neste artigo, discutimos a primeira fase no design do compilador, onde o programa de entrada de alto nível é convertido em uma sequência de tokens. Esta fase é conhecida como análise Lexical no design do compilador.
Índice:
- Definições para Análise Léxica
- Um exemplo de Análise Léxica
- Arquitetura do analisador léxico
- Expressões Regulares
- Autómatos Finitos
- Relação entre expressões regulares e autómatos finitos
- Maior Partida Regra
- erros Léxicos
- recuperação de Erro esquemas
- Necessidade de analisadores lexicais
- Necessidade de analisadores lexicais
análise Léxica é o processo de converter uma seqüência de caracteres a partir de um programa fonte, que é tomado como ponto de entrada para uma sequência de tokens.
um lex é um programa que gera analisadores lexicais.
um analisador lexical / lexer / scanner é um programa que executa análise lexical.
os papéis do analisador lexical implicam;
- leitura de caracteres de entrada do programa de origem.
- correlação de mensagens de erro com o programa de origem.
- distribuição de espaços em branco e comentários do programa de origem.
- macros de Expansão se encontradas no programa de origem.
- inserindo tokens identificados na tabela de símbolos.
Lexeme é uma instância de um token, ou seja, uma sequência de caracteres incluídos no programa de origem de acordo com o padrão correspondente de um token.
um exemplo, dada a expressão;
c = a + b * 5
os lexemas e tokens são;
| Lexèmes | Tokens |
|---|---|
| c | identificador de |
| = | atribuição símbolo |
| um | identificador de |
| + | +(além de símbolo) |
| b | identificador de |
| * | *(símbolo de multiplicação) |
| 5 | 5(número) |
A seqüência de tokens produzidos pelo analisador léxico permite que o analisador para analisar a sintaxe de um linguagem.
um token é uma sequência válida de caracteres dada por um lexema, é tratada como uma unidade na gramática da linguagem de programação.
Em uma linguagem de programação isso pode incluir a;
- Palavras-chave
- Operadores
- símbolos de Pontuação
- Constantes
- Identificadores
- Números
Um padrão é uma regra de correspondência por uma seqüência de caracteres(lexèmes) usado pelo token. Pode ser definido por expressões regulares ou regras gramaticais.
Um exemplo de Análise Léxica
Código
#include<iostream>// exampleint main(){ int a, b; a = 7; return 0;}Tokens
| Lexèmes | Tokens |
|---|---|
| int | palavras-chave |
| principal | palavras-chave |
| ( | operador de |
| ) | operador de |
| { | operador de |
| int | palavras-chave |
| um | identificador de |
| , | operador de |
| b | identificador de |
| ; | operador de |
| um | identificador de |
| = | atribuição símbolo |
| 10 | 10(número) |
| ; | operador de |
| return | palavras-chave |
| 0 | 0(número) |
| ; | operador |
| } | operador de |
Não Tokens
| Tipo | Tokens |
|---|---|
| directiva de pré-processador | #include<iostream> |
| comentário | // exemplo |
O processo de análise léxica constitui de duas fases.
- digitalização-isso envolve a leitura de caracteres de input e a remoção de espaços em branco e comentários.Tokenização-esta é a produção de tokens como saída.
arquitetura do analisador lexical
a principal tarefa do analisador lexical é escanear todo o programa de origem e identificar tokens um por um.Os Scanners são implementados para produzir tokens quando solicitados pelo analisador.

passos:
- “get next token” é enviado do analisador para o analisador lexical.
- o analisador lexical verifica a entrada até que o” próximo token ” esteja localizado.
- o token é retornado ao analisador.
Expressões Regulares
usamos expressões regulares para expressar linguagens finitas definindo padrões para um conjunto finito de símbolos.A gramática definida por expressões regulares é conhecida como gramática regular e a linguagem definida pela gramática regular é conhecida como linguagem regular.Existem regras algébricas obedecidas por expressões regulares usadas para manipular expressões regulares em formas equivalentes.
operações.
União das duas línguas A e B é escrito como
A U B = {s | s é de A ou s em B}
Concatenação de duas línguas A e B é escrito como
AB = {ss | s em e s em B}
O kleen encerramento de um idioma é escrito como
A* = que é zero ou mais ocorrências de linguagem A.
Anotações.
se x e y são expressões regulares denotando linguagens a(x) e B(y) então;
(x) é uma expressão regular denotando a (x).
Union (x) / (y) é uma expressão regular que denota A(x) B (y).
concatenação (x) (y)é uma expressão regular que denota A(x) B (y).
Kleen closure (x)* é uma expressão regular denotando (a(x))*
precedência e associatividade.
*’ concatenação .’e / (pipe) são deixados associativos.
Kleen encerramento * tem a maior precedência.
concatenação (.) segue em precedência.
(pipe) | tem a menor precedência.
representando tokens válidos de um idioma em expressões regulares.
X é uma expressão regular, portanto,;
- x* representa zero ou mais ocorrência de x.
- x+ representa uma ou mais ocorrência de x, ou seja, {x, xx, xxx}
- x? representa no máximo uma ocorrência de x ie {x}
- representam todos os alfabetos minúsculos no idioma Inglês.
- representam todos os alfabetos maiúsculos no idioma Inglês.
- representam todos os números naturais.
Representando a ocorrência dos símbolos usando expressões regulares
Letra = ou
Dígito = ou|0|1|2|3|4|5|6|7|8|9
Sinal de =
Representa tokens de idioma usando expressões regulares.
Decimal = (sinal)?(dígito)+
identificador = (Letra) (Letra | dígito)*
autômatos finitos
esta é a combinação de cinco tuplas (Q, Σ, q0, qf, δ) Com foco em estados e transições por meio de símbolos de entrada.
ele reconhece padrões tomando a string de Símbolo como entrada e muda seu estado de acordo.
o modelo matemático para autômatos finitos consiste em;
- conjunto Finito de estados(Q)
- conjunto Finito de símbolos de entrada(Σ)
- Um estado inicial(q0)
- Conjunto de estados finais(qf)
- função de Transição(δ)
autómatos Finitos é utilizado na análise léxica para produzir símbolos em forma de identificadores, palavras-chave e constantes do programa de entrada.
autômatos finitos alimentam a string de expressão regular e o estado é alterado para cada literal.
se a entrada for processada com sucesso, o autômato atinge o estado final e é aceito caso contrário, é rejeitado.
construção de autômatos finitos
deixe L (r) ser uma linguagem regular por alguns autômatos finitos F (a).
portanto;
- Estados: Os círculos representarão os estados do FA e seus nomes são escritos dentro dos círculos.
- estado inicial: Este é o estado no qual o autômato é iniciado. Ele terá uma seta apontando para ele.
- estados intermediários: estes têm duas setas, uma apontando para ele e outra apontando para fora dos estados intermediários.
- Estado Final: Espera-se que os autômatos estejam no estado final quando a string de entrada tiver sido analisada com sucesso e representada por círculos duplos, caso contrário, a entrada será rejeitada. Pode conter um número ímpar de setas apontando para ele e um número par apontando para fora dele, isto é,
setas ímpares = setas pares + 1.Transição: Quando um símbolo desejado é encontrado na entrada, a transição de um estado para outro acontecerá. O autômato se move para o próximo estado ou persiste.
uma seta dirigida exibirá o movimento de um estado para outro, enquanto uma seta aponta para o estado de destino.
se o autômato permanecer no mesmo estado, uma seta apontando de um estado para si mesma é desenhada.
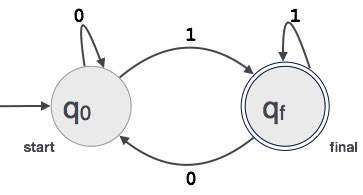
um exemplo; suponha que um valor binário de 3 dígitos que termina em 1 seja aceito por FA.
, em Seguida, FA = {P(q0, qf), Σ(0,1), q0, qf, δ}
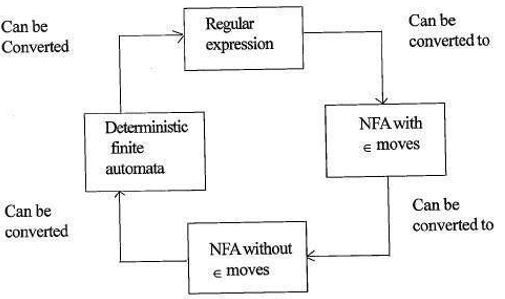
Relação entre expressões regulares e autómatos finitos
A relação entre expressões regulares e autómatos finitos é da seguinte maneira;
a figura abaixo mostra que é fácil converter;
- expressões regulares para autômatos finitos não determinísticos (NFA) com moves move.
- autômatos finitos não determinísticos com moves move para sem moves move
- autômatos finitos não determinísticos sem ∈ move para autômatos finitos determinísticos (DFA).
- autômatos finitos determinísticos para expressão Regular.
Um Lex aceitam expressões regulares como entrada e retornam um programa que simula um finitos autômato para reconhecer as expressões regulares.
portanto, lex combinará a geração de padrões de string (expressões regulares que definem as strings de interesse para lex) e o reconhecimento de padrões de string (um autômato finito que reconhece as strings de interesse).
regra de correspondência Mais Longa
afirma que o lexeme digitalizado deve ser determinado com base na correspondência mais longa entre todos os tokens disponíveis.
isso é usado para resolver ambiguidades ao decidir o próximo token no fluxo de entrada.
durante a análise do código-fonte, o analisador lexical digitalizará o código letra por letra e quando um operador, símbolo especial ou espaço em branco é detectado, ele decide se uma palavra está completa.
exemplo:
int intvalue;ao digitalizar o acima, o analisador não pode determinar se ‘int’ é uma palavra-chave int ou o prefixo do identificador intvalue.
a prioridade da regra é aplicada por meio da qual uma palavra-chave receberá prioridade sobre a entrada do usuário, o que significa que no exemplo acima o analisador gerará um erro.
erros lexicais
ocorre um erro lexical quando uma sequência de caracteres não pode ser digitalizada em um token válido.Esses erros podem ser causados por um erro ortográfico de identificadores, palavras-chave ou operadores.
geralmente, embora erros lexicais muito incomuns sejam causados por caracteres ilegais em um token.
erros podem ser;
- erro de ortografia.
- transposição de dois caracteres.
- caracteres ilegais.
- excedendo o comprimento do identificador ou das constantes numéricas.
- substituição de um caractere por um caractere incorreto
- remoção de um caractere que deve estar presente.
recuperação de Erro implica;
- a Remoção de um personagem do restante
- Transposição de dois caracteres adjacentes
- Excluir um caractere do restante
- Inserir caractere ausente no restante
- Substituição de um caractere por outro personagem.
- ignorando caracteres sucessivos até que um token legal seja formado (recuperação do modo de pânico).
esquemas de recuperação de erros
recuperação do modo de pânico.
neste esquema de recuperação de erros, padrões incomparáveis são excluídos da entrada restante até que o analisador lexical possa encontrar um token bem formado no início da entrada restante.
uma implementação mais fácil é uma vantagem para esta abordagem.
tem a limitação de que uma grande quantidade de entrada é ignorada sem verificar se há erros adicionais.
Correção Local.
quando um erro é detectado em um ponto de inserção/exclusão e/ou operações de substituição são executadas até que um texto bem formado seja alcançado.
o analisador é reiniciado com o novo texto resultante como entrada.
correção Global.
é uma recuperação de modo de pânico aprimorada preferida quando a correção local falha.
possui requisitos de tempo e espaço elevados, portanto, não é implementado praticamente.
necessidade de analisadores lexicais
- eficiência aprimorada do compilador – técnicas de buffer especializadas para ler caracteres aceleram o processo do compilador.Simplicidade do design do compilador-a remoção de espaços em branco e comentários permitirá construções sintáticas eficientes para o analisador de sintaxe.
- portabilidade do compilador-apenas o scanner se comunica com o mundo externo.
- Especialização – técnicas especializadas podem ser utilizadas para melhorar o processo de análise léxica
Problemas com análise léxica
- Lookahead
Dada uma seqüência de caracteres de entrada, os caracteres são lidos da esquerda para a direita, um por um.
para determinar se um token está concluído ou não, temos que olhar para o próximo caractere.
exemplo: é ‘ = ‘ um operador de atribuição ou o primeiro caractere em ‘==’ operador.
Lookahead Pula caracteres na entrada até que um token bem formado seja encontrado, isso mostra que look ahead não pode detectar erros significativos, exceto por erros simples, como símbolos ilegais. - ambiguidades
os programas escritos com lex aceitarão ESPECIFICAÇÕES ambíguas e, portanto, escolherão a correspondência mais longa e, quando várias expressões corresponderem à entrada, a correspondência mais longa é preferida ou a primeira regra entre as regras de correspondência é priorizada. - Palavras-chave Reservadas
Certas línguas têm palavras reservadas que não forem reservadas em outras linguagens de programação, por exemplo, elif é uma palavra reservada em python, mas não em C. - Contexto de Dependência
Exemplo:
Dada a instrução de FAZER 10 l = 10.86, DO10l é um identificador e não é uma palavra-chave.
e dada a declaração DO 10 l = 10, 86, do é uma palavra-chave
tais declarações exigiriam um olhar substancial à frente para resolução.
aplicativos
- usados por compiladores criam executáveis binários cumpridos a partir de código analisado.
- usado por navegadores da web para formatar e exibir uma página da web que é analisada HTML, CSS e Java script.
com este artigo no OpenGenus, você deve ter uma forte ideia da análise Lexical no design do compilador.