletter |
|---|---|
| int | nøkkelord |
| hoved | søkeord |
| ( | operatør |
| ) | operatør |
| { | operatør |
| int | nøkkelord |
| en | identifikator |
| , | operatør |
| b | identifikator |
| ; | operatør |
| en | identifikator |
| = | oppgave symbol |
| 10 | 10(antall) |
| ; | operatør |
| retur | nøkkelord |
| 0 | 0(antall) |
| ; | operatør |
| } | operatør |
Ikke Tokens
| Skriv | Polletter |
|---|---|
| preprosessordirektivet | #include<iostream> |
| kommentar | // eksempel |
prosessen med leksikalsk analyse består av to trinn.
- Skanning-dette innebærer lesing av inndatategnog fjerning av mellomrom og kommentarer.
- Tokenisering – dette er produksjonen av tokens som utgang.
Arkitektur av leksikalsk analysator
den leksikalske analysatorens hovedoppgave er å skanne hele kildeprogrammet og identifisere tokens en etter en.
Skannere er implementert for å produsere tokens når forespurt av parseren.

Trinn:
- «få neste token» sendes fra parseren til den leksikalske analysatoren.
- den leksikalske analysatoren skanner inngangen til «neste token» er plassert.
- token returneres til parseren.
Regulære Uttrykk
vi bruker regulære uttrykk for å uttrykke begrensede språk ved å definere mønstre for et endelig sett med symboler.
Grammatikk definert av regulære uttrykk er kjent som regulær grammatikk, og språket definert av regulær grammatikk er kjent som regulær språk.
det er algebraiske regler som følges av regulære uttrykk som brukes til å manipulere regulære uttrykk i ekvivalente former.
Operasjoner.
Union av to språk A og B er skrevet som
A U B = {s | s er I a eller s er I B}
Sammenkobling av to språk A og B er skrevet som
AB = {ss | s er I A og s er I B}
kleen-lukningen Av et språk A er skrevet som
A* = som er null eller flere forekomster av språk a.
notater.
hvis x Og y er regulære uttrykk som betegner språk A (x) og b (y) da;
(x) er et regulært uttrykk som betegner a(x).
Union (x) / (y) er et regulært uttrykk som betegner a (x) B (y).
Sammenkobling (x) (y) er et regulært uttrykk denting A (x) B (y).
Kleen closure (x) * er et regulært uttrykk som betegner(a (x))*
Forrang og assosiativitet.
* sammenkobling .’og / (rør) er igjen assosiative.
Kleen closure * har høyeste prioritet.
Sammenkobling (.) følger i forrang.
(pipe) / har den laveste forrang.
Representerer gyldige tokens av et språk i regulære uttrykk.
X Er et regulært uttrykk, derfor;
- x * representerer null eller flere forekomster av x.
- x+ representerer en eller flere forekomster av x, dvs. {x, xx, xxx}
- x? representerer høyst en forekomst av x ie {x}
- representerer alle små bokstaver på engelsk.
- representer alle store bokstaver på engelsk.
- representerer alle naturlige tall.
Representerer forekomst av symboler ved hjelp av regulære uttrykk
Letter = Eller
Siffer = Eller|0|1|2|3|4|5|6|7|8|9
Sign =
Representerer språk tokens ved hjelp av regulære uttrykk.
Desimal = (tegn)?(siffer)+
Identifier = (letter) (letter | siffer) *
Finite Automata
dette er kombinasjonen av fem Tuples (Q, Σ, q0, qf, δ) med fokus på tilstander og overganger gjennom inngangssymboler.
den gjenkjenner mønstre ved å ta symbolstrengen som inngang og endrer tilstanden tilsvarende.
den matematiske modellen for endelig automat består av;
- Endelig sett med stater(Q)
- Endelig sett med inngangssymboler(Σ)
- en startstat(q0)
- Sett med endelige stater(qf)
- Overgangsfunksjon(δ)
Endelig automat brukes i leksikalsk analyse for å produsere tokens i form av identifikatorer, søkeord og konstanter fra inngangsprogrammet.
Endelig automat mater den regulære uttrykkstrengen og tilstanden endres for hver bokstav.
hvis inngangen er behandlet, når automata endelig tilstand og godtas ellers blir den avvist.
Konstruksjon Av Endelig Automat
La L (r) være et vanlig språk av noen endelig automat F (A).
Derfor;
- Stater: Sirkler vil representere FA-statene og navnene deres er skrevet inne i sirklene.
- Startstatus: dette er tilstanden der automaten starter. Det vil ha en pil som peker mot den.
- Mellomliggende tilstander: Disse har to piler, en peker på den og en annen peker ut fra mellomliggende tilstander.
- Endelig Tilstand: Automata forventes å være i endelig tilstand når inngangsstrengen er analysert vellykket og representert av doble sirkler, ellers blir inngangen avvist. Det kan inneholde et merkelig antall piler som peker mot det og et jevnt tall som peker ut fra det, det vil si
odd arrows = even arrows + 1. - Overgang: når et ønsket symbol er funnet i inngangen, vil overgang fra en tilstand til en annen tilstand skje. Automaten går enten til neste tilstand eller vedvarer.
en rettet pil vil vise bevegelsen fra en tilstand til en annen mens en pil peker mot måltilstanden.
hvis automaten forblir i samme tilstand, trekkes en pil som peker fra en tilstand til seg selv.
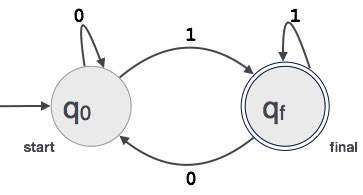
Et eksempel; Anta at EN 3-sifret binær verdi som slutter på 1 er akseptert AV FA.
Deretter FA = {Q(q0, qf), Σ(0,1), q0, qf, δ}
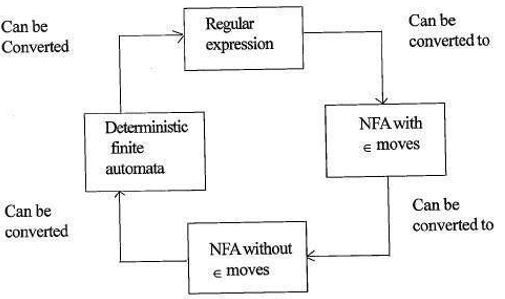
Forholdet mellom regulære uttrykk og endelig automat
forholdet mellom regulære uttrykk og endelig automat er som følger;
figuren nedenfor viser at det er enkelt å konvertere;
- Regulære uttrykk til Ikke-deterministisk endelig automat(NFA) med ∈
- Ikke-Deterministisk endelig automat med ∈ trekk til uten ∈ trekk
- Ikke-Deterministisk endelig automat uten ∈ trekk til Deterministisk Endelig Automat(DFA).
- Deterministisk Endelig Automat Til Regulært uttrykk.
En Lex vil akseptere regulære uttrykk som input, og returnere et program som simulerer en endelig automat å gjenkjenne regulære uttrykk.
derfor vil lex kombinere strengmønstergenerering (regulære uttrykk som definerer strengene av interesse for lex) og strengmønstergjenkjenning (en endelig automat som gjenkjenner strengene av interesse).
Lengste Kampregel
det står at lexeme skannet skal bestemmes ut fra den lengste kampen blant alle tilgjengelige tokens.
dette brukes Til å løse tvetydigheter når du bestemmer neste token i inngangsstrømmen.
under analyse av kildekoden vil den leksikalske analysatoren skanne kodebrev for brev, og når en operatør, spesialsymbol eller mellomrom oppdages, bestemmer det om et ord er fullført.
Eksempel:
int intvalue;mens skanning ovenfor, analysatoren kan ikke avgjøre om ‘ int ‘ er et søkeord int eller prefikset av identifikator intvalue.
Regelprioritet brukes der et søkeord vil bli prioritert over brukerinngang, noe som betyr at analysatoren i eksemplet ovenfor vil generere en feil.
Leksikalske feil
en leksikalsk feil oppstår når en tegnsekvens ikke kan skannes til et gyldig token.
disse feilene kan skyldes feilstaving av identifikatorer, nøkkelord eller operatører.
Generelt, selv om svært uvanlige leksikalske feil er forårsaket av ulovlige tegn i et token.
Feil kan være;
- Stavefeil.
- Transponering av to tegn.
- Ulovlige tegn.
- Overskrider lengden på identifikator eller numeriske konstanter.
- Erstatning av et tegn med feil tegn
- Fjerning av et tegn som skal være til stede.
gjenoppretting av Feil innebærer;
- Fjerne ett tegn fra den gjenværende inngangen
- Transponere to tilstøtende tegn
- Slette ett tegn fra den gjenværende inngangen
- Sette inn manglende tegn i den gjenværende inngangen
- Erstatte et tegn med et annet tegn.
- Ignorerer påfølgende tegn til et juridisk token er dannet (panic mode recovery).
Feilgjenoppretting ordninger
Panikk modus utvinning.
i denne feilgjenopprettingsordningen slettes uovertruffen mønstre fra gjenværende inngang til den leksikalske analysatoren kan finne et godt formet token i begynnelsen av gjenværende inngang.
Enklere implementering er en fordel for denne tilnærmingen.
det har begrensningen at en stor mengde inngang hoppes over uten å sjekke for eventuelle ekstra feil.
Lokal Korreksjon.
Når en feil oppdages ved et punkt innsetting / sletting og / eller erstatning operasjoner utføres inntil en godt formet tekst er oppnådd.
analysatoren startes på nytt med den resulterende nye teksten som inngang.
global korreksjon.
det er en forbedret panic mode recovery foretrukket når lokal korreksjon mislykkes.
Det har høye krav til tid og plass, derfor er det ikke implementert praktisk.
Behov for leksikalske analysatorer
- forbedret kompilatoreffektivitet – spesialiserte bufferteknikker for å lese tegn øker kompilatorens prosess.
- Enkel kompilatordesign-fjerning av hvite mellomrom og kommentarer vil muliggjøre effektive syntaktiske konstruksjoner for syntaxanalysatoren.
- Kompilatorportabilitet – bare skanneren kommuniserer med den eksterne verden.
- Spesialisering – spesialiserte teknikker kan brukes til å forbedre den leksikalske analyseprosessen
Problemer med leksikalsk analyse
- Lookahead
gitt en inngangsstreng, leses tegn fra venstre til høyre en etter en.
for å avgjøre om et token er ferdig eller ikke, må vi se på neste tegn.
Eksempel: Er ‘ = ‘ en oppdragsoperator eller det første tegnet i ‘==’ operator.
Lookahead hopper over tegn i inngangen til et godt formet token er funnet, dette viser at look ahead ikke kan fange betydelige feil bortsett fra enkle feil som ulovlige symboler. - Tvetydigheter
programmene skrevet med lex vil akseptere ambigous spesifikasjoner en derfor velge den lengste kampen og når flere uttrykk matche input enten den lengste kampen er foretrukket eller den første regelen blant samsvarende regler er prioritert. - Reserverte Søkeord
Enkelte språk har reserverte ord Som ikke er reservert i andre programmeringsspråk, for eksempel elif er et reservert ord i python, men Ikke I c. - Kontekstavhengighet
Eksempel:
Gitt setningen DO 10 l = 10.86, DO10l er en identifikator og DO er ikke et søkeord.
og gitt setningen DO 10 l = 10, 86, DO er et søkeord
Slike uttalelser vil kreve betydelig titt fremover for oppløsning.
Programmer
- brukes av kompilatorer opprette overholdt binære kjørbare fra analysert kode.
- brukes av nettlesere til å formatere OG vise en nettside som er analysert HTML, CSS og java script.
med denne artikkelen På OpenGenus må du ha en sterk ide Om Leksikalsk Analyse i Kompilatordesign.