i denne artikel diskuterer vi den første fase i compiler design, hvor højt niveau input program konverteres til en sekvens af tokens. Denne fase er kendt som leksikalsk analyse i Compiler Design.
Indholdsfortegnelse:
- definitioner til leksikalsk analyse
- et eksempel på leksikalsk analyse
- arkitektur af leksikalsk analysator
- regulære udtryk
- Finite Automata
- forholdet mellem regulære udtryk og finite automata
- længste Matchregel
- leksikale fejl
- fejlgendannelsesordninger
- behov for leksikale analysatorer
- behov for leksikale analysatorer
leksikalsk analyse er processen med at konvertere en sekvens af tegn fra et kildeprogram, Der tages som input til en sekvens af tokens.
et program, der genererer leksikalske analysatorer.
en leksikalsk analysator/leksikalsk/scanner er et program, der udfører leksikalsk analyse.
den leksikalske analysators roller medfører;
- læsning af input tegn fra kilde program.
- korrelation af fejlmeddelelser med kildeprogrammet.
- striber hvide mellemrum og kommentarer fra kildeprogrammet.
- udvidelses makroer, hvis de findes i kildeprogrammet.
- indtastning af identificerede tokens til symboltabellen.
Lekseme er en forekomst af et token, det vil sige en sekvens af tegn inkluderet i kildeprogrammet i henhold til det matchende mønster af et token.
et eksempel, givet udtrykket;
c = A + b * 5
leksemerne og tokens er;
| Leksemer | Tokens |
|---|---|
| C | identifikator |
| = | tildelingssymbol |
| a | identifikator |
| + | +(tilføjelsessymbol) |
| B | identifikator |
| * | *(multiplikation symbol) |
| 5 | 5(nummer) |
sekvensen af tokens produceret af den leksikalske analysator gør det muligt for parseren at analysere syntaksen for en programmeringssprog.
et token er en gyldig sekvens af tegn givet af et leksem, det behandles som en enhed i programmeringssprogets grammatik.
i et programmeringssprog kan dette omfatte;
- nøgleord
- operatorer
- tegnsætningssymboler
- konstanter
- identifikatorer
- tal
et mønster er en regel matchet af en sekvens af tegn(leksemer), der bruges af token. Det kan defineres ved regulære udtryk eller grammatiske regler.
et eksempel på leksikalsk analyse
kode
#include<iostream>// exampleint main(){ int a, b; a = 7; return 0;}Tokens
| Leksemer | Tokens |
|---|---|
| int | søgeord |
| vigtigste | søgeord |
| ( | operatør |
| ) | operatør |
| { | operatør |
| int | søgeord |
| a | identifikator |
| , | operatør |
| b | identifikator |
| ; | operatør |
| a | identifikator |
| = | tildelingssymbol |
| 10 | 10(nummer) |
| ; | operatør |
| retur | søgeord |
| 0 | 0(nummer) |
| ; | operatør |
| } | operatør |
ikke Tokens
| Type | Tokens |
|---|---|
| præprocessordirektivet | #include<iostream> |
| kommentar | / / eksempel |
processen med leksikalsk analyse består af to faser.
- Scanning – dette indebærer læsning af input tegnog fjernelse af hvide mellemrum og kommentarer.
- tokenisering – dette er produktionen af tokens som output.
arkitektur af leksikalsk analysator
den leksikalske analysators hovedopgave er at scanne hele kildeprogrammet og identificere tokens en efter en.
Scannere implementeres for at producere tokens, når parseren anmoder om det.

trin:
- “få næste token” sendes fra parseren til den leksikalske analysator.
- den leksikalske analysator scanner indgangen, indtil “næste token” er placeret.
- tokenet returneres til parseren.
regulære udtryk
vi bruger regulære udtryk til at udtrykke endelige sprog ved at definere mønstre for et endeligt sæt symboler.
grammatik defineret af regulære udtryk er kendt som regelmæssig grammatik, og det sprog, der er defineret af regelmæssig grammatik, er kendt som almindeligt sprog.
der er algebraiske regler, der overholdes af regulære udtryk, der bruges til at manipulere regulære udtryk til ækvivalente former.
operationer.
forening af to sprog A og B er skrevet som
A U B = {s | S er i A eller s er i B}
sammenkædning af to sprog A og B er skrevet som
AB = {ss | S er i A og s er i B}
Kleen-lukningen af et sprog a er skrevet som
A* = hvilket er nul eller flere forekomster af sprog A.
notationer.
hvis H og y er regulære udtryk, der betegner sprog A(H) og B(y), er
(H) et regulært udtryk, der angiver A(H).
Union (H) / (y) er et regulært udtryk, der betegner A(H) B (y).
Sammenkædning(K) (y) er et regulært udtryk denting a(k)B (y).
Kleen lukning( H)*er et regulært udtryk, der betegner (A(H)) *
forrang og associativitet.
*’ sammenkædning .’og / (pipe) er tilbage associative.
Kleen Lukning * har den højeste forrang.
Sammenkædning (.) følger forrang.
(rør) / har den laveste forrang.
repræsenterer gyldige tokens af et sprog i regulære udtryk.
er derfor et regulært udtryk;
- * repræsenterer en eller flere forekomst af*, dvs.
- *? 2795>
- repræsenterer alle små bogstaver alfabeter på engelsk.
- repræsenterer alle store bogstaver alfabeter på engelsk.
- repræsenterer alle naturlige tal.
repræsenterer forekomst af symboler ved hjælp af regulære udtryk
bogstav = eller
ciffer = eller|0|1|2|3|4|5|6|7|8|9
Sign =
repræsenterer sprog tokens ved hjælp af regulære udtryk.
Decimal = (tegn)?(ciffer)+
Identifier = (letter) (letter | ciffer)*
Finite Automata
dette er kombinationen af fem tupler (K, K, K0, KF, KF) med fokus på tilstande og overgange gennem inputsymboler.
det genkender mønstre ved at tage symbolstrengen som input og ændrer dens tilstand i overensstemmelse hermed.
den matematiske model for finite automata består af;
- endeligt sæt af tilstande(K)
- endeligt sæt af inputsymboler(L)
- en starttilstand(K0)
- sæt af endelige tilstande (KF)
- overgangsfunktion(l)
Finite automata bruges i leksikalsk analyse til at producere tokens i form af identifikatorer, nøgleord og konstanter fra inputprogrammet.
Finite automata føder den regulære udtryksstreng, og tilstanden ændres for hver bogstavelig.
hvis input behandles med succes, når automaten den endelige tilstand og accepteres ellers afvises den.
konstruktion af Finite Automata
lad L(r) være et almindeligt sprog af nogle finite automata F(A).
derfor;
- Stater: cirkler repræsenterer staterne i FA, og deres navne er skrevet inde i cirklerne.
- starttilstand: dette er den tilstand, hvor automaten starter. Det vil have en pil, der peger mod den.
- Mellemtilstande: disse har to pile, den ene peger på den og den anden peger ud fra mellemtilstandene.
- Endelig Tilstand: Automata forventes at være i den endelige tilstand, når inputstrengen er blevet analyseret med succes og repræsenteret af dobbeltcirkler, ellers afvises input. Det kan indeholde et ulige antal pile, der peger mod det, og et lige antal, der peger ud fra det, det vil sige
ulige pile = lige pile + 1. - overgang: når et ønsket symbol findes i input, vil overgangen fra en tilstand til en anden tilstand ske. Automaten flytter enten til den næste tilstand eller fortsætter.
en rettet pil viser bevægelsen fra en tilstand til en anden, mens en pil peger mod destinationstilstanden.
hvis automaten forbliver i samme tilstand, tegnes en pil, der peger fra en tilstand til sig selv.
et eksempel; Antag, at en 3-cifret binær værdi, der slutter i 1, accepteres af FA.
så FA = {K (K0, KF), LF (0,1), K0, KF, LF}
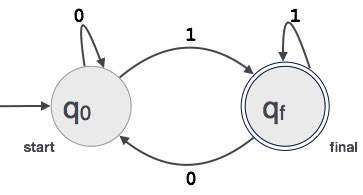
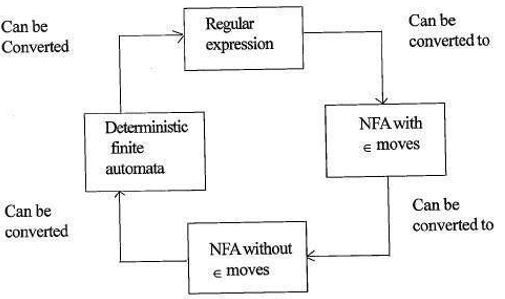
forholdet mellem regulære udtryk og finite automata
forholdet mellem regulært udtryk og finite automata er som følger;
figuren nedenfor viser, at det er let at konvertere;
- regulære udtryk til ikke-deterministisk finite automata(NFA) med kursbevægelser.
- ikke-deterministisk finite automata med purpur flytter til uden purpur moves
- Non-deterministisk finite automata uden purpur flytter til deterministisk Finite Automata(DFA).
- deterministisk Finite Automata til Regulært udtryk.
en LEKS accepterer regulære udtryk som input og returnerer et program, der simulerer en endelig automat for at genkende de regulære udtryk.
derfor kombinerer vi string pattern generation (regulære udtryk, der definerer strengene af interesse for Lek) og string pattern recognition (en endelig automat, der genkender strengene af interesse).
længste Kampregel
det hedder, at leksemet scannet skal bestemmes ud fra den længste kamp blandt alle tilgængelige tokens.
dette bruges til at løse uklarheder, når man beslutter det næste token i inputstrømmen.
under analyse af kildekoden scanner den leksikale analysator kode bogstav for bogstav, og når en operatør, et specielt symbol eller et hvidt rum registreres, beslutter det, om et ord er komplet.
eksempel:
int intvalue;under scanning af ovenstående kan analysatoren ikke bestemme, om ‘int’ er et nøgleord int eller præfikset for identifikatoren intvalue.
Regelprioritet anvendes, hvorved et nøgleord prioriteres frem for brugerinput, hvilket betyder i ovenstående eksempel, at analysatoren genererer en fejl.
leksikalske fejl
en leksikalsk fejl opstår, når en tegnsekvens ikke kan scannes til et gyldigt token.
disse fejl kan skyldes stavefejl i identifikatorer, nøgleord eller operatorer.
generelt selvom meget ualmindelige leksikalske fejl er forårsaget af ulovlige tegn i et token.
fejl kan være;
- stavefejl.
- gennemførelse af to tegn.
- ulovlige tegn.
- overstiger længden af identifikator eller numeriske konstanter.
- udskiftning af et tegn med et forkert tegn
- fjernelse af et tegn, der skal være til stede.
fejlgendannelse indebærer;
- fjernelse af et tegn fra det resterende input
- gennemførelse af to tilstødende tegn
- sletning af et tegn fra det resterende input
- indsættelse af manglende tegn i det resterende input
- udskiftning af et tegn med et andet tegn.
- ignorerer successive tegn, indtil der dannes et juridisk token(panic mode recovery).
fejlgendannelsesordninger
gendannelse af paniktilstand.
i denne fejlgendannelsesordning slettes uovertrufne mønstre fra den resterende indgang, indtil den leksikale analysator kan finde et velformet token i begyndelsen af den resterende indgang.
nemmere implementering er en fordel for denne tilgang.
det har den begrænsning, at en stor mængde input springes over uden at kontrollere for yderligere fejl.
Lokal Korrektion.
når der registreres en fejl ved et punkt, udføres indsættelse/sletning og/eller udskiftning, indtil der opnås en velformet tekst.
analysatoren genstartes med den resulterende nye tekst som input.
global korrektion.
det er en forbedret gendannelse af paniktilstand, der foretrækkes, når lokal korrektion mislykkes.
det har høje krav til tid og plads, derfor implementeres det ikke praktisk.
behov for leksikalske analysatorer
- forbedret compiler effektivitet – specialiserede buffering teknikker til læsning tegn fremskynde compiler proces.
- enkelhed af compiler design – fjernelse af hvide rum og kommentarer vil muliggøre effektive syntaktiske konstruktioner til syntaksanalysatoren.
- Compiler portabilitet – kun scanneren kommunikerer med den eksterne verden.
- specialisering – specialiserede teknikker kan bruges til at forbedre leksikalsk analyseproces
problemer med leksikalsk analyse
- Lookahead
givet en inputstreng læses tegn fra venstre mod højre en efter en.
for at afgøre, om et token er færdigt eller ej, skal vi se på det næste tegn.
eksempel: er ‘ = ‘ en tildelingsoperator eller det første tegn i ‘==’ operator.
Lookahead springer tegn i input, indtil et velformet token er fundet, dette viser, at se fremad ikke kan fange væsentlige fejl undtagen simple fejl som ulovlige symboler. - uklarheder
programmerne, der er skrevet med LEKS, accepterer tvetydige specifikationer og vælger derfor det længste match, og når flere udtryk matcher input, foretrækkes enten det længste match, eller den første regel blandt de matchende regler prioriteres. - reserverede nøgleord
visse sprog har reserverede ord, som ikke er reserveret på andre programmeringssprog, f.eks. elif er et reserveret ord i python, men ikke i C. - Kontekstafhængighed
eksempel:
i betragtning af udsagnet DO 10 l = 10.86 er DO10l en identifikator, og DO er ikke et nøgleord.
og givet udsagnet DO 10 l = 10, 86, DO er et nøgleord
sådanne udsagn ville kræve et betydeligt kig fremad for opløsning.
applikationer
- brugt af kompilatorer opretter overholdt binære eksekverbare filer fra parset kode.
- bruges til at formatere og vise en hjemmeside, der er analyseret HTML, CSS og java script.
med denne artikel på OpenGenus skal du have en stærk ide om leksikalsk analyse i Compiler Design.