w tym artykule omówimy pierwszą fazę projektowania kompilatorów, w której program wejściowy wysokiego poziomu jest konwertowany na sekwencję tokenów. Ta faza jest znana jako analiza leksykalna w projektowaniu kompilatorów.
spis treści:
- Definicje Do Analizy leksykalnej
- przykład analizy leksykalnej
- Architektura analizatora leksykalnego
- wyrażenia regularne
- automaty skończone
- zależność między wyrażeniami regularnymi a automatami skończonymi
- najdłuższa reguła dopasowania
- Błędy leksykalne
- Schematy odzyskiwania błędów
- potrzeba analizatorów leksykalnych
- potrzeba analizatorów leksykalnych
analiza leksykalna to proces konwersji sekwencji znaków z programu źródłowego, który jest pobierany jako Wejście do sekwencji tokenów.
lex to program generujący analizatory leksykalne.
analizator leksykalny / lexer / scanner to program, który wykonuje analizę leksykalną.
rola analizatora leksykalnego;
- odczyt znaków wejściowych z programu źródłowego.
- korelacja komunikatów o błędach z programem źródłowym.
- usuwanie białych spacji i komentarzy z programu źródłowego.
- makra rozszerzeń, jeśli znajdują się w programie źródłowym.
- wprowadzanie zidentyfikowanych tokenów do tabeli symboli.
Lexeme jest instancją tokena, czyli sekwencją znaków zawartych w programie źródłowym zgodnie ze wzorem dopasowania tokena.
przykład, biorąc pod uwagę wyrażenie;
c = A + b * 5
leksemami i tokenami są;
| Lexemes | tokeny |
|---|---|
| identyfikator c | |
| = | symbol przypisania |
| identyfikator a | |
| + | +(symbol dodawania) |
| identyfikator b | |
| * | *(symbol mnożenia) |
| 5 | 5(Liczba) |
Sekwencja tokenów wytwarzanych przez analizator leksykalny umożliwia parserowi analizę składni język programowania.
token jest prawidłowym ciągiem znaków podanych przez leksem, jest traktowany jako jednostka w gramatyce języka programowania.
w języku programowania może to obejmować;
- słowa kluczowe
- operatory
- symbole interpunkcyjne
- stałe
- identyfikatory
- liczby
wzorzec jest regułą dopasowaną przez ciąg znaków(leksemów) używany przez token. Można go zdefiniować za pomocą wyrażeń regularnych lub reguł gramatycznych.
przykład analizy leksykalnej
Kod
#include<iostream>// exampleint main(){ int a, b; a = 7; return 0;}tokeny
| Lexemes | tokeny |
|---|---|
| int | słowo kluczowe |
| główna | słowo kluczowe |
| ( | operator |
| ) | operator |
| { | operator |
| int | słowo kluczowe |
| identyfikator a | |
| , | operator |
| b | |
| ; | operator |
| identyfikator a | |
| = | symbol przypisania |
| 10 | 10(liczba) |
| ; | operator |
| powrót | słowo kluczowe |
| 0 | 0(Liczba) |
| ; | operator |
| } | operator |
Non tokeny
| Typ | tokeny |
|---|---|
| dyrektywa preprocesorowa | #include<iostream> |
| skomentuj | / / przykład |
proces analizy leksykalnej składa się z dwóch etapów.
- skanowanie – polega na odczytywaniu znaków wejściowych oraz usuwaniu spacji i komentarzy.
- tokenizacja-jest to produkcja tokenów jako wyjście.
Architektura analizatora leksykalnego
głównym zadaniem analizatora leksykalnego jest skanowanie całego programu źródłowego i identyfikowanie tokenów jeden po drugim.
skanery są implementowane do produkcji tokenów na żądanie parsera.

kroki:
- „get next token” jest wysyłany z parsera do analizatora leksykalnego.
- analizator leksykalny skanuje dane wejściowe, aż znajdzie się „następny token”.
- token jest zwracany do parsera.
wyrażenia regularne
używamy wyrażeń regularnych do wyrażania skończonych języków poprzez definiowanie wzorców dla skończonego zestawu symboli.
Gramatyka zdefiniowana przez wyrażenia regularne jest znana jako gramatyka regularna, a język zdefiniowany przez gramatykę regularną jest znany jako język regularny.
istnieją reguły algebraiczne przestrzegane przez wyrażenia regularne używane do przekształcania wyrażeń regularnych w równoważne formy.
połączenie dwóch języków a i B jest zapisane jako
a U b = {s | S jest w A lub s jest w B}
połączenie dwóch języków a i B jest zapisane jako
AB = {ss | S jest w a i s jest w B}
zamknięcie języka a jest zapisane jako
a* = co oznacza zero lub więcej wystąpień języka A.
Jeśli x i y są wyrażeniami regularnymi oznaczającymi języki a(x) i B(y), to
(x) jest wyrażeniem regularnym oznaczającym a(x).
Union (x| / (y) jest wyrażeniem regularnym oznaczającym a (x) B (y).
konkatenacja (x) (y) jest wyrażeniem regularnym oznaczającym A (x) B (y).
Kleen closure (x) * jest wyrażeniem regularnym oznaczającym (a (x)) *
.
* ” konkatenacja .’i / (pipe) pozostają asocjacyjne.
Kleen closure * ma najwyższy priorytet.
konkatenacja (.) ma pierwszeństwo.
(pipe) | ma najniższy priorytet.
reprezentowanie ważnych tokenów języka w wyrażeniach regularnych.
X jest wyrażeniem regularnym, dlatego;
- x * reprezentuje zero lub więcej wystąpień x.
- x+ reprezentuje jedno lub więcej wystąpień x, czyli{x, xx, xxx}
- x? reprezentuje co najwyżej jedno wystąpienie x ie {x}
- reprezentuje wszystkie małe litery alfabetu w języku angielskim.
- reprezentują wszystkie wielkie litery alfabetu w języku angielskim.
- reprezentują wszystkie liczby naturalne.
reprezentowanie występowania symboli przy użyciu wyrażeń regularnych
Letter = lub
Digit = lub|0|1|2|3|4|5|6|7|8|9
znak =
reprezentujący tokeny językowe za pomocą wyrażeń regularnych.
Decimal = (sign)?(cyfra)+
identyfikator = (litera) (litera | cyfra)*
automaty skończone
jest to kombinacja pięciu krotek (Q, Σ, q0, qf, δ) skupiających się na stanach i przejściach poprzez symbole wejściowe.
rozpoznaje wzorce, przyjmując ciąg znaków jako dane wejściowe i odpowiednio zmienia swój stan.
model matematyczny automatów skończonych składa się z;
- skończony zbiór stanów(Q)
- skończony zbiór symboli wejściowych(Σ)
- jeden stan początkowy(q0)
- zbiór stanów końcowych(qf)
- funkcja przejścia (δ)
automaty skończone są wykorzystywane w analizie leksykalnej do wytwarzania tokenów w postaci identyfikatorów, słów kluczowych i stałych z programu wejściowego.
Automata skończona podaje ciąg wyrażeń regularnych, a stan jest zmieniany dla każdego literału.
jeśli Dane wejściowe zostaną przetworzone pomyślnie, automaty osiągną stan końcowy i zostaną zaakceptowane, w przeciwnym razie zostaną odrzucone.
Budowa automatów skończonych
niech L(r) będzie językiem regularnym przez niektóre automaty skończone F(A).
;
- Stany: okręgi będą reprezentować Stany FA, a ich nazwy są zapisane wewnątrz okręgów.
- Stan startowy: jest to stan, w którym rozpoczyna się automat. Będzie miał strzałkę skierowaną w jego stronę.
- Stany pośrednie: mają dwie strzałki, jedna wskazująca na nią, a druga wskazująca ze Stanów pośrednich.
- Stan Końcowy: Oczekuje się, że automaty będą w końcowym stanie, gdy łańcuch wejściowy został pomyślnie przetworzony i reprezentowany przez podwójne okręgi, w przeciwnym razie wejście zostanie odrzucone. Może zawierać nieparzystą liczbę strzałek skierowanych w jego stronę i parzystą liczbę wskazującą od niego, to znaczy
nieparzyste strzałki = parzyste strzałki + 1. - Przejście: gdy na wejściu znajduje się pożądany symbol, nastąpi przejście z jednego stanu do drugiego. Automat albo przechodzi do następnego stanu, albo trwa.
skierowana strzałka wyświetli ruch z jednego stanu do drugiego, podczas gdy strzałka wskazuje na stan docelowy.
jeśli automaty pozostają w tym samym stanie, rysowana jest strzałka wskazująca od stanu do samego siebie.
przykład; załóżmy, że 3-cyfrowa wartość binarna kończąca się na 1 jest akceptowana przez FA.
Then FA = {Q(q0, qf), Σ (0,1), q0, qf, δ}
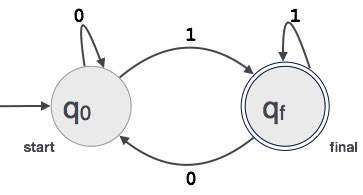
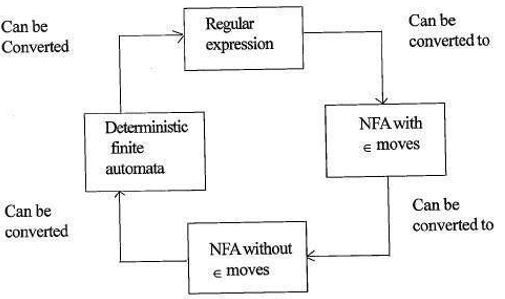
zależność między wyrażeniami regularnymi a automatami skończonymi
zależność między wyrażeniem regularnym a automatami skończonymi jest następująca;
poniższy rysunek pokazuje, że łatwo jest przekonwertować;
- wyrażenia regularne do niedeterministycznych automatów skończonych (NFA) z ruchami∈.
- niedeterministyczne automaty skończone z ∈ przesuwa się do bez moves przesuwa
- niedeterministyczne automaty skończone bez ∈ przesuwa się do deterministycznych automatów skończonych(Dfa).
- deterministyczne automaty skończone do wyrażenia regularnego.
Lex zaakceptuje wyrażenia regularne jako dane wejściowe i zwróci program, który symuluje skończony automat do rozpoznawania wyrażeń regularnych.
w związku z tym, lex będzie łączył generowanie wzorców łańcuchowych (wyrażenia regularne definiujące łańcuchy zainteresowania lex) i rozpoznawanie wzorców łańcuchowych (skończony automat, który rozpoznaje łańcuchy zainteresowania).
reguła najdłuższego dopasowania
stwierdza, że skanowany leksem powinien być określony na podstawie najdłuższego dopasowania spośród wszystkich dostępnych tokenów.
jest to używane do rozwiązywania niejasności przy podejmowaniu decyzji o następnym tokenie w strumieniu wejściowym.
podczas analizy kodu źródłowego analizator leksykalny skanuje kod litera po literze i po wykryciu operatora, specjalnego symbolu lub spacji decyduje, czy słowo jest kompletne.
przykład:
int intvalue;podczas skanowania powyższego analizator nie może określić, czy 'int’ jest słowem kluczowym int, czy prefiksem identyfikatora intvalue.
stosuje się priorytet reguły, w której słowo kluczowe będzie miało pierwszeństwo przed wpisem użytkownika, co oznacza, że w powyższym przykładzie analizator wygeneruje błąd.
Błędy leksykalne
błąd leksykalny występuje, gdy sekwencja znaków nie może zostać przeskanowana do ważnego tokena.
błędy te mogą być spowodowane błędnym zapisem identyfikatorów, słów kluczowych lub operatorów.
generalnie, choć bardzo rzadkie Błędy leksykalne są spowodowane przez nielegalne znaki w tokenie.
błędy mogą być;
- błąd ortograficzny.
- Transpozycja dwóch znaków.
- nielegalne znaki.
- przekroczenie długości stałych identyfikatorów lub liczb.
- zastąpienie znaku nieprawidłowym znakiem
- Usunięcie znaku, który powinien być obecny.
odzyskiwanie błędów;
- usunięcie jednego znaku z pozostałego wejścia
- transponowanie dwóch sąsiednich znaków
- usuwanie jednego znaku z pozostałego wejścia
- Wstawianie brakującego znaku do pozostałego wejścia
- zastąpienie znaku innym znakiem.
- ignorowanie kolejnych znaków do momentu utworzenia legalnego tokena (odzyskiwanie trybu panic).
Schematy odzyskiwania błędów
odzyskiwanie trybu paniki.
w tym schemacie odzyskiwania błędów niezrównane wzorce są usuwane z pozostałych danych wejściowych, dopóki analizator leksykalny nie znajdzie dobrze uformowanego tokenu na początku pozostałych danych wejściowych.
łatwiejsza implementacja jest zaletą takiego podejścia.
ma ograniczenie, że duża ilość danych wejściowych jest pomijana bez sprawdzania dodatkowych błędów.
Korekta Lokalna.
w przypadku wykrycia błędu w punkcie operacje wstawiania/usuwania i/lub zastępowania są wykonywane do momentu uzyskania dobrze uformowanego tekstu.
analizator jest uruchamiany ponownie z nowym tekstem jako wejściem.
korekta globalna.
jest to ulepszone odzyskiwanie trybu paniki preferowane, gdy lokalna korekta nie powiedzie się.
ma wysokie wymagania czasowe i przestrzenne, dlatego nie jest praktycznie wdrażany.
potrzeba analizatorów leksykalnych
- Zwiększona wydajność kompilatora – specjalistyczne techniki buforowania odczytu znaków przyspieszają proces kompilatora.
- prostota projektowania kompilatora-usunięcie białych spacji i komentarzy umożliwi wydajne konstrukcje składniowe dla analizatora składni.
- przenośność kompilatora – tylko skaner komunikuje się ze światem zewnętrznym.
- specjalizacja – techniki specjalistyczne mogą być wykorzystane do usprawnienia procesu analizy leksykalnej
problemy z analizą leksykalną
- Lookahead
w przypadku ciągu wejściowego znaki są odczytywane od lewej do prawej jeden po drugim.
aby określić, czy token jest skończony, czy nie, musimy spojrzeć na następny znak.
przykład: jest ’ = 'operatorem przypisania lub pierwszym znakiem w operatorze’==’.
Lookahead pomija znaki na wejściu, dopóki nie zostanie znaleziony dobrze uformowany token, co pokazuje, że look ahead nie może wyłapać znaczących błędów, z wyjątkiem prostych błędów, takich jak nielegalne symbole. - niejednoznaczności
programy napisane za pomocą lex przyjmą niejednoznaczne specyfikacje, dlatego wybierają najdłuższe dopasowanie, a gdy wiele wyrażeń pasuje do danych wejściowych, preferowane jest najdłuższe dopasowanie lub pierwszeństwo ma pierwsza reguła wśród reguł dopasowania. - zastrzeżone słowa kluczowe
niektóre języki mają słowa zarezerwowane, które nie są zarezerwowane w innych językach programowania, np. elif jest słowem zarezerwowanym w Pythonie, ale nie w C. - zależność kontekstowa
przykład:
biorąc pod uwagę polecenie DO 10 l = 10.86, DO10l jest identyfikatorem, a DO nie słowem kluczowym.
i biorąc pod uwagę stwierdzenie DO 10 l = 10, 86, DO jest słowem kluczowym
takie stwierdzenia wymagałyby znacznego spojrzenia w przyszłość na rozdzielczość.
Aplikacje
- używane przez kompilatory tworzą zgodne binarne pliki wykonywalne z parsowanego kodu.
- używany przez przeglądarki internetowe do formatowania i wyświetlania strony internetowej, która jest analizowana w HTML, CSS i java script.
z tym artykułem w OpenGenus, musisz mieć silne pojęcie analizy leksykalnej w projektowaniu kompilatorów.