jak zpětně analyzovat Model z databáze nebo skriptu
reverzní inženýrství je proces vytváření datového modelu z databáze nebo skriptu. Modelovací nástroj vytváří grafické znázornění vybraných databázových objektů a vztahů mezi objekty. Toto grafické znázornění může být logickým nebo fyzickým modelem.
Poznámka: můžete zpětně analyzovat pouze prázdný model. Nemůžete zpětně analyzovat model, který má v sobě objekty.
databáze může být zpětně navržena z následujících důvodů:
- Chcete-li pochopit, jak jsou objekty vzájemně propojeny, a poté na nich stavět
- demonstrovat strukturu databáze
po dokončení procesu zpětného inženýrství můžete provést následující úkoly:
- Přidat nové databázové objekty
- Vytvořte systémovou dokumentaci
- přepracujte strukturu databáze tak, aby vyhovovala vašim požadavkům
většina informací, které zpětně analyzujete, je explicitně definována ve fyzickém schématu. Reverzní inženýrství však také odvozuje informace ze schématu a začleňuje je do modelu. Například, pokud cílový DBMS podporuje deklarace cizích klíčů, proces reverzního inženýrství odvozuje identifikaci a neidentifikaci vztahů a výchozích názvů rolí.
můžete odvodit všechny hlavní informace o modelu, kromě vztahů podtypů, protože v současné době jej nepodporuje žádný systém správy databází SQL. Cílové databáze se však liší v množství informací o logickém datovém modelu, které jsou obsaženy ve fyzickém schématu. Z tohoto důvodu se výsledné modely mohou lišit v závislosti na vybrané cílové databázi. Můžete také odvodit některé logické informace, včetně primárních klíčů, cizích klíčů a vztahů tabulky. K odvození těchto klíčů a vztahů můžete použít definice indexu tabulky nebo názvy sloupců.
spouštěče RI můžete zahrnout nebo vyloučit v procesu zpětného inženýrství. Můžete si vybrat, zda chcete spouštěče RI považovat za objekty modelu, nebo použít volbu forward engineering pro zahrnutí spouštěčů RI do schématu. Můžete se také rozhodnout zahrnout nebo vyloučit tyto možnosti během zpětného inženýrství.
při zpětném inženýrství databáze můžete nastavit soubor trasování pro záznam dotazů, které jsou prováděny za účelem načtení objektů. Dotazy můžete zkontrolovat po dokončení procesu zpětného inženýrství.
následující diagram znázorňuje kroky k zpětnému inženýrství modelu z databáze nebo skriptu:
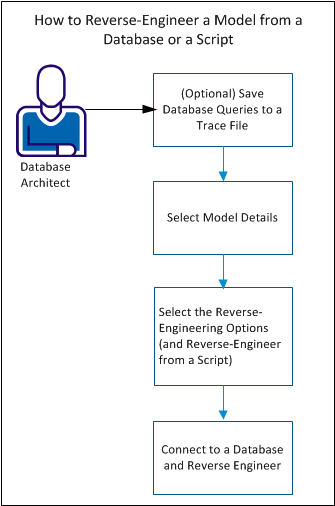
proveďte následující kroky k reverznímu inženýrství modelu:
- (Volitelné) Uložit databázové dotazy do souboru trasování.
- vyberte detaily modelu.
- vyberte možnosti zpětného inženýrství.
- Připojte se k databázi a zpětnému inženýrovi.
specifické objekty reverzního inženýrství
tato část obsahuje podrobnosti o tom, jak proces reverzního inženýrství funguje pro různé databázové objekty.
Index
při zpětném inženýrství databáze se importuje název, definice a parametry každého indexu, který je definován na serveru. Při importu informací o indexu ze serveru se zachovávají informace o umístění úložiště pro každý index. Proto můžete databázi znovu vytvořit pomocí stejných přiřazení úložiště. Není nutné znovu přiřadit umístění úložiště pro každý index ručně.
po importu indexů můžete zobrazit nebo upravit vlastnosti indexu, definice a přidružení tabulek v dialogovém okně indexy. Index můžete přiřadit objektu fyzického úložiště v dialogovém okně indexy pro databáze DB2 z / OS, Informix, Oracle, SQL Server a SAP ASE. Pokud je vaše cílová databáze DB2 z / OS, Informix a Oracle, můžete také upravit parametry úložiště v dialogovém okně indexy.
pokud je pro databázi DB2 z/OS, Informix, Oracle nebo SAP ASE vybrána možnost fyzického úložiště, pak schéma obsahuje parametry fyzického úložiště indexu.
objekt fyzického úložiště
při zpětném inženýrství databáze můžete importovat názvy a definice objektů fyzického úložiště, které jste definovali na cílovém serveru. Import probíhá stejným způsobem jako import fyzických tabulek, indexů a dalších informací o fyzickém schématu. Po importu objektů fyzického úložiště můžete pomocí standardních editorů zobrazit nebo upravit definice objektů a přidružení tabulek.
Validační pravidlo
při reverzním inženýrství ze souboru schématu, skriptu nebo systémového katalogu jsou validační pravidla importována a připojena k příslušné tabulce nebo sloupci ve výsledném modelu. Konvence, která se používá k pojmenování importovaných validačních pravidel, je následující:
VALID_RULEn
zde n je pořadové číslo začínající na nule. První Validační pravidlo, se kterým se setkáme, se jmenuje VALID_RULE0, další pravidlo VALID_RULE1 atd., dokud nebude zpracováno celé schéma.