med komplekse netværk bestående af Sky, hybrid IT, virtualisering, lagringsområde netværk og så videre kan mangesidede IT-problemer være vanskelige at lokalisere og diagnosticere. Når et problem opstår, for eksempel en dårligt udført applikation eller server, kan undersøgelsen tage lang tid at finde kerneproblemet. Problemet kan være i opbevaring, netværksforbindelse, brugeradgang eller en blanding af ressourcer og konfigurationer.
hvis du vil undersøge problemet, skal du oprette fejlfindingsprojekter med dashboardet Performance Analysis (PerfStack), der visuelt korrelerer Historiske data fra flere Solvindprodukter og enhedstyper i en enkelt visning.
med dashboards til Ydelsesanalyse kan du gøre følgende:
- sammenligne og analysere flere metriske typer i en enkelt visning, herunder status, begivenheder og statistik.
- Sammenlign og analyser metrics for flere enheder i en enkelt visning, herunder noder, grænseflader, volumener, applikationer og meget mere.
- korrelerer data fra hele Orion-platformen på en enkelt delt tidslinje.
- Visualiser hybride data for on-premises, cloud og alt derimellem.
- Del et fejlfindingsprojekt med dine teams og eksperter for at gennemgå Historiske data for et problem.
for VMAN er mulighederne uendelige for applikationsanalyse og hybridmiljøer:
- gå visuelt gennem Historiske data for VM ‘er i dit miljø
- Bekræft problemer med ressourceallokering i hybridmiljøer
- korrelere data til fejlfinding af netværkstrafik sendt og modtaget af virtuelle servere (værter, klynger, datalagre og VM’ er), lokale servere og skyinstanser
følgende eksempel viser dig, hvordan du identificerer en grundårsag til en virtuel server (værter, klynger, datalagre og VM ‘ er) VM oplever problemer med ydeevnen. I dette scenario stødte en virtuel vært på et ressource-og ydelsesproblem til det punkt, hvor brugerne støder på langsommere svar og adgang. Problemet udløste en advarsel, der underrettede din applikationsejer, der eskalerede problemet til system-og netværksadministratorer.
Opret et nyt fejlfindingsprojekt for at undersøge problemet for at sammenligne målinger for værten og alle relaterede virtuelle miljøsystemer for at spore tendenser og stigninger i brugen.
-
i Orion-konsollen skal du vælge Mine Dashboards > hjem > Ydelsesanalyse.
dette åbner dashboardet Performance Analysis, eller PerfStack, for at opbygge diagrammer og grafer ved hjælp af metrics trukket fra overvågede applikationer og servere i den metriske Palette. Hvert diagram kan indeholde flere metrics for direkte at korrelere data.
-
klik på Tilføj enheder i Det Nye analyseprojekt.
for at komme i gang skal du finde og tilføje VM i nød. I søgefeltet skal du indtaste syd for at få vist en liste over virtuelle servere, der deler dette navn. Udvid og vælg typer eller Status for at filtrere listen, hvis det er nødvendigt.
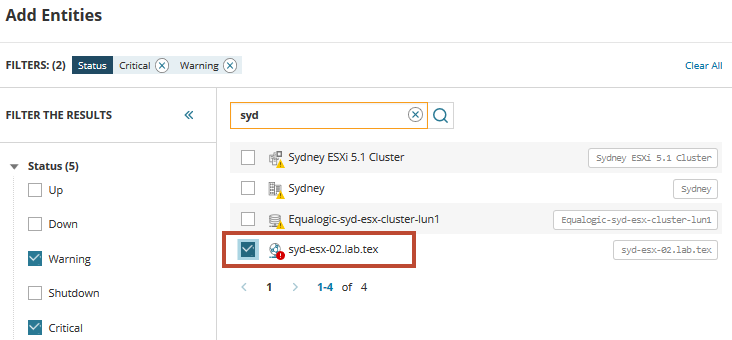
fra listen finder vi den virtuelle vært, der støder på problemerne og udløser alarmer. Vælg værten, og føj den til instrumentbrættets metriske palet. Klik på ikonet relaterede enheder for at få vist alle relaterede servere og tjenester til værten.
interesseret i alle tilknyttede noder, applikationer, servere og mere til denne valgte node? Klik på ikonet relaterede enheder.
 alle relaterede enheder vises i paletten metrisk, hvilket giver flere muligheder for metrics, der muligvis forårsager problemer.
alle relaterede enheder vises i paletten metrisk, hvilket giver flere muligheder for metrics, der muligvis forårsager problemer.
-
Vælg syd host node for at se, og vælg metrics for at trække og slippe på instrumentbrættet. Du kan trække dem ind i det samme diagram for at sammenligne værdier mellem metrics.
for at begynde at undersøge, skal du trække en række målinger for værten og klyngen, sammenligne målinger for at finde pigge eller høj brug. I dette scenarie skal du tilføje disse værtsmetrikker:
- maksimal netværksforbrug
- maksimal Netværkstransmissionshastighed
- maksimal Netværksmodtagehastighed
- virtuelle maskiner kører
for klyngen skal du tilføje disse målinger:
- gennemsnitlig CPU-belastning
- gennemsnitlig CPU-brug
diagrammerne og graferne vises med data og advarsler for de sidste 12 timers målinger. Du kan udvide dato og klokkeslæt for at se yderligere historiske målinger i løbet af advarslen.
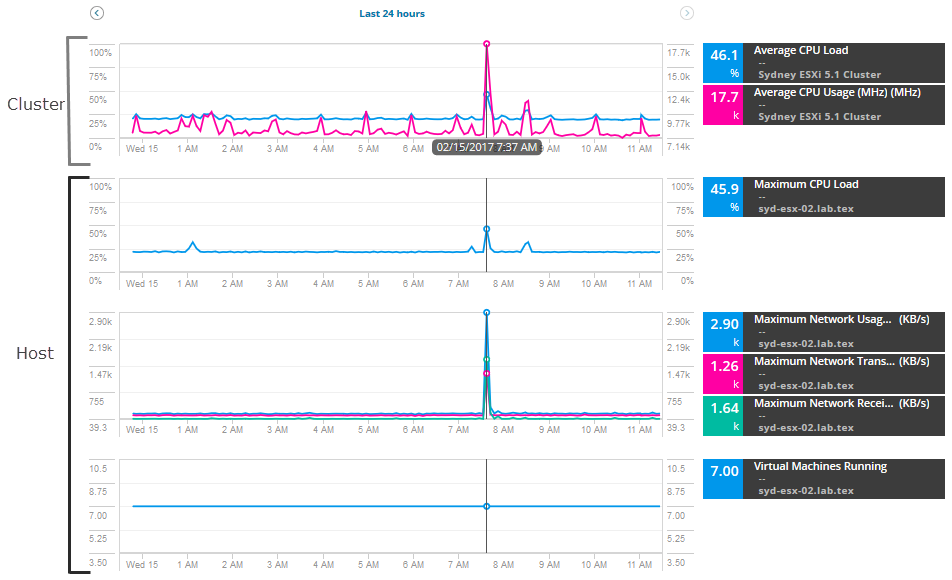
Tilføj brugsmålinger for VM ‘ er på værten for at sammenligne netværksbrug og aktivitet.
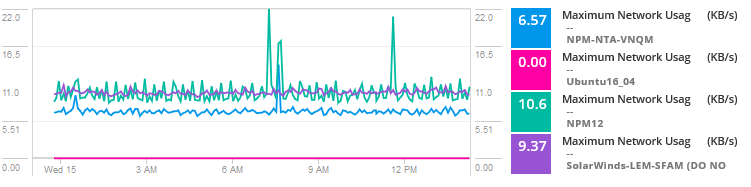
-
ved at analysere dataene ser problemet ud til at være en støjende nabo for en af de virtuelle maskiner, der bruger ressourcer og oplever høj trafik, der forårsager flaskehalse og problemer for VM ‘ er, der deler værten. Grundlæggende bruger en anden server, service eller applikation højere båndbredde, disk I/O, CPU og andre ressourcer, der forårsager problemer for denne specifikke applikation.
disse oplysninger giver dit netværk og systemadministratorer en retning for yderligere undersøgelse og løsning af latensproblemer. For at løse kan de omfordele ressourcer eller flytte applikationen med højt forbrug til en anden placering.
-
Klik på Gem, og giv projektet et navn.
projektet gemmes som et dashboard med de valgte metrics i det indstillede dato-og tidsinterval.
når den gemmes, bliver URL ‘ en et delbart link. Kopier og del linket til det gemte dashboard i billetter eller e-mails sendt af system-og netværksadministratorer og produktejeren. De kan få adgang til linket for at gennemgå de indsamlede data og fejlfinding.
når du har omfordelt ressourcer og foretaget netværksændringer, skal du åbne dashboardet igen for at verificere ændringer og nye brugstendenser for adspurgte metrics.