să fim dureros de sinceri, atunci când afacerea dvs. nu este reprezentată pe Internet, este inexistentă pentru lume. Mai mult, dacă nu aveți un site web, pierdeți o oportunitate amplă de a atrage mai mulți clienți potențiali de calitate. Orice afacere de la un gigant corporativ precum Amazon la o companie de o singură persoană se străduiește să aibă un site web și un conținut care să atragă publicul lor. Descoperirea dvs. și a companiei dvs. online nu se oprește aici. În spatele site-urilor web, există o întreagă lume „invizibilă pentru ochiul uman” în care crawlerele web joacă un rol important.
cuprins
- ce este un Crawler Web și indexare?
- cum funcționează o căutare pe Web?
- cum funcționează un Crawler Web?
- care sunt principalele tipuri de Crawler Web?
- care sunt exemplele de crawlere Web?
- ce este un Googlebot?
- Web Crawler vs web Scraper — care este diferența?
- Crawler Web Personalizat-Ce Este?
- Wrapping Up
ce este un Crawler Web și indexare?
să începem cu o definiție a crawlerului web:
un crawler web (cunoscut și sub numele de păianjen web, robot păianjen, bot web sau pur și simplu crawler) este un program software de calculator care este utilizat de un motor de căutare pentru a indexa paginile web și conținutul din întreaga lume Web.
indexarea este un proces esențial, deoarece ajută utilizatorii să găsească interogări relevante în câteva secunde. Indexarea căutării poate fi comparată cu indexarea cărților. De exemplu, dacă deschideți ultimele pagini ale unui manual, veți găsi un index cu o listă de interogări în ordine alfabetică și pagini în care acestea sunt menționate în manual. Același principiu subliniază indexul de căutare, dar în loc de numerotarea paginilor, un motor de căutare vă arată câteva linkuri unde puteți căuta răspunsuri la întrebarea dvs.
diferența semnificativă dintre indicii de căutare și carte este că primul este dinamic, prin urmare, poate fi schimbat, iar cel de-al doilea este întotdeauna static.
cum funcționează o căutare pe Web?
înainte de a intra în detaliile despre modul în care funcționează un robot pe șenile, să vedem cum este executat întregul proces de căutare înainte de a primi un răspuns la interogarea dvs. de căutare.
de exemplu, dacă tastați” care este distanța dintre Pământ și Lună ” și apăsați enter, un motor de căutare vă va afișa o listă de pagini relevante. De obicei, este nevoie de trei pași majori pentru a oferi utilizatorilor informațiile necesare căutărilor lor:
- un păianjen web accesează cu crawlere conținutul de pe site-uri
- se construiește un index pentru un motor de căutare
- algoritmi de căutare rang paginile cele mai relevante
de asemenea, trebuie să aibă în vedere două puncte esențiale:
- nu faceți căutările în timp real, deoarece este imposibil
există o mulțime de site-uri web pe World Wide Web și multe altele sunt create chiar și acum când citiți acest articol. De aceea, ar putea dura eoni pentru ca un motor de căutare să vină cu o listă de pagini care ar fi relevante pentru interogarea dvs. Pentru a accelera procesul de căutare, un motor de căutare accesează cu crawlere paginile înainte de a le arăta lumii.
- nu efectuați căutările în World Wide Web
într-adevăr, nu efectuați căutări în World Wide Web, ci într-un index de căutare și acesta este momentul în care un crawler web intră pe câmpul de luptă.
Contactați-Ne Acum!
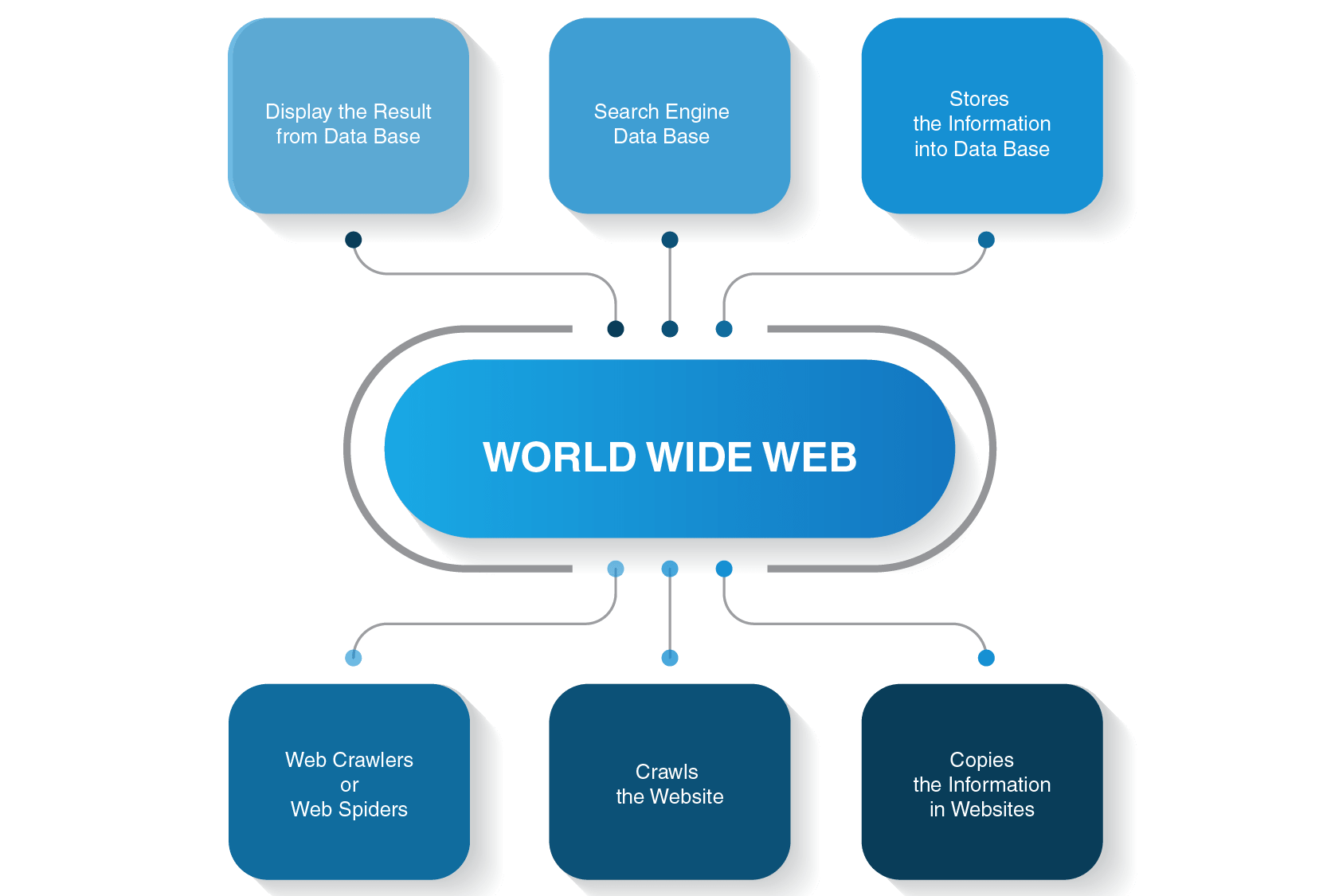
cum funcționează un Crawler Web?
există multe motoare de căutare acolo-Google, Bing, Yahoo!, DuckDuckGo, Baidu, Yandex și multe altele. Fiecare dintre ele își folosește robotul păianjen pentru a indexa paginile.
își încep procesul de accesare cu crawlere de pe cele mai populare site-uri web. Scopul lor principal al roboților web este de a transmite esența a ceea ce este vorba despre fiecare conținut al paginii. Astfel, păianjenii web caută cuvinte pe aceste pagini și apoi construiesc o listă practică a acestor cuvinte care vor fi folosite de un motor de căutare data viitoare când doriți să găsiți informații despre interogarea dvs.
toate paginile de pe Internet sunt conectate prin hyperlink-uri, astfel încât site-ul păianjeni pot descoperi aceste link-uri și urmați-le la paginile următoare. Roboții Web se opresc numai atunci când localizează tot conținutul și site-urile conectate. Apoi trimit informațiile înregistrate un index de căutare, care este stocat pe servere din întreaga lume. Întregul proces seamănă cu o pânză de păianjen din viața reală, unde totul este împletit.
accesarea cu crawlere nu se oprește imediat după ce paginile au fost indexate. Motoarele de căutare folosesc periodic păianjeni web pentru a vedea dacă s-au făcut modificări la pagini. Dacă există o modificare, indexul unui motor de căutare va fi actualizat în consecință.
care sunt principalele tipuri de Crawler Web?
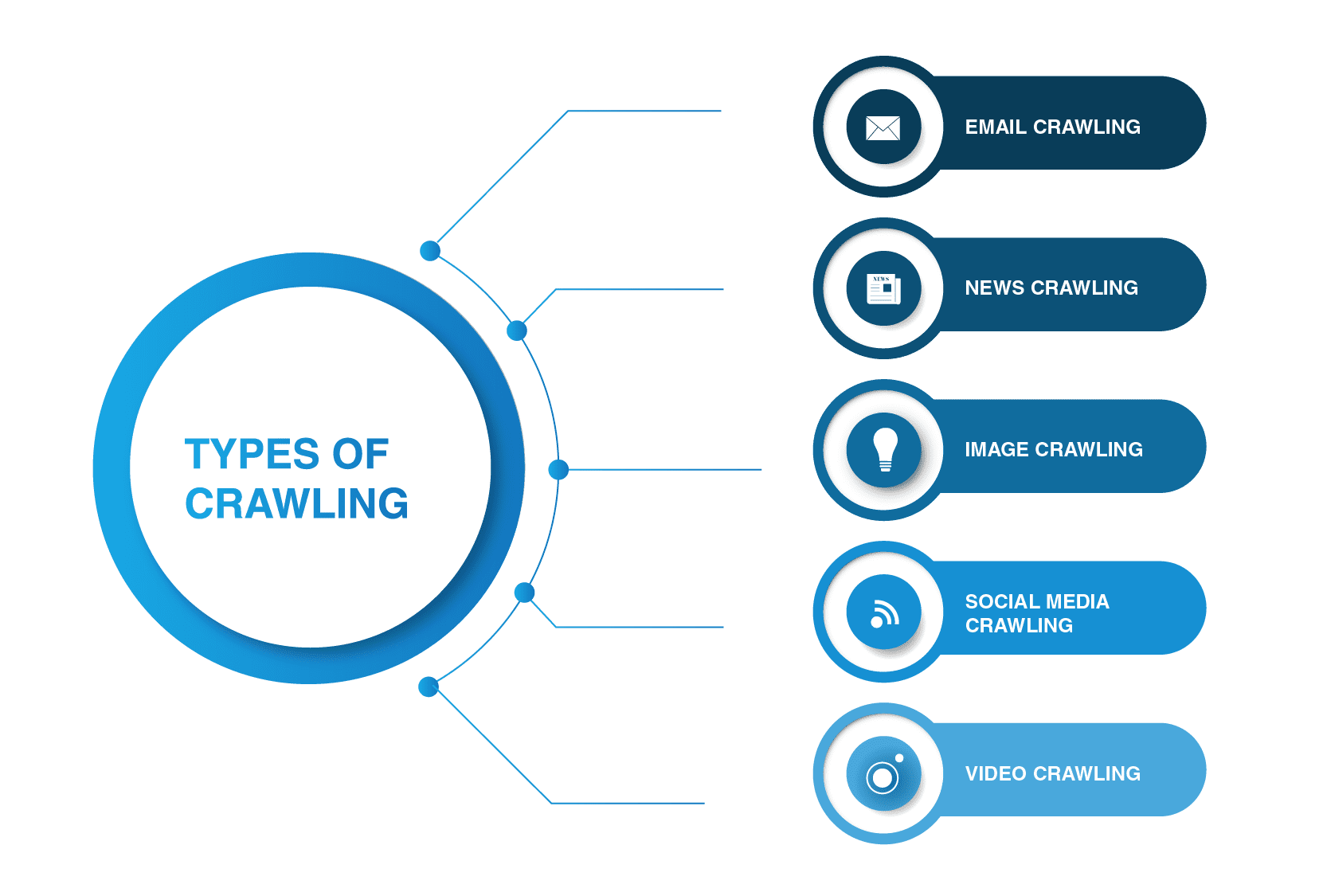
crawlerele Web nu se limitează la păianjenii motoarelor de căutare. Există și alte tipuri de web crawling acolo.
- accesarea cu crawlere a e-mailurilor
accesarea cu crawlere a e-mailurilor este utilă în special în generarea de clienți potențiali de ieșire, deoarece acest tip de accesare cu crawlere ajută la extragerea adreselor de e-mail. Merită menționat faptul că acest tip de accesare cu crawlere este ilegal, deoarece încalcă confidențialitatea personală și nu poate fi utilizat fără permisiunea utilizatorului.
- știri crawling
odată cu apariția Internetului, știri din întreaga lume pot fi răspândite rapid în jurul Web, și pentru a extrage date de la diverse site-uri pot fi destul de greu de gestionat.
există multe crawlere web care pot face față acestei sarcini. Astfel de crawlere sunt capabile să recupereze date din conținut de știri Nou, vechi și arhivat și să citească fluxuri RSS. Acestea extrag următoarele informații: data publicării, numele autorului, titlurile, paragrafele principale, textul principal și limba de publicare.
- accesarea cu crawlere a imaginilor
după cum sugerează și numele, acest tip de accesare cu crawlere se aplică imaginilor. Internetul este plin de reprezentări vizuale. Astfel, astfel de roboți ajută oamenii să găsească imagini relevante într-o multitudine de imagini de pe Web.
- social media crawling
social media crawling este o chestiune destul de interesantă, deoarece nu toate platformele de social media permit accesarea cu crawlere. De asemenea, trebuie să țineți cont de faptul că un astfel de tip de crawling poate fi ilegal dacă încalcă respectarea confidențialității datelor. Cu toate acestea, există mulți furnizori de platforme de socializare care sunt în regulă cu accesarea cu crawlere. De exemplu, Pinterest și Twitter permit roboților spider să-și scaneze paginile dacă nu sunt sensibili la utilizatori și nu dezvăluie informații personale. Facebook, LinkedIn sunt stricte în ceea ce privește această chestiune.
- video crawling
uneori este mult mai ușor să vizionați un videoclip decât să citiți mult conținut. Dacă decideți să încorporați Youtube, Soundcloud, Vimeo sau orice alt conținut video în site-ul dvs. web, acesta poate fi indexat de unele crawlere web.
care sunt exemple de crawlere Web?
o mulțime de motoare de căutare folosesc propriile boturi de căutare. De exemplu, cele mai frecvente exemple de crawlere web sunt:
- Alexabot
Amazon Web crawler Alexabot este utilizat pentru identificarea conținutului web și descoperirea backlink-ului. Dacă doriți să păstrați unele dintre informațiile dvs. private, puteți exclude Alexabot de la accesarea cu crawlere a site-ului dvs. web.
- Yahoo! Slurp Bot
Yahoo crawler Yahoo! Slurp Bot este utilizat pentru indexarea și razuirea paginilor web pentru a îmbunătăți conținutul personalizat pentru utilizatori.
- Bingbot
Bingbot este unul dintre cei mai populari păianjeni web alimentați de Microsoft. Ajută un motor de căutare, Bing, să creeze cel mai relevant index pentru utilizatorii săi.
- DuckDuck Bot
DuckDuckGo este probabil unul dintre cele mai populare motoare de căutare care nu vă urmărește istoricul și vă urmărește pe orice site pe care îl vizitați. Crawlerul său web DuckDuck Bot ajută la găsirea celor mai relevante și mai bune rezultate care vor satisface nevoile unui utilizator.
- Facebook extern lovit
Facebook are, de asemenea, pe șenile sale. De exemplu, atunci când un utilizator Facebook dorește să partajeze un link către o pagină de conținut externă cu o altă persoană, crawlerul zgârie codul HTML al paginii și le oferă amândurora titlul, o etichetă a videoclipului sau imagini ale conținutului.
- Baiduspider
acest crawler este operat de motorul de căutare chinez dominant − Baidu. Ca orice alt bot, călătorește printr-o varietate de pagini web și caută hyperlink-uri pentru a indexa conținutul pentru motor.
- Exabot
motorul de căutare francez Exalead folosește Exabot pentru indexarea conținutului, astfel încât acesta să poată fi inclus în indexul motorului.
- Yandex Bot
acest bot aparține celui mai mare motor de căutare rus Yandex. Puteți bloca indexarea conținutului dvs. dacă nu intenționați să desfășurați afaceri acolo.
ce este un Googlebot?
după cum sa menționat mai sus, aproape toate motoarele de căutare au roboții lor de păianjen, iar Google nu face excepție. Googlebot este un crawler google alimentat de cel mai popular motor de căutare din lume, care este utilizat pentru indexarea conținutului pentru acest motor.
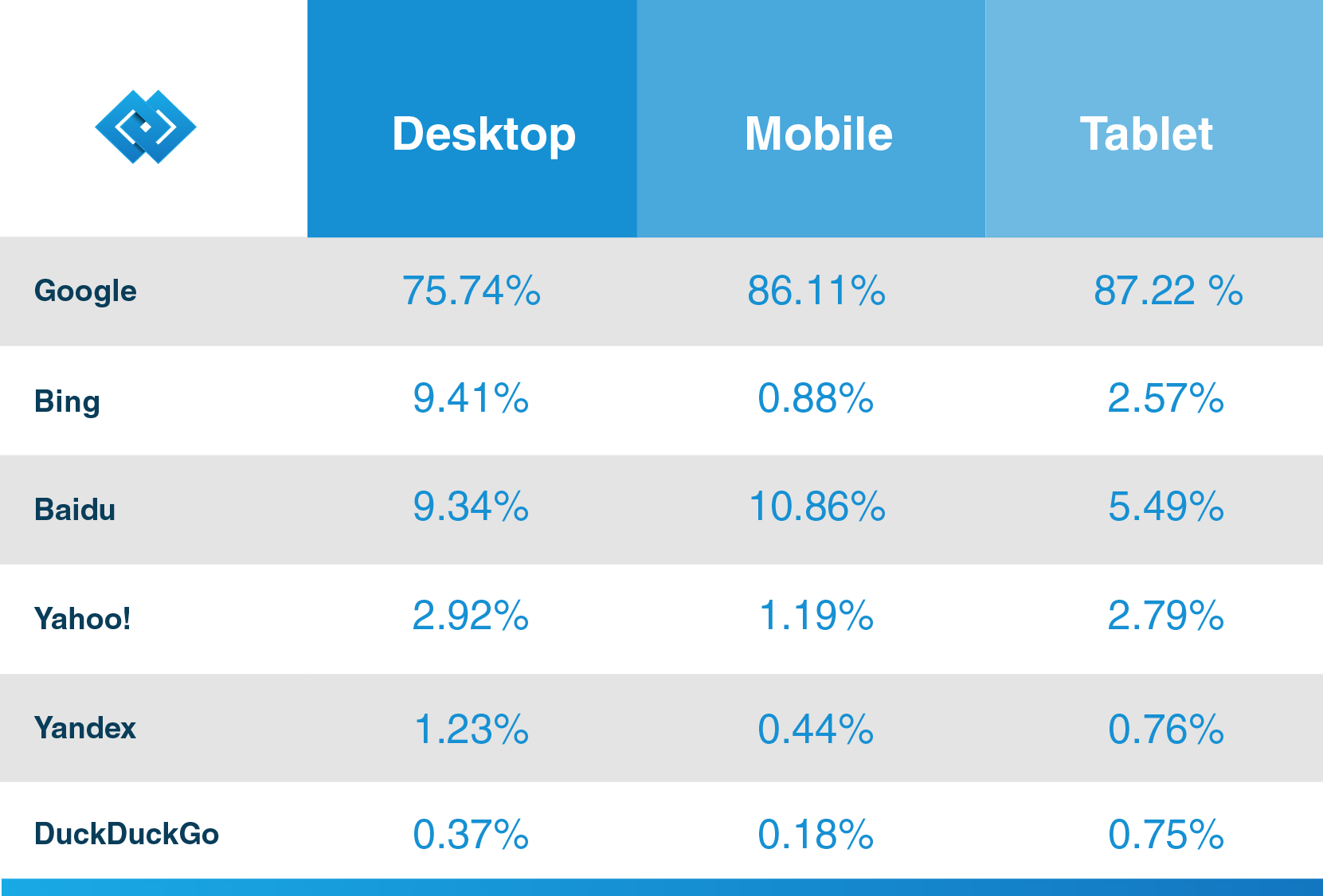
după cum afirmă Hubspot, un renumit furnizor de CRM, în blogul său, Google are mai mult de 92,42% din cota de piață a căutării, iar traficul său mobil este de peste 86%. Deci, dacă doriți să profitați la maximum de motorul de căutare pentru afacerea dvs., aflați mai multe informații despre păianjenul său web, astfel încât viitorii dvs. clienți să vă poată descoperi conținutul datorită Google.
Googlebot poate fi de două tipuri — un bot desktop și un crawler de aplicații mobile, care simulează utilizatorul pe aceste dispozitive. Folosește același principiu de accesare cu crawlere ca orice alt păianjen web, cum ar fi urmărirea linkurilor și scanarea conținutului disponibil pe site-urile web. Procesul este, de asemenea, complet automatizat și poate fi recurent, ceea ce înseamnă că poate vizita aceeași pagină de mai multe ori la intervale neregulate.
dacă sunteți gata să publicați conținut, va dura zile până când crawlerul Google îl va indexa. Dacă sunteți proprietarul site-ului web, puteți accelera manual procesul prin trimiterea unei cereri de indexare prin Fetch as Google sau actualizarea sitemap-ului site-ului dvs. web.
puteți utiliza, de asemenea, roboți.txt (sau Protocolul de Excludere a roboților) pentru „a da instrucțiuni” unui robot păianjen, inclusiv Googlebot. Acolo puteți permite sau interzice crawlerelor să viziteze anumite pagini ale site-ului dvs. web. Cu toate acestea, rețineți că acest fișier poate fi accesat cu ușurință de terți. Ei vor vedea ce părți ale site-ului ați restricționat de la indexare.
Web Crawler vs web Scraper — care este diferența?
o mulțime de oameni folosesc crawlerele web și răzuitoarele web în mod interschimbabil. Cu toate acestea, există o diferență esențială între aceste două. Dacă primul se ocupă mai ales de metadate de conținut, cum ar fi etichete, titluri, cuvinte cheie și alte lucruri, acesta din urmă „fură” conținut de pe un site web pentru a fi postat pe resursa online a altcuiva.
un răzuitor web „vânează” și date specifice. De exemplu, dacă trebuie să extrageți informații de pe un site web unde există informații precum tendințele pieței bursiere, prețurile Bitcoin sau orice altceva, puteți prelua date de pe aceste site-uri web utilizând un bot de razuire web.
dacă accesați cu crawlere site — ul dvs. web și doriți să trimiteți conținutul dvs. pentru indexare sau aveți intenția ca alte persoane să îl găsească-este perfect legal, altfel răzuirea site-urilor altor persoane și companii este împotriva legii.
Crawler Web Personalizat-Ce Este?
un crawler web personalizat este un bot care este folosit pentru a acoperi o nevoie specifică. Vă puteți construi robotul păianjen pentru a acoperi orice sarcină care trebuie rezolvată. De exemplu, dacă sunteți antreprenor sau marketer sau orice alt profesionist care se ocupă de conținut, puteți facilita clienților și utilizatorilor dvs. să găsească informațiile pe care le doresc pe site-ul dvs. web. Puteți crea o varietate de roboți web în diverse scopuri.
dacă nu aveți experiență practică în construirea crawlerului web personalizat, puteți contacta întotdeauna un furnizor de servicii de dezvoltare software care vă poate ajuta cu acesta.
înfășurarea
crawlerele site-urilor web sunt o parte integrantă a oricărui motor de căutare major care este utilizat pentru indexarea și descoperirea conținutului. Multe companii de motoare de căutare au roboții lor, de exemplu, Googlebot este alimentat de gigantul corporativ Google. În afară de aceasta, există mai multe tipuri de crawling care sunt utilizate pentru a acoperi nevoile specifice, cum ar fi accesarea cu crawlere a videoclipurilor, imaginilor sau rețelelor sociale.
luând în considerare ceea ce pot face roboții spider, aceștia sunt extrem de esențiali și benefici pentru afacerea dvs., deoarece crawlerele web vă dezvăluie pe dvs. și compania dvs. în lume și pot aduce noi Utilizatori și clienți.
dacă doriți să creați un crawler web personalizat, contactați LITSLINK, un furnizor de servicii de dezvoltare web cu experiență, pentru mai multe informații.