w przypadku złożonych sieci składających się z chmury, hybrydowego IT, wirtualizacji, sieci pamięci masowej itp.wielopłaszczyznowe problemy z IT mogą być trudne do zidentyfikowania i zdiagnozowania. Gdy problem pojawi się, na przykład w źle działającej aplikacji lub serwerze, znalezienie głównego problemu może zająć dużo czasu. Problem może dotyczyć pamięci masowej, łączności sieciowej, dostępu użytkowników lub kombinacji zasobów i konfiguracji.
aby zbadać problem, utwórz projekty rozwiązywania problemów za pomocą pulpitu analizy wydajności (PerfStack™), który wizualnie koreluje dane historyczne z wielu produktów SolarWinds i typów jednostek w jednym widoku.
dzięki pulpitom analizy wydajności możesz wykonać następujące czynności:
- porównuj i analizuj wiele typów metrycznych w jednym widoku, w tym status, zdarzenia i statystyki.
- porównuj i analizuj metryki dla wielu podmiotów w jednym widoku, w tym węzłów, interfejsów, woluminów, aplikacji i innych.
- Koreluj dane z całej platformy Orion na jednej wspólnej linii czasu.
- wizualizuj dane hybrydowe dla lokalnie, w chmurze i wszystkiego pomiędzy.
- Udostępnij projekt rozwiązywania problemów zespołom i ekspertom, aby przejrzeć dane historyczne pod kątem problemu.
w przypadku VMAN możliwości analizy aplikacji i środowisk hybrydowych są nieograniczone:
- wizualnie przeglądaj Dane historyczne maszyn wirtualnych w swoim środowisku
- Sprawdź problemy z alokacją zasobów w środowiskach hybrydowych
- Koreluj dane w celu rozwiązywania problemów z ruchem sieciowym wysyłanym i odbieranym przez serwery wirtualne (hosty, klastry, magazyny danych i maszyny wirtualne), serwery lokalne i instancje w chmurze
poniższy przykład pokazuje, jak zidentyfikować główną przyczynę maszyna wirtualna, która ma problemy z wydajnością. W tym scenariuszu host wirtualny napotkał problem z zasobami i wydajnością do tego stopnia, że użytkownicy napotykają wolniejsze odpowiedzi i dostęp. Problem wywołał alert, który powiadomił właściciela aplikacji, który eskalował problem do administratorów systemu i sieci.
Utwórz nowy projekt rozwiązywania problemów w celu zbadania problemu, aby porównać metryki dla hosta i wszystkich powiązanych systemów środowiska wirtualnego, aby śledzić trendy i skoki użytkowania.
-
w konsoli internetowej Orion wybierz pozycję Moje pulpity nawigacyjne > Strona główna > analiza wydajności.
spowoduje to otwarcie pulpitu analizy wydajności (PerfStack) w celu tworzenia wykresów i wykresów z wykorzystaniem metryk pobranych z monitorowanych aplikacji i serwerów w palecie metryk. Każdy wykres może zawierać wiele metryk, aby bezpośrednio skorelować dane.
-
w nowym projekcie analizy kliknij Dodaj elementy.
aby rozpocząć, musisz zlokalizować i dodać maszynę wirtualną w niebezpieczeństwie. W polu wyszukiwania wprowadź syd, aby wyświetlić listę serwerów wirtualnych, które mają tę nazwę. Rozwiń i wybierz typy lub Status, aby w razie potrzeby filtrować listę.
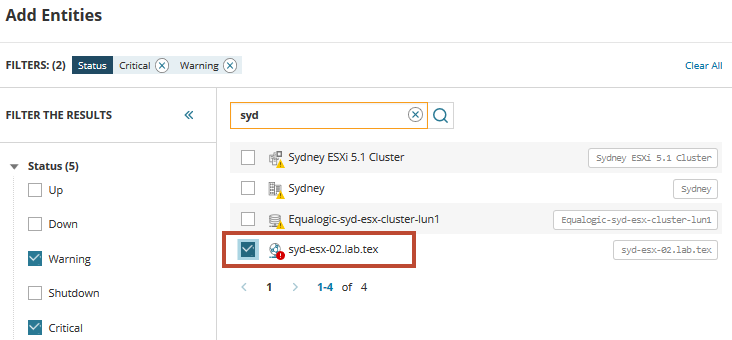
z listy znajdujemy wirtualnego hosta napotykającego problemy i wyzwalającego alerty. Wybierz hosta i dodaj go do palety metrycznych Pulpitu nawigacyjnego. Kliknij ikonę powiązanych podmiotów, aby wyświetlić wszystkie powiązane serwery i usługi z hostem.
interesują Cię wszystkie powiązane węzły, aplikacje, serwery i inne elementy tego wybranego węzła? Kliknij ikonę powiązanych podmiotów.
 wszystkie powiązane podmioty wyświetlają się w palecie metryk, zapewniając więcej opcji dla metryk, które mogą powodować problemy.
wszystkie powiązane podmioty wyświetlają się w palecie metryk, zapewniając więcej opcji dla metryk, które mogą powodować problemy.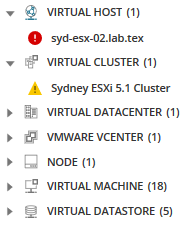
-
wybierz węzeł syd host, aby wyświetlić i wybrać metryki do przeciągnięcia i upuszczenia na pulpit nawigacyjny. Możesz przeciągnąć je na ten sam wykres, aby porównać wartości między metrykami.
aby rozpocząć badanie, wyciągnij serię wskaźników dla hosta i klastra, porównując wskaźniki, aby znaleźć skoki lub wysokie zużycie. W tym scenariuszu dodaj te parametry hosta:
- maksymalne wykorzystanie sieci
- Maksymalna Szybkość transmisji sieci
- Maksymalna szybkość odbioru sieci
- maszyny wirtualne działające
w przypadku klastra dodaj te wskaźniki:
- średnie obciążenie procesora
- średnie zużycie procesora
wykresy i wykresy wyświetlają dane i alerty z ostatnich 12 godzin pomiarów. Możesz rozszerzyć datę i godzinę, aby zobaczyć dodatkowe metryki Historyczne w trakcie alertu.
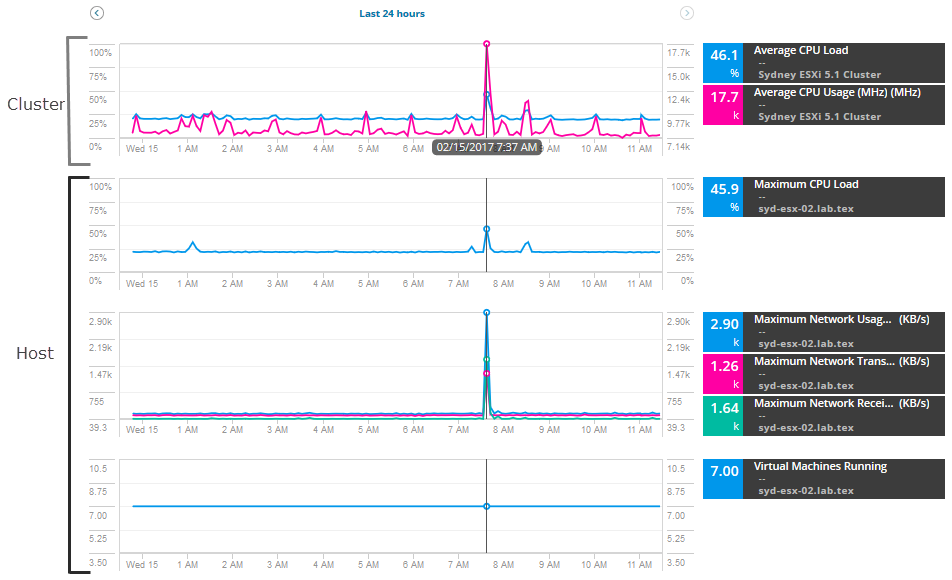
Dodaj metryki użycia maszyn wirtualnych na hoście, aby porównać wykorzystanie sieci i aktywność.
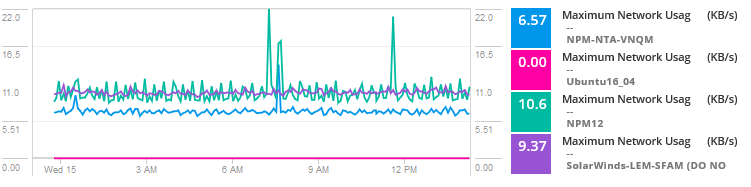
-
analizując dane, problem wygląda na hałaśliwego sąsiada dla jednej z maszyn wirtualnych zużywających zasoby i doświadczających dużego ruchu powodującego wąskie gardła i problemy z maszynami wirtualnymi współdzielącymi hosta. Zasadniczo inny serwer, usługa lub aplikacja zużywają większą przepustowość, wejścia/wyjścia dysku, procesor i inne zasoby, powodując problemy dla tej konkretnej aplikacji.
te informacje dają administratorom sieci i systemów wskazówki do dalszego badania i rozwiązywania problemów z opóźnieniami. Aby rozwiązać problem, mogą ponownie przydzielić zasoby lub przenieść aplikację o dużym zużyciu do innej lokalizacji.
-
kliknij Zapisz i nadaj projektowi nazwę.
projekt zapisuje jako pulpit nawigacyjny z wybranymi metrykami w ustawionym zakresie daty i czasu.
po zapisaniu adres URL staje się łączem do współdzielenia. Skopiuj i udostępnij link do zapisanego Pulpitu Nawigacyjnego w paragonach lub wiadomościach e-mail wysyłanych przez administratorów systemu i sieci oraz właściciela produktu. Mogą uzyskać dostęp do łącza, aby przejrzeć zebrane dane i rozwiązać problemy.
po ponownym przydziale zasobów i wprowadzeniu zmian w sieci otwórz ponownie pulpit nawigacyjny, aby zweryfikować zmiany i nowe trendy użytkowania dla ankietowanych metryk.