în acest articol, discutăm prima fază în proiectarea compilatorului în care programul de intrare la nivel înalt este transformat într-o secvență de Jetoane. Această fază este cunoscută sub numele de analiză lexicală în proiectarea compilatorului.
cuprins:
- definiții pentru analiza lexicală
- un exemplu de analiză lexicală
- arhitectura analizorului lexical
- expresii regulate
- automate Finite
- relația dintre expresiile regulate și automatele finite
- cea mai lungă regulă de potrivire
- erori lexicale
- scheme de recuperare a erorilor
- nevoia de analizoare lexicale
- nevoia de analizoare lexicale
analiza lexicală este procesul de conversie a unei secvențe de caractere dintr-un program sursă care este luat ca intrare într-o secvență de Jetoane.
un lex este un program care generează analizoare lexicale.
un analizor lexical/lexer/scanner este un program care efectuează analize lexicale.
rolurile analizorului lexical implică;
- citirea caracterelor de intrare din programul sursă.
- corelarea mesajelor de eroare cu programul sursă.
- Striping spații albe și comentarii din programul sursă.
- macrocomenzi de expansiune dacă se găsesc în programul sursă.
- introducerea jetoanelor identificate în tabelul simbolurilor.
Lexeme este o instanță a unui jeton, adică o secvență de caractere incluse în programul sursă conform modelului de potrivire a unui jeton.
un exemplu, având în vedere expresia;
c = A + b * 5
lexemele și jetoanele sunt;
| lexeme | Jetoane |
|---|---|
| c | identificator |
| = | simbolul atribuirii |
| un identificator | |
| + | +(simbolul adăugării) |
| B | identificator |
| * | *(simbol de multiplicare) |
| 5 | 5(număr) |
secvența de Jetoane produse de analizorul lexical permite analizorului să analizeze sintaxa unui limbaj de programare.
un simbol este o secvență validă de caractere dată de o lexemă, este tratată ca o unitate în gramatica limbajului de programare.
într-un limbaj de programare aceasta poate include;
- cuvinte cheie
- operatori
- simboluri de punctuație
- constante
- identificatori
- numere
un model este o regulă care corespunde unei secvențe de caractere(lexeme) utilizate de jeton. Poate fi definit prin expresii regulate sau reguli gramaticale.
un exemplu de analiză lexicală
Cod
#include<iostream>// exampleint main(){ int a, b; a = 7; return 0;}Jetoane
| lexeme | Jetoane |
|---|---|
| int | cuvânt cheie |
| principal | cuvânt cheie |
| ( | operator |
| ) | operator |
| { | operator |
| int | cuvânt cheie |
| un identificator | |
| , | operator |
| b | identificator |
| ; | operator |
| un identificator | |
| = | simbolul atribuirii |
| 10 | 10(număr) |
| ; | operator |
| întoarcere | cuvânt cheie |
| 0 | 0(număr) |
| ; | operator |
| } | operator |
non Tokens
| Tip | Jetoane |
|---|---|
| Directiva preprocesorului | #include<iostream> |
| comentariu | / / exemplu |
procesul de analiză lexicală constituie două etape.
- Scanare – Aceasta implică citirea caracterelor de intrareși eliminarea spațiilor albe și a comentariilor.
- tokenizare – aceasta este producția de jetoane ca ieșire.
arhitectura analizorului lexical
sarcina principală a analizorului lexical este de a scana întregul program sursă și de a identifica jetoanele unul câte unul.
scanerele sunt implementate pentru a produce jetoane atunci când sunt solicitate de parser.

pași:
- „obțineți următorul jeton” este trimis de la analizor la analizorul lexical.
- analizorul lexical scanează intrarea până când se află „următorul jeton”.
- jetonul este returnat parserului.
expresii regulate
folosim expresii regulate pentru a exprima limbaje finite prin definirea modelelor pentru un set finit de simboluri.
gramatica definită de expresii regulate este cunoscută sub numele de gramatică regulată, iar limba definită de gramatica regulată este cunoscută sub numele de limbaj regulat.
există reguli algebrice respectate de expresiile regulate folosite pentru a manipula expresiile regulate în forme echivalente.
operațiuni.
Unirea a două limbi A și B este scrisă ca
A U B = {S | S este în a sau s este în B}
concatenarea a două limbi a și B este scrisă ca
AB = {ss | S este în a și s este în B}
închiderea kleen a unei limbi A este scrisă ca
a* = care este zero sau mai multe apariții ale limbii A.
notații.
dacă X și y sunt expresii regulate care denotă limbile a(x) și B(y) atunci;
(x) este o expresie regulată care denotă a(x).
Uniunea (x) / (y) este o expresie regulată care denotă A(x) B (y).
concatenare (x)(y) este o expresie regulată denting A(x)B(y).
închiderea Kleen (x)* este o expresie regulată care denotă (a(x))*
prioritate și asociativitate.
*’ concatenare .’și | (pipe) sunt lăsate asociative.
închiderea Kleen * are cea mai mare prioritate.
concatenare (.) urmează în prioritate.
(țeavă) / are cea mai mică prioritate.
reprezentând jetoane valide ale unei limbi în expresii regulate.
X este o expresie regulată, prin urmare;
- x * reprezintă zero sau mai multe apariții de x.
- x+ reprezintă una sau mai multe apariții de x, adică{X, xx, xxx}
- x? reprezintă cel mult o apariție a X adică {x}
- reprezintă toate alfabetele cu litere mici în limba engleză.
- reprezintă toate alfabetele majuscule în limba engleză.
- reprezintă toate numerele naturale.
reprezentarea apariției simbolurilor folosind expresii regulate
Letter = or
Digit = or|0|1|2|3|4|5|6|7|8|9
semn =
reprezentând token-uri de limbă folosind expresii regulate.
zecimal = (semn)?(digit)+
Identifier = (letter) (letter | digit)*
automatele Finite
aceasta este combinația a cinci tupluri (Q, INQ, Q0, qf, INQ) care se concentrează pe stări și tranziții prin simboluri de intrare.
recunoaște tiparele luând șirul simbolului ca intrare și își schimbă starea în consecință.
modelul matematic pentru automatele finite constă din;
- set finit de stări (Q)
- set finit de simboluri de intrare (Irak)
- o stare de pornire (q0)
- Set de stări finale (qf)
- funcție de tranziție (Irak)
automatele Finite sunt utilizate în analiza lexicală pentru a produce jetoane sub formă de identificatori, cuvinte cheie și constante din programul de intrare.
automate Finite alimentează șirul de expresie regulată și starea este modificată pentru fiecare literal.
dacă intrarea este procesată cu succes, automatele ajung la starea finală și sunt acceptate altfel sunt respinse.
construcția automatelor Finite
fie L(r) un limbaj regulat de către unele automate finite F(a).
prin urmare;
- State: cercurile vor reprezenta stările FA și numele lor sunt scrise în interiorul cercurilor.
- stare de pornire: Aceasta este starea la care pornește automatele. Va avea o săgeată îndreptată spre ea.
- stări intermediare: acestea au două săgeți, una arătând spre ea și alta arătând din stările intermediare.
- Starea Finală: Automatele sunt de așteptat să fie în starea finală atunci când șirul de intrare a fost analizat cu succes și reprezentat de cercuri duble, altfel intrarea este respinsă. Poate conține un număr impar de săgeți îndreptate spre el și un număr par care indică din el, adică
săgeți impare = săgeți PARE + 1. - tranziție: când se găsește un simbol dorit în intrare, se va întâmpla trecerea de la o stare la alta. Automatele fie se mută la starea următoare, fie persistă.
o săgeată direcționată va afișa mișcarea de la o stare la alta în timp ce o săgeată indică spre starea de destinație.
dacă automatele rămân în aceeași stare, este desenată o săgeată care indică de la o stare la ea însăși.
un exemplu; Să presupunem că o valoare binară de 3 cifre care se termină în 1 este acceptată de FA.
atunci FA = {Q(q0, qf), 0,1), Q0, QF, Irak}
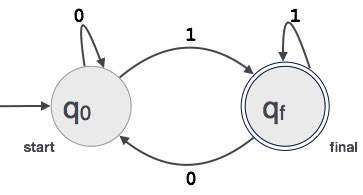
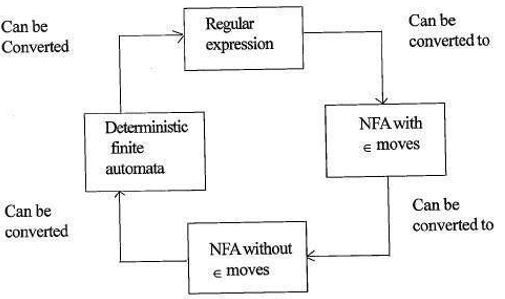
relația dintre expresiile regulate și automatele finite
relația dintre expresia regulată și automatele finite este după cum urmează;
figura de mai jos arată că este ușor de convertit;
- expresii regulate la automatele finite nedeterministe (NFA)cu mișcări de la un nivel la altul.
- automate finite nedeterministe cu deplasări la fără deplasări la 0xtx
- automate finite nedeterministe fără deplasări la 0xtx la automate Finite deterministe(DFA).
- automate Finite deterministe la expresia regulată.
un Lex va accepta expresii regulate ca intrare și va returna un program care simulează un Automat finit pentru a recunoaște expresiile regulate.
prin urmare, lex va combina generarea modelului de șir (expresii regulate care definesc șirurile de interes pentru lex) și recunoașterea modelului de șir (un Automat finit care recunoaște șirurile de interes).
regula celui mai lung meci
se afirmă că lexema scanată trebuie determinată pe baza celui mai lung meci dintre toate jetoanele disponibile.
aceasta este utilizată pentru a rezolva ambiguitățile atunci când se decide următorul jeton în fluxul de intrare.
în timpul analizei codului sursă, analizorul lexical va scana codul literă cu literă și atunci când este detectat un operator, un simbol special sau un spațiu alb, acesta decide dacă un cuvânt este complet.
exemplu:
int intvalue;în timpul scanării celor de mai sus, analizorul nu poate determina dacă ‘int’ este un cuvânt cheie INT sau prefixul identificatorului intvalue.
se aplică prioritatea regulii prin care unui cuvânt cheie i se va acorda prioritate față de intrarea utilizatorului, ceea ce înseamnă că în exemplul de mai sus analizorul va genera o eroare.
erori lexicale
o eroare lexicală apare atunci când o secvență de caractere nu poate fi scanată într-un simbol valid.
aceste erori pot fi cauzate de o scriere greșită a identificatorilor, a cuvintelor cheie sau a operatorilor.
în general, deși Erorile lexicale foarte neobișnuite sunt cauzate de caractere ilegale într-un simbol.
erorile pot fi;
- eroare de ortografie.
- transpunerea a două caractere.
- caractere ilegale.
- depășirea lungimii constantelor de identificare sau numerice.
- înlocuirea unui caracter cu un caracter incorect
- eliminarea unui caracter care ar trebui să fie prezent.
recuperarea erorilor implică;
- eliminarea unui caracter din Intrarea rămasă
- transpunerea a două caractere adiacente
- ștergerea unui caracter din Intrarea rămasă
- inserarea caracterului lipsă în intrarea rămasă
- înlocuirea unui caracter cu un alt caracter.
- ignorarea caracterelor succesive până când se formează un simbol legal(recuperare în modul panică).
scheme de recuperare a erorilor
recuperare în modul panică.
în această schemă de recuperare a erorilor, modelele de neegalat sunt șterse din Intrarea rămasă până când analizorul lexical poate găsi un jeton bine format la începutul intrării rămase.
implementarea mai ușoară este un avantaj pentru această abordare.
are limitarea că o cantitate mare de intrare este omisă fără a verifica eventualele erori suplimentare.
Corecție Locală.
când este detectată o eroare la un punct de inserare/ștergere și/sau operațiuni de înlocuire sunt executate până când se obține un text bine format.
analizorul este repornit cu textul nou rezultat ca intrare.
corecție globală.
este o recuperare îmbunătățită a modului de panică preferată atunci când corecția locală eșuează.
are cerințe ridicate de timp și spațiu, prin urmare nu este implementat practic.
nevoie de analizoare lexicale
- eficiență îmbunătățită a compilatorului – tehnicile specializate de tamponare pentru citirea caracterelor accelerează procesul compilatorului.
- simplitatea designului compilatorului – eliminarea spațiilor albe și a comentariilor va permite construcții sintactice eficiente pentru analizorul de sintaxă.
- portabilitatea compilatorului – numai scanerul comunică cu lumea exterioară.
- specializare – tehnici specializate pot fi folosite pentru a îmbunătăți procesul de analiză lexicală
probleme cu analiza lexicală
- Lookahead
având în vedere un șir de intrare, caracterele sunt citite de la stânga la dreapta unul câte unul.
pentru a determina dacă un simbol este terminat sau nu, trebuie să ne uităm la următorul caracter.
exemplu: este ‘=’ un operator de atribuire sau primul caracter din ‘==’ operator.
Lookahead omite caracterele din intrare până când se găsește un jeton bine format, acest lucru arată că look ahead nu poate prinde erori semnificative, cu excepția erorilor simple, cum ar fi simbolurile ilegale. - ambiguități
programele scrise cu lex vor accepta specificații ambigue și, prin urmare, alegeți cea mai lungă potrivire și atunci când mai multe expresii se potrivesc cu intrarea, fie se preferă cea mai lungă potrivire, fie se acordă prioritate primei reguli dintre regulile de potrivire. - cuvinte cheie rezervate
anumite limbi au cuvinte rezervate care nu sunt rezervate în alte limbaje de programare, de exemplu, elif este un cuvânt rezervat în python, dar nu în C. - dependență de Context
exemplu:
având în vedere declarația DO 10 l = 10.86, DO10l este un identificator și DO nu este un cuvânt cheie.
și având în vedere declarația DO 10 L = 10, 86, DO este un cuvânt cheie
astfel de declarații ar necesita o privire substanțială înainte pentru rezoluție.
aplicațiile
- utilizate de compilatoare creează executabile binare respectate din Codul analizat.
- folosit de browsere web pentru a formata și afișa o pagină web care este analizat HTML, CSS și java script.
cu acest articol de la OpenGenus, trebuie să aveți o idee puternică de analiză lexicală în proiectarea compilatorului.