v tomto článku diskutujeme první fázi návrhu kompilátoru, kde je vstupní program vysoké úrovně převeden na sekvenci tokenů. Tato fáze je známá jako lexikální analýza v návrhu kompilátoru.
obsah:
- Definice Pro lexikální analýzu
- příklad lexikální analýzy
- Architektura lexikálního analyzátoru
- regulární výrazy
- konečné automaty
- vztah mezi regulárními výrazy a konečnými automaty
- nejdelší pravidlo shody
- lexikální chyby
- schémata obnovy chyb
- potřeba lexikálních analyzátorů
- pro lexikální analyzátory
lexikální analýza je proces převodu sekvence znaků ze zdrojového programu, který je brán jako vstup do sekvence tokenů.
lex je program, který generuje lexikální analyzátory.
lexikální analyzátor / lexer / scanner je program, který provádí lexikální analýzu.
role lexikálního analyzátoru zahrnují;
- čtení vstupních znaků ze zdrojového programu.
- korelace chybových zpráv se zdrojovým programem.
- pruhování bílých mezer a komentářů ze zdrojového programu.
- rozšiřující makra, pokud jsou nalezena ve zdrojovém programu.
- zadání identifikovaných žetonů do tabulky symbolů.
Lexeme je instance tokenu, tedy posloupnost znaků obsažených ve zdrojovém programu podle odpovídajícího vzoru tokenu.
příklad, vzhledem k výrazu;
c = a + b * 5
lexémy a tokeny jsou;
| lexémy | tokeny |
|---|---|
| C | identifikátor |
| = | symbol přiřazení |
| identifikátor | |
| + | +(symbol přidání) |
| B | identifikátor |
| * | *(symbol násobení) |
| 5 | 5(číslo) |
posloupnost tokenů produkovaných lexikálním analyzátorem umožňuje analyzátoru analyzovat syntaxi programovací jazyk.
token je platná posloupnost znaků daná lexémem, je považována za jednotku v gramatice programovacího jazyka.
v programovacím jazyce to může zahrnovat;
- klíčová slova
- operátory
- interpunkční symboly
- konstanty
- identifikátory
- čísla
vzor je pravidlo odpovídající posloupnosti znaků (lexémů) používaných tokenem. Může být definován regulárními výrazy nebo gramatickými pravidly.
příklad lexikální analýzy
kód
#include<iostream>// exampleint main(){ int a, b; a = 7; return 0;}tokeny
| lexémy | tokeny |
|---|---|
| int | Klíčové slovo |
| hlavní | Klíčové slovo |
| ( | provozovatel |
| ) | provozovatel |
| { | provozovatel |
| int | Klíčové slovo |
| identifikátor | |
| , | provozovatel |
| b | identifikátor |
| ; | provozovatel |
| identifikátor | |
| = | symbol přiřazení |
| 10 | 10(číslo) |
| ; | provozovatel |
| return | Klíčové slovo |
| 0 | 0(číslo) |
| ; | operátor |
| } | provozovatel |
Non tokeny
| Typ | tokeny |
|---|---|
| preprocesorová směrnice | #include<iostream> |
| komentář | / / příklad |
proces lexikální analýzy se skládá ze dvou fází.
- skenování-To zahrnuje čtení vstupních znakůa odstranění bílých mezer a komentářů.
- tokenizace-jedná se o výrobu tokenů jako výstupu.
Architektura lexikálního analyzátoru
hlavním úkolem lexikálního analyzátoru je skenovat celý zdrojový program a identifikovat tokeny jeden po druhém.
skenery jsou implementovány tak, aby vytvářely tokeny na žádost analyzátoru.

kroky:
- „získat další token“ je odeslán z analyzátoru do lexikálního analyzátoru.
- lexikální analyzátor skenuje vstup, dokud není umístěn „další token“.
- token se vrátí do analyzátoru.
regulární výrazy
regulární výrazy používáme k vyjádření konečných jazyků definováním vzorů pro konečnou množinu symbolů.
gramatika definovaná regulárními výrazy je známá jako regulární gramatika a jazyk definovaný regulární gramatikou je známý jako regulární jazyk.
existují algebraická pravidla, která se řídí regulárními výrazy používanými k manipulaci s regulárními výrazy do ekvivalentních forem.
operace.
spojení dvou jazyků A A B je zapsáno jako
a U B = {s / S je v a nebo s je v B}
zřetězení dvou jazyků a A B je zapsáno jako
AB = {ss / s je v A A s je v B}
uzavření jazyka a je zapsáno jako
a* = což je nula nebo více výskytů jazyka a.
notace.
pokud x a y jsou regulární výrazy označující jazyky a(x) a B (y) pak;
(x) je regulární výraz označující a(x).
Union (x)|(y) je regulární výraz označující a(x) B (y).
zřetězení (x) (y) je regulární výraz promáčknutí a (x) B (y).
Kleen closure (x) * je regulární výraz označující (a (x))*
prioritu a asociativitu.
* ‚ zřetězení .’a / (trubka) jsou vlevo asociativní.
uzavření Kleenu * má nejvyšší prioritu.
zřetězení (.) následuje v prioritě.
(pipe) / má nejnižší prioritu.
reprezentující platné tokeny jazyka v regulárních výrazech.
X je regulární výraz, proto;
- x * představuje nulový nebo více výskyt x.
- x + představuje jeden nebo více výskyt x, tj.{x, xx, xxx}
- x? představuje nanejvýš jeden výskyt x ie {x}
- představují všechny malé abecedy v anglickém jazyce.
- představují všechny abecedy velkých písmen v anglickém jazyce.
- představují všechna přirozená čísla.
reprezentující výskyt symbolů pomocí regulárních výrazů
Letter = or
Digit = or|0|1|2|3|4|5|6|7|8|9
Sign =
reprezentující jazykové tokeny pomocí regulárních výrazů.
Decimal = (sign)?(číslice)+
identifikátor = (písmeno) (Písmeno | číslice) *
konečné automaty
Jedná se o kombinaci pěti n-tic (Q, Σ, q0, qf, δ) se zaměřením na stavy a přechody prostřednictvím vstupních symbolů.
rozpoznává vzory tím, že vezme řetězec symbolu jako vstup a podle toho změní svůj stav.
matematický model pro konečné automaty se skládá z;
- konečná množina stavů (Q)
- konečná množina vstupních symbolů (Σ)
- jeden počáteční stav (q0)
- Sada konečných stavů (qf)
- přechodová funkce (δ)
konečné automaty se používají v lexikální analýze k výrobě tokenů ve formě identifikátorů, klíčových slov a konstant ze vstupního programu.
konečné automaty napájí řetězec regulárních výrazů a stav se změní pro každý doslov.
pokud je vstup úspěšně zpracován, automaty dosáhnou konečného stavu a jsou přijaty, jinak jsou odmítnuty.
konstrukce konečných automatů
Nechť L (r) je regulárním jazykem některých konečných automatů F(A).
proto;
- státy: kruhy budou reprezentovat státy FA a jejich jména jsou zapsána uvnitř kruhů.
- počáteční stav: Toto je stav, ve kterém se automaty spouštějí. Bude mít šipku směřující k ní.
- mezilehlé stavy: tyto mají dvě šipky, jedna směřující k ní a druhá ukazující z mezilehlých stavů.
- Konečný Stav: Očekává se, že automaty budou v konečném stavu, když byl vstupní řetězec úspěšně analyzován a reprezentován dvojitými kruhy, jinak je vstup odmítnut. Může obsahovat lichý počet šipek směřujících k němu a sudé číslo ukazující z něj, to znamená
liché šipky = sudé šipky + 1. - přechod: když je ve vstupu nalezen požadovaný symbol, dojde k přechodu z jednoho stavu do jiného stavu. Automaty se buď přesunou do dalšího stavu, nebo přetrvávají.
směrovaná šipka zobrazí pohyb z jednoho stavu do druhého, zatímco šipka směřuje k cílovému stavu.
pokud automaty zůstanou ve stejném stavu, nakreslí se šipka směřující ze stavu na sebe.
příklad; Předpokládejme, že FA přijme 3místnou binární hodnotu končící na 1.
PAK FA = {Q(q0, qf), Σ(0,1), q0, qf, δ}
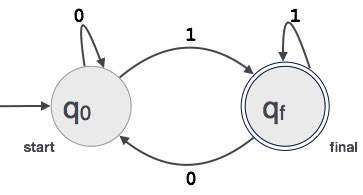
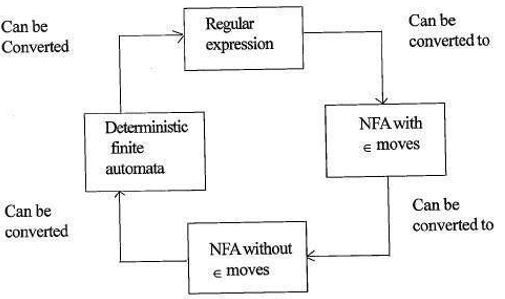
vztah regulárních výrazů a konečných automatů
vztah regulárních výrazů a konečných automatů je následující;
níže uvedený obrázek ukazuje, že je snadné převést;
- regulární výrazy na nedeterministické konečné automaty (NFA) s moves pohyby.
- nedeterministické konečné automaty s moves přesune na bez moves přesune
- nedeterministické konečné automaty bez ∈ přesune na deterministické konečné automaty (DFA).
- deterministické konečné automaty na regulární výraz.
Lex přijme regulární výrazy jako vstup a vrátí program, který simuluje konečný automat, aby rozpoznal regulární výrazy.
proto bude lex kombinovat generování řetězců (regulární výrazy definující řetězce, které jsou pro lex zajímavé) a rozpoznávání řetězců (konečný automat, který rozpoznává řetězce, které jsou předmětem zájmu).
pravidlo nejdelší shody
uvádí, že naskenovaný lexém by měl být určen na základě nejdelší shody mezi všemi dostupnými žetony.
slouží k vyřešení nejasností při rozhodování o dalším tokenu ve vstupním proudu.
při analýze zdrojového kódu bude lexikální analyzátor skenovat kódové písmeno po písmenu A když je detekován operátor, speciální symbol nebo mezery, rozhodne, zda je slovo úplné.
příklad:
int intvalue;při skenování výše uvedeného analyzátor nemůže určit, zda „int“ je klíčové slovo int nebo předpona identifikátoru intvalue.
použije se priorita pravidla, přičemž klíčové slovo bude mít přednost před vstupem uživatele, což znamená, že ve výše uvedeném příkladu analyzátor vygeneruje chybu.
lexikální chyby
lexikální chyba nastane, když sekvenci znaků nelze naskenovat do platného tokenu.
tyto chyby mohou být způsobeny chybným popisem identifikátorů, klíčových slov nebo operátorů.
obecně, i když velmi neobvyklé lexikální chyby jsou způsobeny nelegálními znaky v tokenu.
chyby mohou být;
- pravopisná chyba.
- transpozice dvou znaků.
- nelegální znaky.
- překročení délky identifikátoru nebo číselných konstant.
- nahrazení znaku nesprávným znakem
- odstranění znaku, který by měl být přítomen.
obnovení chyb znamená;
- odstranění jednoho znaku ze zbývajícího vstupu
- převedení dvou sousedních znaků
- odstranění jednoho znaku ze zbývajícího vstupu
- vložení chybějícího znaku do zbývajícího vstupu
- nahrazení znaku jiným znakem.
- ignorování po sobě jdoucích znaků, dokud se nevytvoří právní token (obnovení panického režimu).
schémata obnovení chyb
obnovení panického režimu.
v tomto schématu obnovy chyb jsou ze zbývajícího vstupu odstraněny bezkonkurenční vzory, dokud lexikální analyzátor nenajde dobře vytvořený token na začátku zbývajícího vstupu.
snadnější implementace je výhodou tohoto přístupu.
má omezení, že velké množství vstupu je přeskočeno bez kontroly dalších chyb.
Lokální Korekce.
když je zjištěna chyba v bodě vložení/odstranění a / nebo náhradní operace jsou prováděny, dokud není dosaženo dobře vytvořený text.
analyzátor se restartuje s výsledným novým textem jako vstupem.
Globální korekce.
jedná se o lepší obnovení panického režimu, pokud selže místní korekce.
má vysoké časové a prostorové požadavky, proto není prakticky implementován.
potřeba lexikálních analyzátorů
- Zlepšená efektivita kompilátoru-specializované vyrovnávací techniky pro čtení znaků urychlují proces kompilátoru.
- jednoduchost návrhu kompilátoru-odstranění bílých mezer a komentářů umožní efektivní syntaktické konstrukce pro analyzátor syntaxe.
- přenositelnost kompilátoru – pouze skener komunikuje s vnějším světem.
- Specializace-specializované techniky mohou být použity ke zlepšení procesu lexikální analýzy
problémy s lexikální analýzou
- Lookehead
vzhledem k tomu, vstupní řetězec, znaky jsou čteny zleva doprava jeden po druhém.
abychom zjistili, zda je token dokončen nebo ne, musíme se podívat na další znak.
příklad: je ‚ = ‚operátor přiřazení nebo první znak v‘ = = ‚ operátorovi.
Lookahead přeskočí znaky ve vstupu, dokud není nalezen dobře vytvořený token, což ukazuje, že pohled dopředu nemůže zachytit významné chyby kromě jednoduchých chyb, jako jsou nelegální symboly. - nejednoznačnosti
programy napsané pomocí lex budou akceptovat nejednoznačné specifikace a proto si vyberou nejdelší shodu a když se více výrazů shoduje se vstupem, preferuje se buď nejdelší shoda, nebo je upřednostněno první pravidlo mezi odpovídajícími pravidly. - vyhrazená klíčová slova
některé jazyky mají vyhrazená slova, která nejsou vyhrazena v jiných programovacích jazycích, např. elif je vyhrazené slovo v Pythonu, ale ne v C. - kontextová závislost
příklad:
vzhledem k příkazu DO 10 l = 10.86 je do10l identifikátor a DO Není Klíčové slovo.
a vzhledem k prohlášení DO 10 l = 10, 86, DO je klíčové slovo
taková prohlášení by vyžadovala podstatný pohled dopředu pro řešení.
aplikace
- používané kompilátory vytvářejí vyhovělé binární spustitelné soubory z analyzovaného kódu.
- používá webové prohlížeče pro formátování a zobrazení webové stránky, která je analyzována HTML, CSS a java script.
s tímto článkem v OpenGenus musíte mít silnou představu o lexikální analýze v návrhu kompilátoru.