com redes complexas que consistem em nuvem, TI híbrida, virtualização, redes de área de armazenamento e assim por diante, problemas de TI multifacetados podem ser difíceis de identificar e diagnosticar. Quando um problema surge, por exemplo, um aplicativo ou servidor com desempenho ruim, a investigação pode levar um tempo significativo para localizar o problema principal. O problema pode estar no armazenamento, conectividade de rede, acesso do usuário ou uma combinação de recursos e configurações.
para investigar o problema, crie projetos de solução de problemas com o painel de Análise de desempenho (PerfStack™) que correlacionam visualmente dados históricos de vários produtos SolarWinds e tipos de entidade em uma única visualização.
com dashboards de Análise de desempenho, você pode fazer o seguinte:
- Compare e analise vários tipos de métricas em uma única visualização, incluindo status, eventos e estatísticas.
- Compare e analise métricas para várias entidades em uma única visualização, incluindo nós, interfaces, volumes, aplicativos e muito mais.
- correlacione dados de toda a Plataforma Orion em uma única linha de tempo compartilhada.
- Visualize dados híbridos para locais, nuvem e tudo mais.
- compartilhe um projeto de solução de problemas com suas equipes e especialistas para revisar os dados históricos de um problema.
para VMAN, as possibilidades são infinitas para análise de aplicativos e ambientes híbridos:
- Visualmente a pé, através de dados históricos para VMs em seu ambiente
- Verificar problemas de alocação de recursos em ambientes híbridos
- Correlacionar dados para resolver problemas de tráfego de rede enviados e recebidos por servidores virtuais (hosts, clusters, armazenamento de dados, e VMs), servidores locais e na nuvem instâncias
O exemplo a seguir mostra como identificar uma causa para uma VM com problemas de desempenho. Nesse cenário, um host virtual encontrou um problema de recursos e desempenho a ponto de os usuários encontrarem respostas e acesso mais lentos. O problema desencadeou um alerta, que notificou o proprietário do aplicativo, que escalou o problema para administradores de sistema e rede.
crie um novo projeto de solução de problemas para investigar o problema para comparar métricas para o host e todos os sistemas de ambiente virtual relacionados para rastrear tendências e picos de uso.
-
no console da Web Orion, selecione Meus painéis > Home > Análise de desempenho.
isso abre o painel de Análise de desempenho, ou PerfStack, para criar gráficos e gráficos usando métricas retiradas de aplicativos e servidores monitorados na paleta de métricas. Cada gráfico pode conter várias métricas para correlacionar diretamente os dados.
-
no novo projeto de Análise, clique em Adicionar entidades.
para começar, você precisa localizar e adicionar a VM em perigo. No campo de pesquisa, digite syd para exibir uma lista de servidores virtuais que compartilham esse nome. Expanda e selecione Tipos ou Status para filtrar a lista, se necessário.
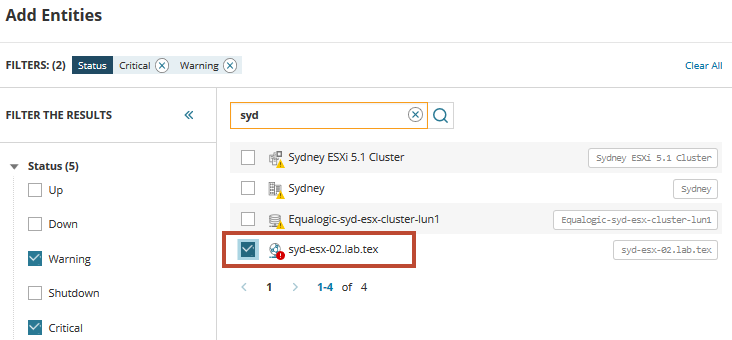
na lista, encontramos o host virtual encontrando os problemas e acionando alertas. Selecione o host e adicione-o à paleta métrica do painel. Clique no ícone entidades relacionadas para exibir todos os servidores e serviços relacionados ao host.
interessado em todos os nós, aplicativos, servidores e muito mais associados a este nó selecionado? Clique no ícone entidades relacionadas.
 todas as entidades relacionadas são exibidas na paleta de métricas, fornecendo mais opções para métricas possivelmente causando problemas.
todas as entidades relacionadas são exibidas na paleta de métricas, fornecendo mais opções para métricas possivelmente causando problemas.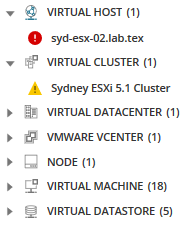
-
selecione o nó host syd para visualizar e selecione métricas para arrastar e soltar no painel. Você pode arrastá-los para o mesmo gráfico para comparar valores entre métricas.
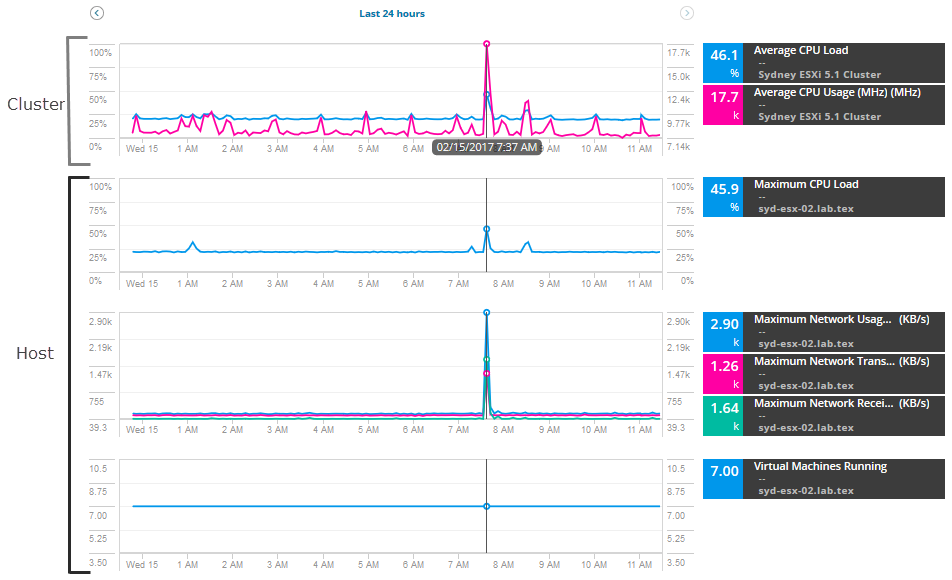
para começar a investigar, puxe uma série de métricas para o host e cluster, comparando métricas para encontrar Picos ou alto uso. Para esse cenário, adicione essas métricas de host:
- Máximo de Uso de Rede
- Rede Máxima Taxa de Transmissão
- Rede Máxima Taxa de Recebimento
- Máquinas Virtuais Executando
Para o cluster, adicionar essas métricas:
- A Carga média de CPU
- > Média de Utilização de CPU
diagramas e gráficos de visualização de dados e alertas para as Últimas 12 horas de métricas. Você pode expandir a data e a hora para ver métricas históricas adicionais ao longo do alerta.
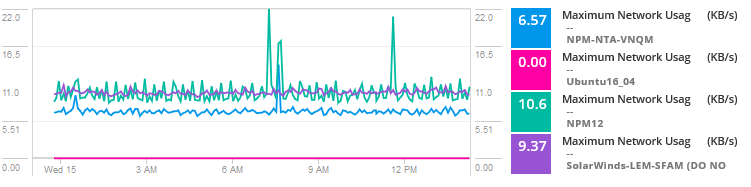
adicione métricas de uso para VMs no host para comparar o uso e a atividade da rede.
-
Analisando os dados, o problema parece ser um vizinho barulhento para uma das máquinas virtuais que consomem recursos e enfrentando de alto tráfego, causando gargalos e problemas para VMs compartilhar o host. Basicamente, outro servidor, serviço ou aplicativo está consumindo maior largura de banda, E/S de disco, CPU e outros recursos que causam problemas para esse aplicativo específico.
esta informação dá a seus administradores de rede e de sistema uma direção para uma investigação mais aprofundada e resolver problemas de latência. Para resolver, eles podem realocar recursos ou mover o aplicativo de alto consumo para outro local.
-
clique em Salvar e dê um nome ao projeto.
o projeto salva como um painel com as métricas selecionadas no intervalo de data e hora definido.
quando salvo, o URL se torna um link compartilhável. Copie e compartilhe o link para o painel salvo em tickets ou e-mails enviados pelos administradores do sistema e da rede e pelo proprietário do produto. Eles podem acessar o link para revisar os dados coletados e solucionar problemas.
depois de realocar recursos e fazer alterações na rede, reabra o painel para verificar alterações e novas tendências de uso para métricas pesquisadas.