buďme bolestně upřímní, když vaše firma není zastoupena na internetu, ve světě neexistuje. Navíc, pokud nemáte webové stránky, ztrácíte dostatek příležitostí k přilákání více kvalitních potenciálních zákazníků. Jakékoli podnikání od korporátního gigantu, jako je Amazon, po Společnost s jednou osobou se snaží mít web a obsah, který osloví jejich publikum. Objevování vás a vaší společnosti online nekončí. Za webovými stránkami je celý svět „neviditelný pro lidské oko“, kde hrají důležitou roli webové prohledávače.
obsah
- co je webový prohledávač a indexování?
- jak funguje vyhledávání na webu?
- jak funguje webový prohledávač?
- jaké jsou hlavní typy webového prohledávače?
- jaké jsou příklady webových prohledávačů?
- co je Googlebot?
- Web Crawler vs Web Scraper-jaký je rozdíl?
- Vlastní Webový Prohledávač-Co To Je?
- balení
co je webový prohledávač a indexování?
začněme s definicí webového prohledávače:
webový prohledávač (také známý jako web spider, spider bot, web bot nebo jednoduše crawler)je počítačový softwarový program, který používá vyhledávač k indexování webových stránek a obsahu na celém webu.
indexování je zcela zásadní proces, protože pomáhá uživatelům najít relevantní dotazy během několika sekund. Indexování vyhledávání lze porovnat s indexováním knih. Pokud například otevřete poslední stránky učebnice, najdete index se seznamem dotazů v abecedním pořadí a stránkami, kde jsou uvedeny v učebnici. Stejný princip podtrhuje index vyhledávání, ale místo číslování stránek vám vyhledávač zobrazí některé odkazy, kde můžete hledat odpovědi na svůj dotaz.
významný rozdíl mezi vyhledávacími a knižními indexy spočívá v tom, že první je dynamický, proto jej lze změnit a druhý je vždy statický.
jak funguje vyhledávání na webu?
než se ponoříme do podrobností o tom, jak robot prohledávače funguje, podívejme se, jak je celý proces vyhledávání proveden, než dostanete odpověď na vyhledávací dotaz.
pokud například zadáte „jaká je vzdálenost mezi Zemí a Měsícem“ a stisknete klávesu enter, vyhledávač vám zobrazí seznam relevantních stránek. Obvykle, to trvá tři hlavní kroky poskytnout uživatelům požadované informace k jejich vyhledávání:
- webový pavouk prochází obsah na webových stránkách
- vytváří index pro vyhledávač
- vyhledávací algoritmy řadí nejdůležitější stránky
také je třeba mít na paměti dva základní body:
- neděláte vyhledávání v reálném čase, protože je nemožné
existuje spousta webových stránek na World Wide Web a mnoho dalších se vytváří i nyní, když čtete tento článek. Proto může trvat věky, než vyhledávač přijde se seznamem stránek, které by byly relevantní pro váš dotaz. Chcete-li urychlit proces vyhledávání, vyhledávač prochází stránky před jejich zobrazením světu.
- neprovádíte vyhledávání na World Wide Web
ve skutečnosti neprovádíte vyhledávání na World Wide Web, ale ve vyhledávacím indexu a to je, když webový prohledávač vstoupí na bojiště.
Kontaktujte Nás Nyní!
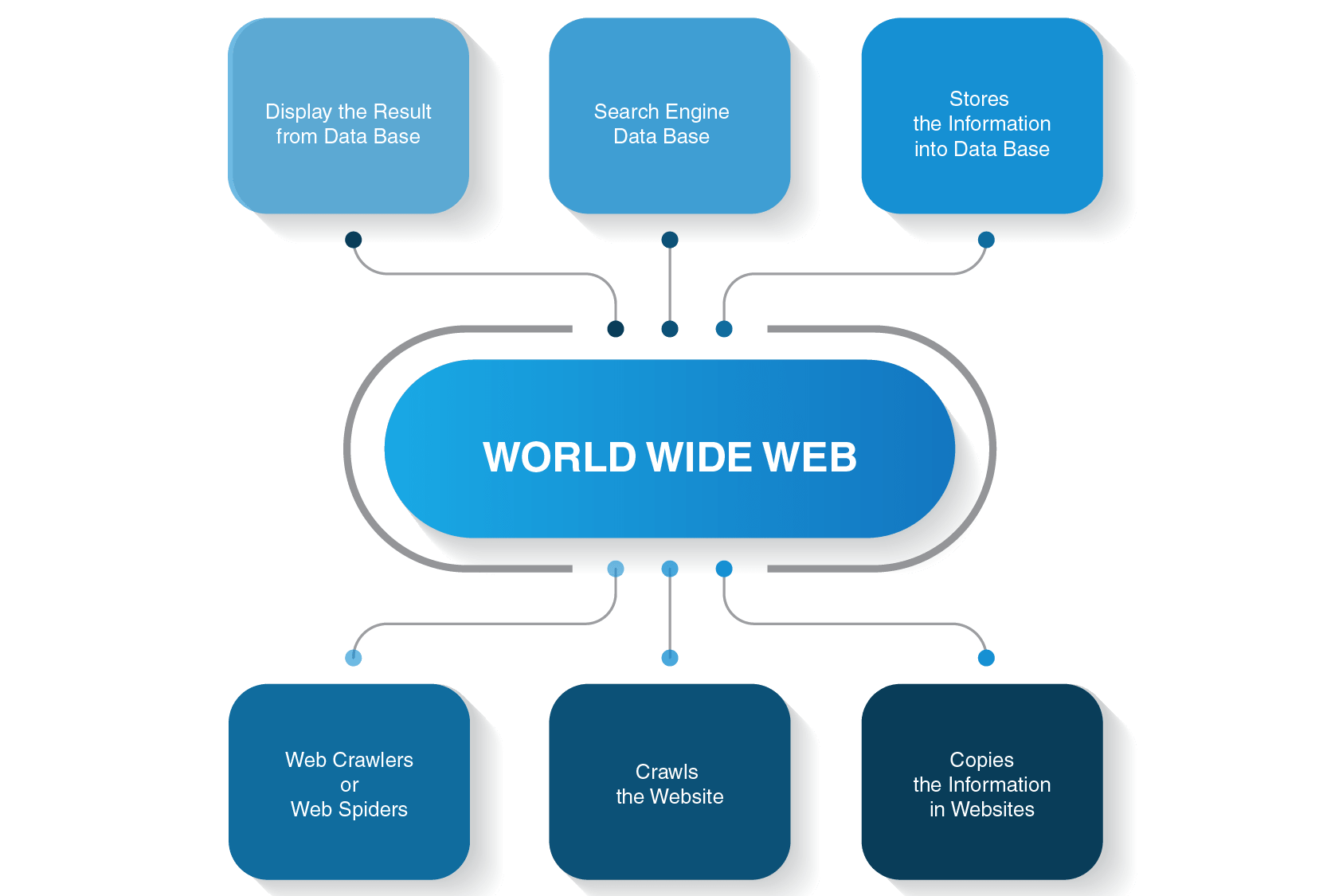
jak funguje webový prohledávač?
existuje mnoho vyhledávačů-Google, Bing, Yahoo!, DuckDuckGo, Baidu, Yandex a mnoho dalších. Každý z nich používá svého pavoučího robota k indexování stránek.
začínají proces procházení z nejpopulárnějších webových stránek. Jejich primárním účelem webových robotů je sdělit podstatu toho, o čem je každý obsah stránky. Weboví pavouci tedy hledají slova na těchto stránkách a poté vytvoří praktický seznam těchto slov, která budou příště použita vyhledávačem, když chcete najít informace o vašem dotazu.
všechny stránky na internetu jsou propojeny hypertextovými odkazy, takže pavouci stránek mohou tyto odkazy objevit a sledovat je na další stránky. Weboví roboti se zastaví pouze tehdy, když vyhledají veškerý obsah a připojené webové stránky. Poté pošlou zaznamenané informace vyhledávací index, který je uložen na serverech po celém světě. Celý proces připomíná reálnou pavučinu, kde se vše prolíná.
procházení se nezastaví okamžitě, jakmile jsou stránky indexovány. Vyhledávače pravidelně používají webové pavouky, aby zjistily, zda byly na stránkách provedeny nějaké změny. Pokud dojde ke změně, index vyhledávače bude odpovídajícím způsobem aktualizován.
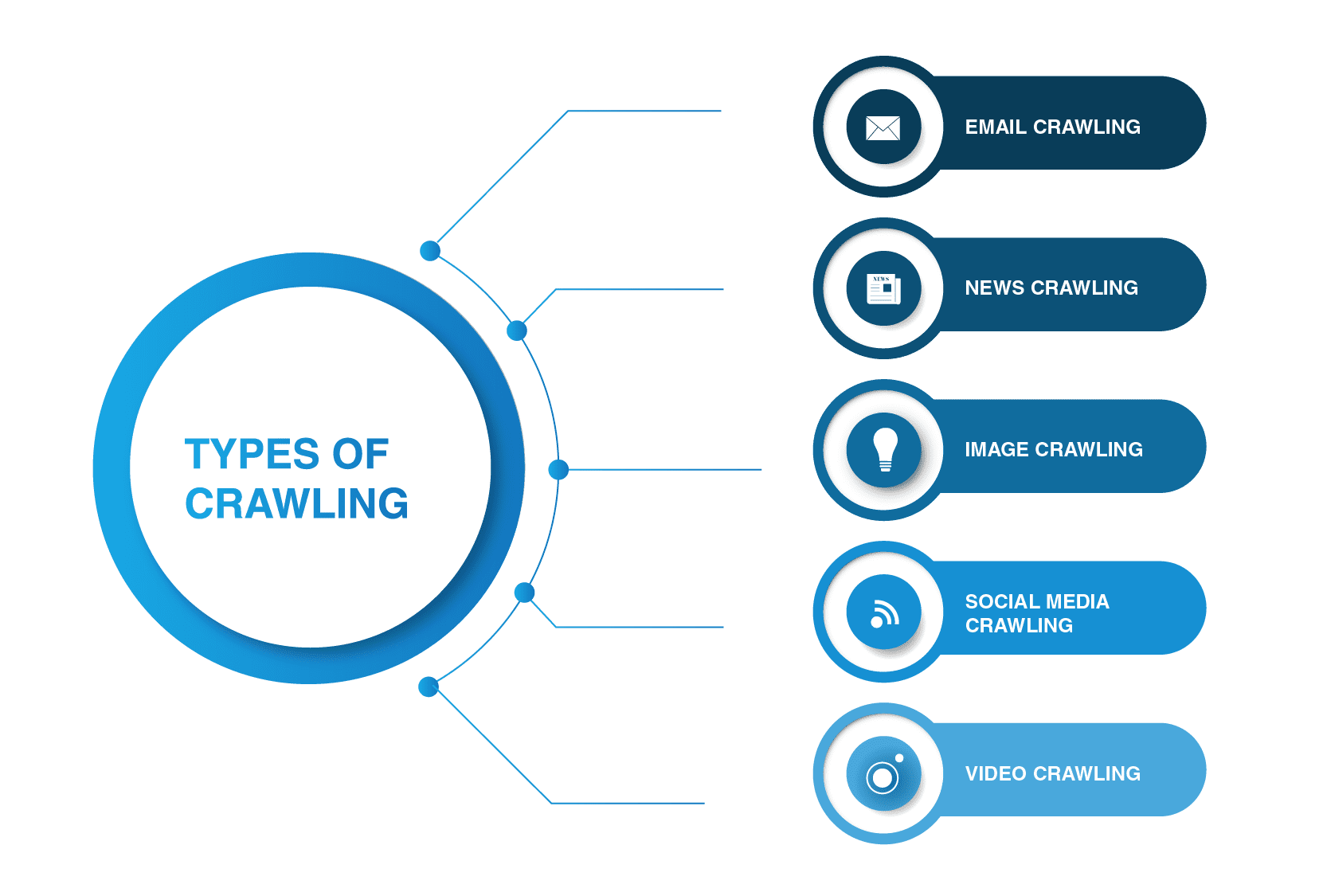
jaké jsou hlavní typy webového prohledávače?
webové prohledávače nejsou omezeny na pavouky vyhledávačů. Existují i jiné typy procházení webu.
- procházení e-mailů
procházení e-mailů je zvláště užitečné při odchozím generování olova, protože tento typ procházení pomáhá extrahovat e-mailové adresy. Stojí za zmínku, že tento druh procházení je nezákonný, protože porušuje osobní soukromí a nemůže být použit bez souhlasu uživatele.
- procházení zpráv
s příchodem Internetu se zprávy z celého světa mohou rychle šířit po webu a extrahovat data z různých webových stránek může být docela nezvládnutelné.
existuje mnoho webových prohledávačů, které se s tímto úkolem vyrovnají. Tyto prohledávače jsou schopny načíst data z nového, starého a archivovaného obsahu zpráv a číst RSS kanály. Extrahují následující informace: datum vydání, jméno autora, titulky, hlavní odstavce, hlavní text, a jazyk publikování.
- procházení obrázků
jak název napovídá, tento typ procházení se aplikuje na obrázky. Internet je plný vizuálních reprezentací. Takoví roboti pomáhají lidem najít relevantní obrázky v množství obrázků na webu.
- procházení sociálních médií
procházení sociálních médií je docela zajímavá záležitost, protože ne všechny platformy sociálních médií umožňují procházení. Měli byste také mít na paměti, že takový typ procházení může být nezákonný, pokud porušuje dodržování ochrany osobních údajů. Přesto existuje mnoho poskytovatelů platforem sociálních médií, kteří jsou v pořádku s plazením. Například Pinterest a Twitter umožňují robotům spider skenovat jejich stránky, pokud nejsou citlivé na uživatele a nezveřejňují žádné osobní údaje. Facebook, LinkedIn jsou v této věci přísné.
- procházení videa
někdy je mnohem snazší sledovat video než číst hodně obsahu. Pokud se rozhodnete vložit Youtube, Soundcloud, Vimeo nebo jakýkoli jiný videoobsah na svůj web, může být indexován některými webovými prohledávači.
jaké jsou příklady webových prohledávačů?
mnoho vyhledávačů používá své vlastní vyhledávací roboty. Například nejběžnější příklady webových prohledávačů jsou:
- Alexabot
Amazon web crawler Alexabot se používá pro identifikaci webového obsahu a zpětné vyhledávání. Pokud chcete zachovat některé své informace v soukromí, můžete Alexabot vyloučit z procházení vašeho webu.
- Yahoo! Slurp Bot
Yahoo crawler Yahoo! Slurp Bot se používá pro indexování a škrábání webových stránek pro zlepšení personalizovaného obsahu pro uživatele.
- Bingbot
Bingbot je jedním z nejpopulárnějších webových pavouků poháněných společností Microsoft. Pomáhá vyhledávači Bing vytvořit pro své uživatele nejrelevantnější index.
- Duckduck Bot
DuckDuckGo je pravděpodobně jedním z nejpopulárnějších vyhledávačů, které nesledují vaši historii a sledují vás na stránkách, které navštěvujete. Jeho webový prohledávač DuckDuck Bot pomáhá najít nejrelevantnější a nejlepší výsledky, které uspokojí potřeby uživatele.
- Facebook externí Hit
Facebook má také svůj prohledávač. Například, když uživatel Facebook chce sdílet odkaz na externí stránku obsahu s jinou osobou, prohledávač škrábe HTML kód stránky a oběma poskytne název, značku videa nebo obrázky obsahu.
- Baiduspider
tento prohledávač je provozován dominantním čínským vyhledávačem-Baidu. Jako každý jiný robot, prochází různými webovými stránkami a hledá hypertextové odkazy na indexovaný obsah motoru.
- Exabot
francouzský vyhledávač Exalead používá Exabot pro indexaci obsahu, aby mohl být zahrnut do indexu motoru.
- Yandex Bot
tento bot patří k největšímu ruskému vyhledávači Yandex. Pokud tam neplánujete podnikat, můžete jej zablokovat v indexování obsahu.
co je Googlebot?
jak bylo uvedeno výše, téměř všechny vyhledávače mají své pavoučí roboty a Google není výjimkou. Googlebot je prohledávač google poháněný nejoblíbenějším vyhledávačem na světě, který se používá pro indexování obsahu pro tento motor.
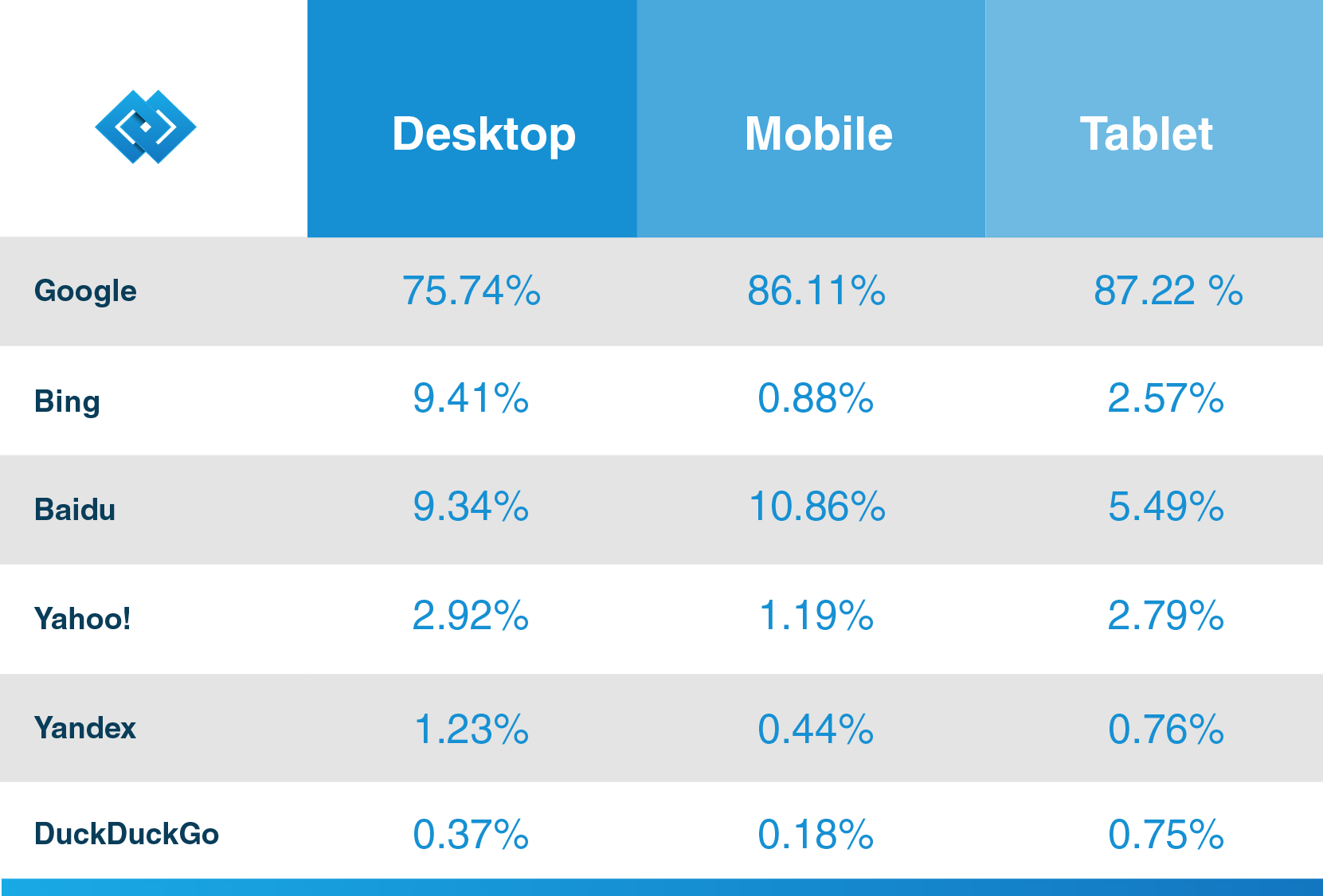
jak uvádí Hubspot, renomovaný prodejce CRM, ve svém blogu, Google má více než 92.42% podílu na trhu vyhledávání a jeho mobilní provoz je přes 86%. Pokud tedy chcete z vyhledávače pro svou firmu vytěžit maximum, Zjistěte více informací o jeho webovém pavouku, aby vaši budoucí zákazníci mohli díky Googlu objevit váš obsah.
Googlebot může být dvou typů-desktop bot a mobilní prohledávače aplikací, které simulují uživatele na těchto zařízeních. Používá stejný princip procházení jako jakýkoli jiný webový pavouk, například následující odkazy a skenování obsahu dostupného na webových stránkách. Tento proces je také plně automatizovaný a může se opakovat, což znamená, že může navštívit stejnou stránku několikrát v nepravidelných intervalech.
pokud jste připraveni publikovat obsah, bude trvat několik dní, než jej prohledávač Google indexuje. Pokud jste vlastníkem webu, můžete proces ručně urychlit odesláním žádosti o indexování prostřednictvím aplikace Fetch as Google nebo aktualizací souboru sitemap vašeho webu.
můžete také použít roboty.txt (nebo Robots Exclusion Protocol) pro „dávat pokyny“ spider bot, včetně Googlebot. Zde můžete povolit nebo zakázat prohledávačům navštívit určité stránky vašeho webu. Mějte však na paměti, že k tomuto souboru mohou snadno přistupovat třetí strany. Uvidí, jaké části webu jste omezili v indexování.
web Crawler vs Web Scraper-jaký je rozdíl?
mnoho lidí používá webové prohledávače a webové škrabky zaměnitelně. Mezi těmito dvěma je však zásadní rozdíl. Pokud se první zabývá převážně metadaty obsahu, jako jsou značky, nadpisy, klíčová slova a další věci, druhý „ukradne“ obsah z webu, který má být zveřejněn na online zdroji někoho jiného.
webová škrabka také „loví“ konkrétní data. Například, pokud potřebujete získat informace z webových stránek, kde jsou informace, jako jsou trendy akciového trhu, ceny bitcoinů nebo jiné, můžete načíst data z těchto webových stránek pomocí webového škrabacího robota.
pokud procházíte své webové stránky a chcete odeslat svůj obsah k indexování nebo máte v úmyslu, aby ho našli ostatní lidé — je to naprosto legální, jinak je škrábání webových stránek jiných lidí a společností v rozporu se zákonem.
Vlastní Webový Prohledávač-Co To Je?
vlastní webový prohledávač je robot, který se používá k pokrytí konkrétní potřeby. Můžete si vytvořit svůj spider bot tak, aby pokryl jakýkoli úkol, který je třeba vyřešit. Například, pokud jste podnikatel nebo obchodník nebo jakýkoli jiný profesionál, který se zabývá obsahem, můžete svým zákazníkům a uživatelům usnadnit nalezení požadovaných informací na vašem webu. Můžete vytvořit různé webové roboty pro různé účely.
pokud nemáte žádné praktické zkušenosti s vytvářením vlastního webového prohledávače, můžete se vždy obrátit na poskytovatele služeb pro vývoj softwaru, který vám s ním může pomoci.
zabalení
webové prohledávače jsou nedílnou součástí každého významného vyhledávače, který se používá pro indexování a objevování obsahu. Mnoho společností vyhledávačů má své roboty, například Googlebot je poháněn firemním gigantem Google. Kromě toho existuje několik typů procházení, které se používají k pokrytí konkrétních potřeb, jako je procházení videa, obrázků nebo sociálních médií.
vzhledem k tomu, co pavoučí roboti mohou dělat, jsou velmi důležité a prospěšné pro vaše podnikání, protože webové prohledávače odhalují vás a vaši společnost světu a mohou přivést nové uživatele a zákazníky.
pokud chcete vytvořit vlastní webový prohledávač, kontaktujte LITSLINK, zkušeného poskytovatele služeb pro vývoj webových aplikací, pro více informací.