niezależność danych to cecha systemu zarządzania bazami danych (DBMS), która pozwala programistom modyfikować definicje i organizację informacji bez wpływu na programy lub aplikacje, które go używają. Taka właściwość umożliwia różnym użytkownikom dostęp i przetwarzanie tych samych danych w różnych celach, niezależnie od wprowadzonych w nich zmian.
na przykład baza danych zawierająca informacje o pacjencie może służyć różnym celom. Dział rozliczeniowy szpitala może wykorzystać te dane do uzyskania opłat, rabatów i szczegółów ubezpieczenia pacjentów. Z drugiej strony, dział usług gastronomicznych potrzebowałby tych samych danych, aby zobaczyć wymagania żywieniowe pacjentów. Sposób, w jaki każdy oddział wykorzystuje dane, nie powinien wpływać na przechowywane informacje, niezależnie od zmian, którym ulegają, takich jak miejsce przechowywania danych pacjenta lub sposób ich etykietowania.
inne ciekawe terminy…
- czym jest zarządzanie danymi?
- co to jest pakiet danych?
Przeczytaj więcej o „niezależności danych”
Mówiąc najprościej, niezależność danych pomaga administratorom oddzielić informacje od aplikacji i programów, które ich używają. W związku z tym programiści nie muszą modyfikować swoich kodów źródłowych za każdym razem, gdy wprowadzane są zmiany w charakterystyce danych. Ta właściwość pomaga zaoszczędzić czas i inne zasoby, a co najważniejsze, minimalizuje błędy.
gdy zagłębisz się w pytanie ” Czym jest niezależność danych?”Odnoszą się one do fizycznej i logicznej niezależności danych. Ale najpierw trzeba zapoznać się z poziomami lub schematem bazy danych, aby zrozumieć te typy.
poziomy bazy danych lub schemat
w naszym przykładzie bazy danych pacjentów różne poziomy bazy danych wyglądałyby następująco:
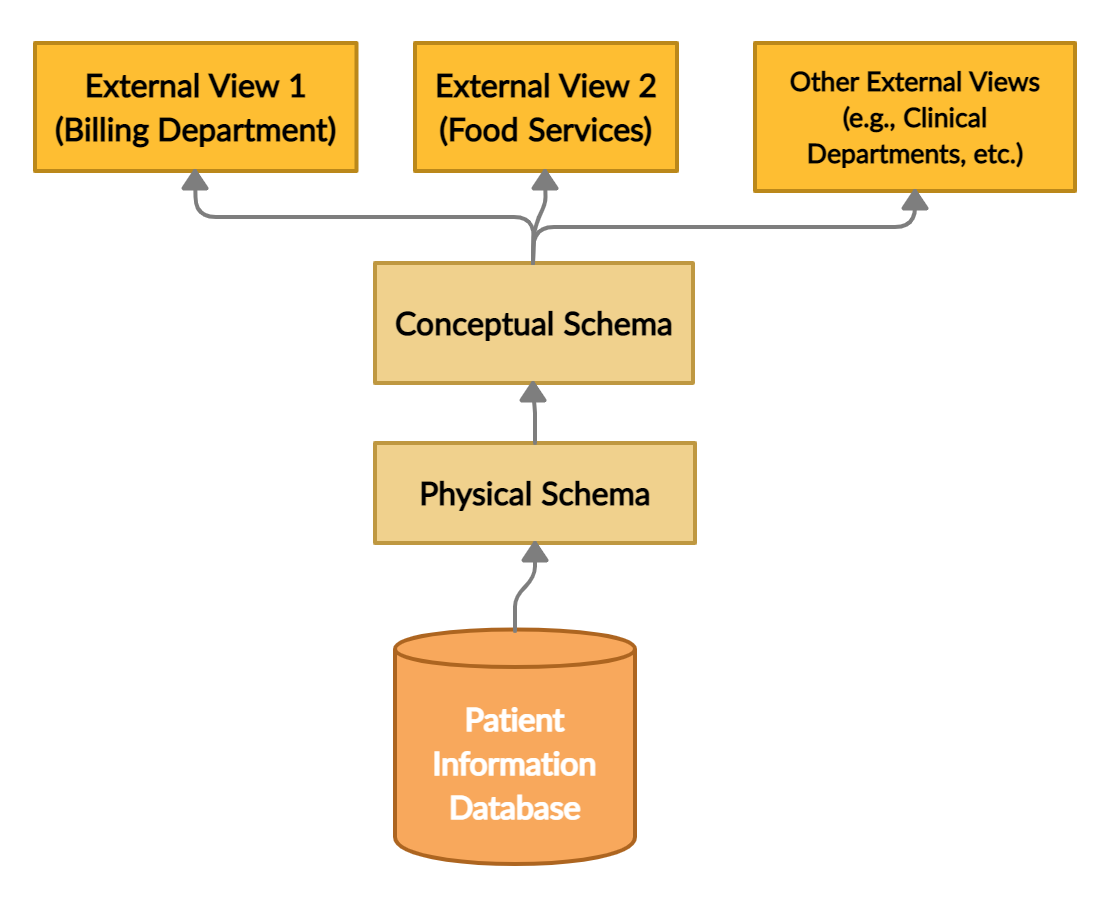
pierwszy poziom to schemat fizyczny, który odnosi się do sposobu przechowywania, indeksowania i znakowania danych. Następny jest poziom pojęciowy, warstwa, która zawiera informacje lub pojęcia i ich relacje ze sobą. Przykładowe są leki, zabiegi i inne przedmioty szpitalne używane przez pacjentów oraz ich ceny.
ostatni jest poziom zewnętrzny, zwany również „schematem widoku.”Jest to część bazy danych, którą dany użytkownik może być najbardziej zainteresowany. Na przykład dział obsługi gastronomicznej szpitala byłby zainteresowany informacjami na temat diagnoz pacjentów, potrzeb żywieniowych i liczby pokoi, by wymienić tylko kilka. Z drugiej strony, dział rozliczeniowy byłby zainteresowany ubezpieczeniem pacjentów, rabatem i podobnymi szczegółami. Zauważ, że pojedyncza baza danych może być wyświetlana na zewnątrz w więcej niż jeden sposób.
rodzaje niezależności danych
teraz, gdy znasz różne sposoby przeglądania bazy danych, odpowiemy dalej „Czym jest niezależność danych?”poprzez zrozumienie jej dwóch typów.
niezależność danych fizycznych
niezależność danych fizycznych odnosi się do możliwości zmiany struktury fizycznej danych bez wpływu na poziom koncepcyjny. Zmiany fizyczne obejmują użycie nowego urządzenia pamięci masowej lub przeniesienie lokalizacji bazy danych, zmianę struktury danych lub zmianę indeksów w celu przyspieszenia pobierania danych.
baza danych pacjentów w naszym przykładzie może zostać przeniesiona z dysku C na dysk D, ale schemat koncepcyjny i widoki zewnętrzne pozostają niezmienione ze względu na niezależność danych fizycznych.
logiczna niezależność danych
logiczna niezależność danych, z drugiej strony, pozwala użytkownikom na zmianę schematu koncepcyjnego bez zmiany widoków zewnętrznych. Na przykład dział rozliczeń szpitalnych może dodać kolumnę do tabeli bazy danych dla numeru polisy ubezpieczeniowej każdego pacjenta. Niezależność danych logicznych oznacza, że widok działu usług gastronomicznych i innych użytkowników nie ulega zmianie, nawet jeśli wprowadzono modyfikacje na poziomie koncepcyjnym.