cu rețele complexe constând din cloud, IT hibrid, virtualizare, rețele de zone de stocare și așa mai departe, problemele IT cu mai multe fațete pot fi dificil de identificat și diagnosticat. Când apare o problemă, de exemplu o aplicație sau un server cu performanțe slabe, investigația poate dura mult timp pentru a localiza problema de bază. Problema ar putea fi stocarea, conectivitatea la rețea, accesul utilizatorilor sau un amestec de resurse și configurații.
pentru a investiga problema, creați proiecte de depanare cu tabloul de bord Performance Analysis (PerfStack) care corelează vizual datele istorice din mai multe produse SolarWinds și tipuri de entități într-o singură vizualizare.
cu tablouri de bord pentru analiza performanței, puteți face următoarele:
- comparați și analizați mai multe tipuri de valori într-o singură vizualizare, inclusiv starea, evenimentele și statisticile.
- comparați și analizați valorile pentru mai multe entități într-o singură vizualizare, inclusiv noduri, interfețe, volume, aplicații și multe altele.
- corelați datele de pe platforma Orion pe o singură linie de timp partajată.
- Vizualizați datele hibride pentru Local, cloud și totul între ele.
- partajați un proiect de depanare cu echipele și experții dvs. pentru a examina datele istorice pentru o problemă.
pentru VMAN, posibilitățile sunt nelimitate pentru analiza aplicațiilor și medii hibride:
- parcurgeți vizual datele istorice pentru VM-urile din mediul dvs.
- verificați problemele de alocare a resurselor în medii hibride
- corelați datele pentru a depana traficul de rețea trimis și primit de Serverele Virtuale (gazde, clustere, magazine de date și VM-uri), serverele locale și instanțele cloud
următorul exemplu vă arată cum să identificați o vm se confruntă cu probleme de performanță. În acest scenariu, o gazdă virtuală a întâmpinat o problemă de resurse și performanță până la punctul în care utilizatorii întâmpină răspunsuri și acces mai lent. Problema a declanșat o alertă, care a notificat proprietarul aplicației dvs., care a escaladat problema administratorilor de sistem și de rețea.
creați un nou proiect de depanare pentru a investiga problema pentru a compara valorile pentru gazdă și toate sistemele de mediu virtual conexe pentru a urmări tendințele și vârfurile de utilizare.
-
în consola Web Orion, selectați tablourile mele de bord > acasă > Analiza performanței.
aceasta deschide tabloul de bord Performance Analysis sau PerfStack pentru a construi diagrame și grafice folosind valori extrase din aplicațiile și serverele monitorizate din paleta metrică. Fiecare diagramă poate conține mai multe valori pentru a corela direct datele.
-
în noul proiect de analiză, faceți clic pe Adăugare entități.
pentru a începe, trebuie să localizați și să adăugați VM în primejdie. În câmpul de căutare, introduceți syd pentru a afișa o listă de servere virtuale care partajează acel nume. Extindeți și selectați tipuri sau stare pentru a filtra lista, dacă este necesar.
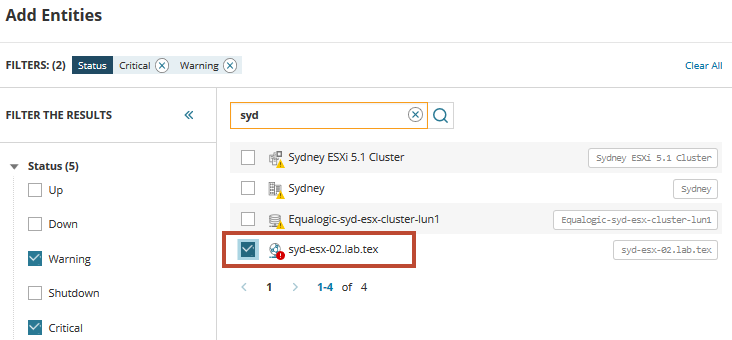
din listă, găsim gazda virtuală care întâmpină problemele și declanșează alerte. Selectați gazda și adăugați-o la paleta metrică a tabloului de bord. Faceți clic pe pictograma entități asociate pentru a afișa toate serverele și serviciile asociate către gazdă.
interesat de toate nodurile asociate, aplicații, servere, și mai mult la acest nod selectat? Faceți clic pe pictograma entități asociate.
 toate entitățile asociate se afișează în paleta metrică oferind mai multe opțiuni pentru valori care pot cauza probleme.
toate entitățile asociate se afișează în paleta metrică oferind mai multe opțiuni pentru valori care pot cauza probleme.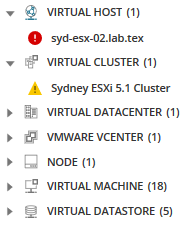
-
selectați nodul gazdă syd pentru a vizualiza și selectați valori de drag and drop pe tabloul de bord. Le puteți trage în aceeași diagramă pentru a compara valorile între valori.
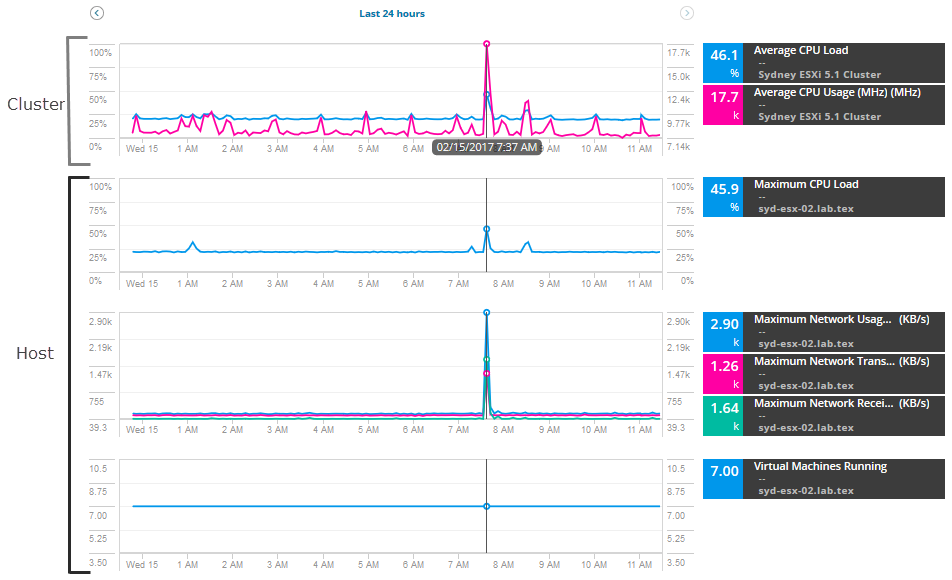
pentru a începe investigarea, trageți o serie de valori pentru gazdă și cluster, comparând valorile pentru a găsi vârfuri sau utilizare ridicată. Pentru acest scenariu, adăugați aceste valori gazdă:
- utilizarea maximă a rețelei
- rata maximă de transmisie a rețelei
- rata maximă de primire a rețelei
- mașini virtuale care rulează
pentru cluster, Adăugați aceste valori:
- încărcarea medie a procesorului
- utilizarea medie a procesorului
graficele și graficele sunt afișate cu date și alerte pentru ultimele 12 ore de valori. Puteți extinde data și ora pentru a vedea valori istorice suplimentare pe parcursul alertei.
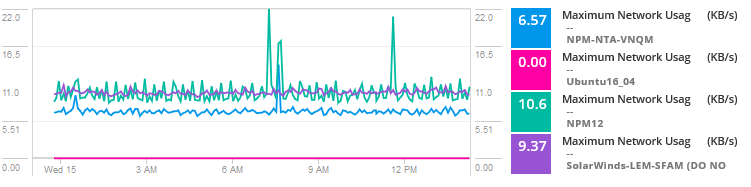
adăugați valori de utilizare pentru VMs pe gazdă pentru a compara utilizarea și activitatea rețelei.
-
analizând datele, problema pare a fi un vecin zgomotos pentru una dintre mașinile virtuale care consumă resurse și se confruntă cu trafic ridicat, provocând blocaje și probleme pentru VM-urile care partajează gazda. Practic, un alt server, serviciu sau aplicație consumă lățime de bandă mai mare, I/o pe disc, CPU și alte resurse care cauzează probleme pentru această aplicație specifică.
aceste informații oferă administratorilor de rețea și de sistem o direcție pentru investigații suplimentare și rezolvarea problemelor de latență. Pentru a rezolva, pot realoca resurse sau muta aplicația cu consum ridicat într-o altă locație.
-
Faceți clic pe Salvare și dați proiectului un nume.
proiectul Salvează ca tablou de bord cu valorile selectate în intervalul de dată și oră setat.
când este salvat, URL-ul devine un link Partajabil. Copiați și partajați linkul către tabloul de bord salvat în bilete sau e-mailuri trimise de administratorii de sistem și de rețea și de proprietarul produsului. Aceștia pot accesa linkul pentru a examina datele colectate și a depana.
după realocarea resurselor și efectuarea modificărilor de rețea, redeschideți tabloul de bord pentru a verifica modificările și noile tendințe de utilizare pentru valorile chestionate.