denne artikel blev offentliggjort som en del af Data Science Blogathon.
“den største religion i verden er ikke engang en religion.”- Fernando Torres
introduktion
fodbold er elsket af alle, og dens skønhed ligger i dens uforudsigelige natur. En ting, der er stærkt forbundet med dette spil er dens fans, rugende og debattere før et spil over, hvem der vinder spillet. Og nogle fans går endda til grænsen for at spekulere i resultatlinjen før kampen. Så lad os prøve at besvare nogle af disse spørgsmål logisk.
Lær Poisson at kende
som jeg har sagt tidligere fodbold er et uforudsigeligt spil, kan et mål forekomme når som helst i kampen helt tilfældigt uden afhængighed af tidligere mål eller hold eller andre faktorer. Vent sagde Jeg “tilfældig”. Fordi der er en fordeling i statistik, der bruges til at finde sandsynlighederne for tilfældigt forekommende begivenheder, Poisson Distribution.
Antag, at din ven siger, at der i gennemsnit sker 2 mål pr. kamp, ja, har han ret? Hvis det er rigtigt, hvad er de faktiske chancer for at se to mål i en kamp? Her kommer til vores redning Poisson distribution hjælper os med at finde sandsynligheden for at observere ‘n’ begivenheder (Læs ‘n’ mål) i en fast tidsperiode, da vi giver det forventningen om begivenheder, der opstår (gennemsnitlige begivenheder pr.tidsperiode). Lad os se det matematisk en gang
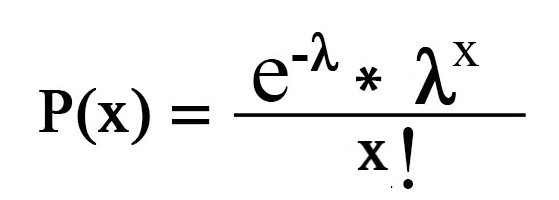
(periode)
chancer for at score
lad os nu besvare nogle spørgsmål med denne ligning, men først har vi brug for data, så for dette hentede jeg de internationale fodboldresultater fra 1872 til 2020 data fra Kaggle. En prøve af vores datasæt er vist nedenfor.
kode:
data.head(3)
.png)
lad os starte med at finde de gennemsnitlige mål, vi kan forvente inden for 90 minutter.
til dette har jeg oprettet et separat datasæt, der filtrerer data for kampe spillet i det 21.århundrede(2000-2020) og tilføjet home_score og væk_score for at finde ud af det samlede Nej. af mål, der forekommer i hver kamp og derefter taget gennemsnittet af kolonnen samlede mål for at få de gennemsnitlige mål, vi kan forvente i en kamp.
kode:
data=data+datadata=data.apply(lambda x : int(str.split(x,'-')))rec_data=data.loc>=2000)]rec_data.iloc]print(rec_data.total_goals.mean())
2.744112130054189
nu sætter denne forventning i Poissson Distribution formula lad os se, hvad er de faktiske chancer for at se 3 mål i en kamp.
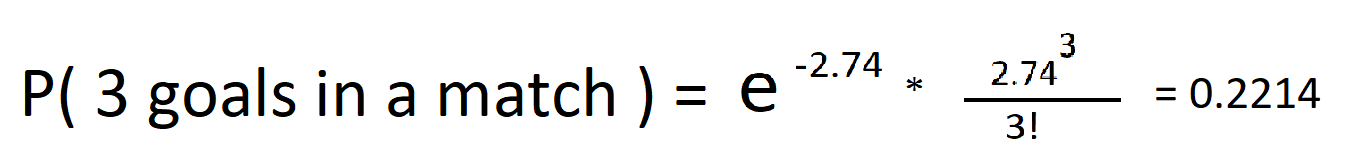
kun 22% chance. Lad os plotte sandsynlighederne for nej. mål i en kamp for at få et bedre billede.
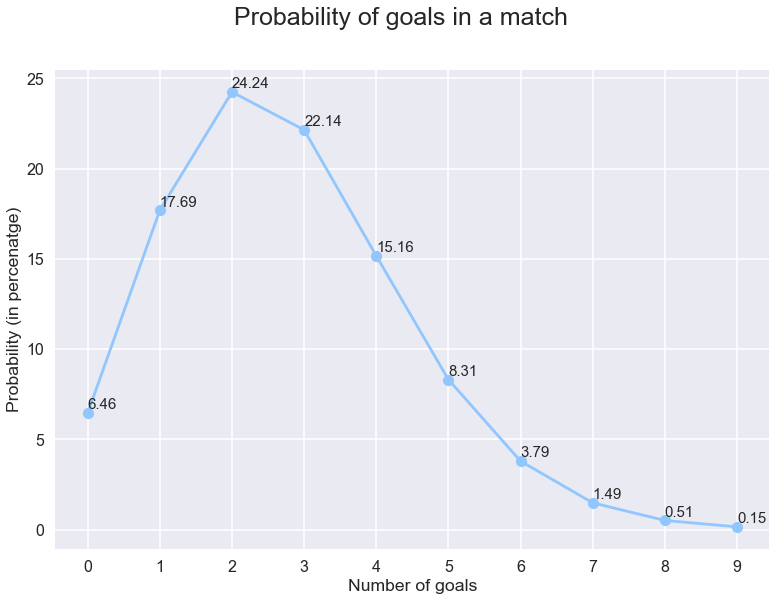
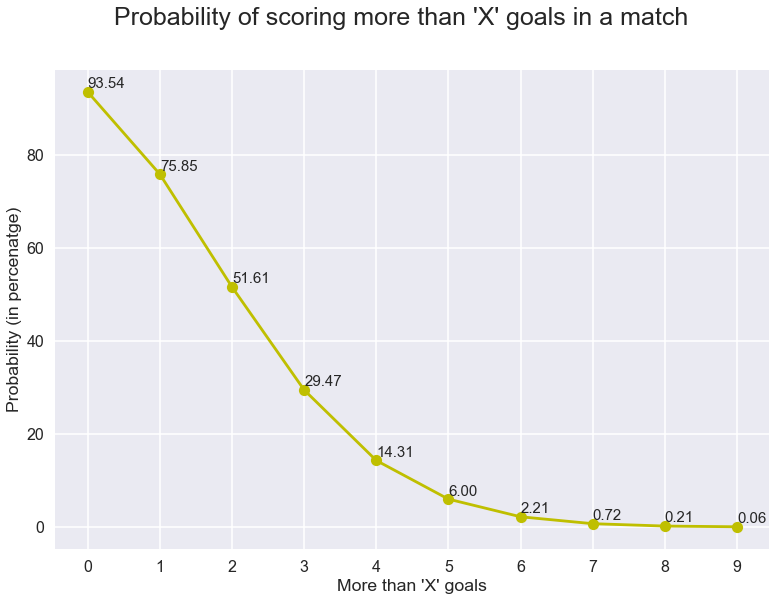
ud fra dette kan vi beregne sandsynligheden for at se ‘k ‘eller færre antal mål ved blot at tilføje sandsynlighederne for ‘K’ og de tal, der er mindre end ‘K’.Og ved blot at trække dette fra 1 kan vi få sandsynligheden for at se mere end ‘mål’ i en kamp. Lad os også plotte dette.
ventetiden er forbi …
Antag nu, at du har en utålmodig ven, der ikke vil sidde i hele spillet. Og han kommer til dig under en kamp og spørger, hvor meget tid har han til at vente med at se et mål. Det er et hårdt spørgsmål rigtigt, men bekymre dig ikke, bede ham om at sidde igennem 10000 spil og notere tiden mellem hvert mål. Bare for sjov, naturligvis, han ville flipper ud. Faktisk simulerede jeg 10000 kampe og fandt ud af den gennemsnitlige tid.
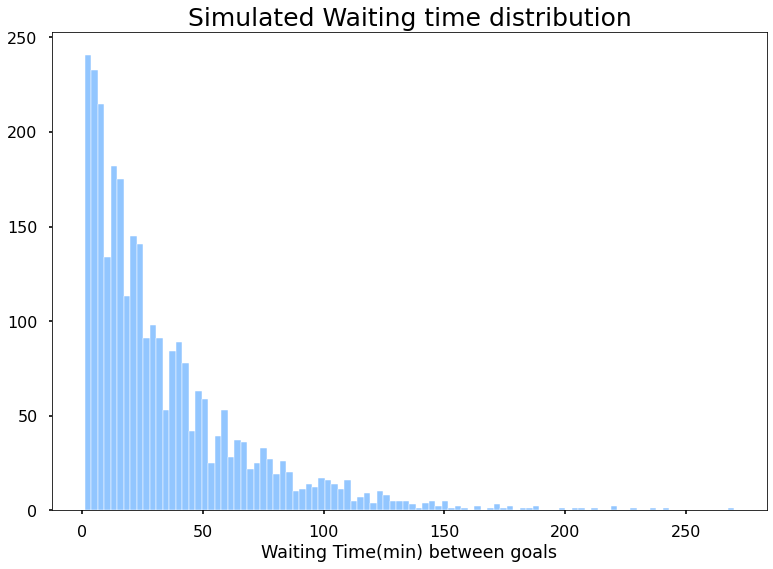
den mest sandsynlige ventetid er 2 minutter. Men vent dette faktisk ikke hvad jeg ledte efter, jeg vil have den gennemsnitlige tid, jeg skal vente med at se et mål, hvis jeg begynder at se spillet på et tilfældigt tidspunkt. Til det vil jeg tage 10000 tilfælde, hvor hver instans ser 10000 spil og beregner den gennemsnitlige ventetid mellem mål i de 10000 spil og rapporterer os. Endelig vil jeg plotte disse 10000 rapporter fra hver af mine tilfælde og finde ud af den forventede gennemsnitlige ventetid.
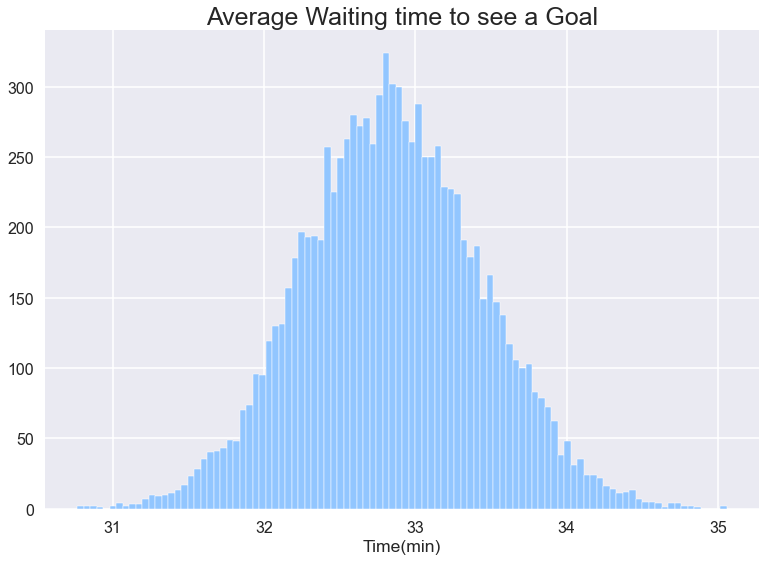
det ser ud til, at vi skal vente i 33 minutter ca. Men vi må muligvis vente på mere, Dette er et klassisk Ventetidsparadoks.
forudsigelse af resultatlinjen
endelig, lad os gøre det spørgsmål, som vi startede med, og det mest spændende spørgsmål om, hvem der vinder, og hvad der vil være resultatlinjen for at være præcis.
til dette vil jeg bruge historien mellem to hold (lad dem betragte som hjemmeholdet og udeholdet) og tage average_home_score som de forventede mål for hjemmeholdet og average_avay_score som de forventede mål for udeholdet og forudsige resultatlinjen ved hjælp af Poisson distribution. Hvis holdene har færre møder mellem dem, vil vi overveje et par faktorer
HS = middelværdi af hjemmemål scoret af hjemmeholdet gennem historien.
AS = gennemsnit af udebanemål scoret af Udehold gennem historien.
HC = gennemsnit af mål indkasseret i hjemmekampe af hjemmeholdet.
AC = gennemsnit af mål indkasseret i udekampe af udeholdet.
så hjemmeholdets forventede score beregnes som (HS + AC) / 2
så udeholdets forventede score beregnes som (AS + HC) / 2
Vent, den forventede score er ikke den forudsagte score. Den forventede score er det gennemsnitlige antal mål, vi forventer, at de scorer i et spil mellem dem.
kode:
import pandas as pdimport numpy as npfrom scipy import stats
def PredictScore(): home_team = input("Enter Home Team: ") ht = (''.join(home_team.split())).lower() away_team = input("Enter Away Team: ") at = (''.join(away_team.split())).lower() if len(data) > 20: avg_home_score = data.home_score.mean() avg_away_score = data.away_score.mean() home_goal = int(stats.mode(np.random.poisson(avg_home_score,100000))) away_goal = int(stats.mode(np.random.poisson(avg_away_score,100000))) else: avg_home_goal_conceded = data.away_score.mean() avg_away_goal_scored = data.away_score.mean() away_goal = int(stats.mode(np.random.poisson(1/2*(avg_home_goal_conceded+avg_away_goal_scored),100000))) avg_away_goal_conceded = data.home_score.mean() avg_home_goal_scored = data.home_score.mean() home_goal = int(stats.mode(np.random.poisson(1/2*(avg_away_goal_conceded+avg_home_goal_scored),100000))) avg_total_score = int(stats.mode( np.random.poisson((data.total_goals.mean()),100000))) print(f'Expected total goals are {avg_total_score}') print(f'They have played {len(data)} matches') print(f'The scoreline is {home_team} {home_goal}:{away_goal} {away_team}')
lad os prøve med Brasilien som hjemmeholdet og København som udeholdet.
kode:
PredictScore()
.png)
Poisson Distribution giver os en forudsigelse af, at Brasilien vinder med en 2-0 resultatlinje. Jeg søgte på nettet og fandt ud af, at den sidste kamp mellem dem blev spillet den 2.juli 2018, og resultatlinjen siger, at Brasilien vandt med 2-0. Jeg var heldig, måske ikke.
konklusion
hvis du vil udforske yderligere ingen bekymring, her er min kode. Desuden er dette kun en grundlæggende måde at forudsige spillet på, i dag bruges klassificeringsalgoritmer til at forudsige resultatet og regressionsalgoritmen til at forudsige resultatlinjen. Men det er emnet for en anden dag, indtil da have det sjovt at lege med dette. Adios!