i denne artikel skrevet af en leverandør af en sikkerhedsovervågningsløsning var hovedargumentet (ofte gentaget i andre publikationer og forskellige messer), at det er svært at lappe OT-systemer. Forfatteren hævder, at da det er svært, bør vi henvende os til andre metoder til at forbedre sikkerheden. Hans teori er at tænde en alarmteknologi som hans og parre de ventende alarmer med et sikkerhedshændelsesresponsteam. Med andre ord, bare acceptere patching er svært, give op og hæld flere penge til at lære tidligere (måske?) og reagere mere energisk.
men denne konklusion (patching er svært, så gider ikke) er defekt af et par grunde. For ikke at nævne, gloser han også over en meget stor faktor, der betydeligt komplicerer ethvert svar eller afhjælpning, der bør overvejes.
den første grund til, at dette er farligt råd, er, at du simpelthen ikke kan ignorere patching. Du skal gøre hvad du kan, når du kan, og når patching ikke er en mulighed, flytter du til plan B, C og D. At gøre ingenting betyder, at alle cyberrelaterede hændelser, der gør deres vej ind i dit miljø, vil producere maksimal skade. Dette lyder meget som M & m forsvar fra 20 år siden. Dette er ideen om, at din sikkerhedsløsning skal være hård og crunchy på ydersiden, men blød og sej på indersiden.
den anden grund til, at dette råd er defekt, er antagelsen om, at ot-sikkerhedspersonale (til hændelsesrespons eller patching) er lette at finde og implementere! Dette er ikke sandt – faktisk, en af ICS-sikkerhedshændelser, der henvises til i artiklen, påpeger, at mens en patch var tilgængelig og klar til installation, der var ingen ICS-eksperter til rådighed til at føre tilsyn med patch-installationen! Hvis vi ikke kan frigøre vores sikkerhedseksperter til at implementere kendt beskyttelse før begivenheden som en del af et proaktivt program til patch management, hvorfor tror vi, at vi kan finde budgettet til et fuldt hændelsesresponsteam efter det faktum, når det er for sent?
endelig er det manglende stykke fra dette argument, at udfordringerne til OT/ICS patch management forværres yderligere af mængden og kompleksiteten af aktiver og arkitektur i et OT-netværk. For at være klar, når en ny patch eller sårbarhed frigives, er de fleste organisationers evne til at forstå, hvor mange aktiver der er i omfang, og hvor de er, en udfordring. Men det samme niveau af indsigt og aktivprofiler kræves af ethvert hændelsesresponsteam for at være effektivt. Selv hans råd om at ignorere praksis med patching kan ikke lade dig undgå at skulle opbygge en robust, kontekstuel opgørelse (grundlaget for patching!) som et fundament for dit OT cybersikkerhedsprogram.
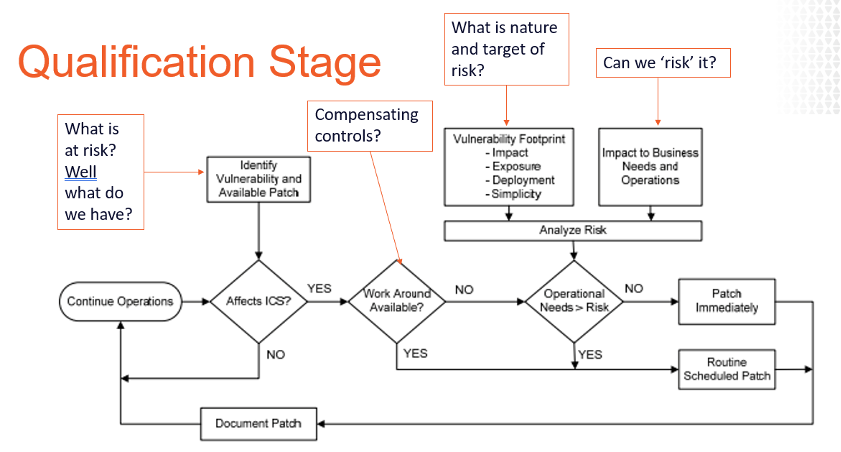
så hvad skal vi gøre? Først og fremmest skal vi forsøge at lappe. Der er tre ting, som et modent ICS patch management-program skal omfatte for at få succes:
- real-time, kontekstuel opgørelse
- automatisering af afhjælpning (både patch-filer og ad hoc-beskyttelse)
- identifikation og anvendelse af kompenserende kontroller
real-time kontekstuel opgørelse til patch management
de fleste OT-miljøer bruger scanningsbaserede lappeværktøjer som VSU/SCCM som er ret standard, men ikke alt for indsigtsfulde for at vise os, hvilke aktiver vi har, og hvordan de er konfigureret. Hvad der virkelig er behov for er robuste aktivprofiler med deres operationelle kontekst inkluderet. Hvad mener jeg med dette? Aktiv IP, model, OS osv. er en meget kortvarig liste over, hvad der kan være plads til den seneste patch. Hvad der er mere værdifuldt er den operationelle kontekst, såsom aktivkritikalitet for sikre operationer, aktivplacering, aktivejer osv. for at korrekt kontekstualisere vores nye risiko, fordi ikke alle OT-aktiver er skabt ens. Så hvorfor ikke først beskytte de kritiske systemer eller identificere egnede testsystemer (der afspejler kritiske feltsystemer) og strategisk reducere risikoen?
og mens vi bygger disse aktivprofiler, skal vi medtage så mange oplysninger som muligt om aktiverne ud over IP, Mac-adresse og OS-version. Oplysninger som installeret program, brugere / konto, porte, tjenester, registreringsdatabaseindstillinger, mindst privilegerede kontroller, AV, hvidliste og backup status osv. Disse typer informationskilder øger vores evne til nøjagtigt at prioritere og strategisere vores handlinger, når der opstår ny risiko. Vil du have bevis? Se på den sædvanlige analysestrøm, der tilbydes nedenfor. Hvor får du dataene til at besvare spørgsmålene i de forskellige faser? Tribal viden? Instinkt? Hvorfor ikke data?
Automatiser afhjælpning af programrettelser
en anden programrettelsesudfordring er implementering og forberedelse til at implementere programrettelser (eller kompenserende kontroller) til slutpunkterne. En af de mest tidskrævende opgaver i OT patch management er prep arbejde. Det omfatter typisk identificering af målsystemer, konfiguration af patchudrulningen, fejlfinding, når de fejler eller scanner først, skubber patchen og genscanning for at bestemme succes.
men hvad nu hvis du for eksempel næste gang en risiko som BlueKeep dukkede op, kunne forudindlæse dine filer på målsystemerne for at forberede dig til de næste trin? Du og dit mindre, mere smidige OT-sikkerhedsteam kunne strategisk planlægge, hvilke industrielle systemer du rullede patch-opdateringer til først, sekund, og tredje baseret på et hvilket som helst antal faktorer i dine robuste aktivprofiler som aktivplacering eller kritik.
hvis du tager det et skridt videre, kan du forestille dig, om patchstyringsteknologien ikke krævede en scanning først, men snarere allerede havde kortlagt patchen til aktiver i omfanget, og da du installerede dem (enten eksternt for lav risiko eller personligt for høj risiko), bekræftede disse opgaver deres succes og afspejlede denne fremgang i dit globale dashboard?
for alle dine højrisikoaktiver, som du ikke kan eller ikke vil lappe lige nu, Kan du i stedet oprette en port, service eller bruger/kontoændring som en ad hoc kompenserende kontrol. Så for en sårbarhed som BlueKeep kan du deaktivere fjernskrivebordet eller gæstekontoen. Denne tilgang reducerer øjeblikkeligt og markant den aktuelle risiko og giver også mere tid til at forberede sig på den eventuelle patch. Dette bringer mig til ‘fall back’ handlinger af hvad man skal gøre, når patching ikke er en mulighed – kompenserende kontroller.
Hvad er kompenserende kontroller?
kompenserende kontroller er simpelthen handlinger og sikkerhedsindstillinger, du kan og bør implementere i stedet for (eller rettere såvel som) patching. De implementeres typisk proaktivt (hvor det er muligt), men kan implementeres i en begivenhed eller som midlertidige beskyttelsesforanstaltninger, såsom deaktivering af Fjernskrivebord, mens du lapper til BlueKeep, som jeg udvider i casestudiet i slutningen af denne blog.
Identificer og anvend kompenserende kontroller i OT security
kompenserende kontroller tager mange former fra applikationshvidliste og holder antivirus opdateret. Men i dette tilfælde vil jeg fokusere på ICS endpoint management som en vigtig understøttende komponent i OT patch management.
kompenserende kontroller kan og bør bruges både proaktivt såvel som situationsmæssigt. Det ville ikke være nogen overraskelse for nogen I OT cyber security at opdage sovende administratorkonti og unødvendige eller ubrugte programmer installeret på endpoints. Det er heller ingen hemmelighed, at bedste praksis systemhærdningsprincipper ikke er nær så universelle, som vi gerne vil.
for virkelig at beskytte vores OT-systemer er vi også nødt til at hærde vores værdsatte ejendele. En robust aktivprofil i realtid giver industrielle organisationer mulighed for nøjagtigt og effektivt at rydde den lavthængende frugt (dvs.sovende brugere, unødvendige programmer og systemhærdningsparametre) for at reducere angrebsfladen markant.
i den uheldige begivenhed har vi en voksende trussel (som BlueKeep) at tilføje midlertidige kompenserende kontroller er gennemførligt. En hurtig casestudie for at fremhæve mit punkt:
- BlueKeep sårbarhed er frigivet.
- det centrale team deaktiverer straks remote desktop på alle feltaktiver og e-mails feltteam, der kræver specifikke anmodninger på system-for-system-basis for remote desktop service, der skal aktiveres i risikoperioden.
- Central team indlæser patch-filer på alle aktiver i omfanget-ingen handling, bare forbered dig.
- det centrale team indkalder til at beslutte den mest rimelige handlingsplan efter aktivkritikalitet, placering, tilstedeværelse eller fravær af kompenserende kontroller (dvs.en kritisk risiko for et aktiv med høj effekt, der mislykkedes dens sidste sikkerhedskopi, går til toppen af listen. En lav effekt aktiv med hvidlistning i kraft og en nylig god fuld backup kan sandsynligvis vente).
- Patching udrulning begynder, og fremskridt opdateres live i global rapportering.
- hvor det er nødvendigt, er OT-teknikere ved konsollen, der fører tilsyn med patch-implementeringen.
- tidsplanen og kommunikationen af dette behov er fuldt planlagt og prioriteret af de data, der bruges af det centrale team.
dette er, hvordan OT patch management skal håndteres. Og flere og flere organisationer begynder at sætte denne type program på plads.
Vær proaktiv med kompenserende kontroller
ICS patch management er svært, Ja, men det er heller ikke et godt svar at give op med at prøve. Med lidt fremsyn er det nemt at levere de tre mest kraftfulde værktøjer til lettere og mere effektiv patching og/eller kompenserende kontroller. Indsigt viser dig, hvad du har, hvordan det er konfigureret, og hvor vigtigt det er for dig. Kontekst giver dig mulighed for at prioritere (første forsøg på at lappe – andet giver dig mulighed for at vide, hvordan og hvor du skal anvende kompenserende kontroller). Handlingen giver dig mulighed for at rette, beskytte, afbøje osv. At kun stole på overvågning er at indrømme, at du forventer Brand, og at købe flere røgdetektorer kan minimere skaden. Hvilken tilgang tror du, at din organisation foretrækker?