
Reverse Engineering eines Modells aus einer Datenbank oder einem Skript
Beim Reverse Engineering wird ein Datenmodell aus einer Datenbank oder einem Skript erstellt. Das Modellierungswerkzeug erstellt eine grafische Darstellung der ausgewählten Datenbankobjekte und der Beziehungen zwischen den Objekten. Diese grafische Darstellung kann ein logisches oder ein physikalisches Modell sein.
Hinweis: Sie können das Reverse Engineering nur in ein leeres Modell durchführen. Sie können kein Reverse Engineering in ein Modell durchführen, das Objekte enthält.
Eine Datenbank kann aus folgenden Gründen rückentwickelt werden:
- Um zu verstehen, wie die Objekte miteinander verwandt sind, und dann darauf aufzubauen
- Um die Datenbankstruktur zu demonstrieren
Nach Abschluss des Reverse Engineering-Prozesses können Sie die folgenden Aufgaben ausführen:
- Fügen Sie neue Datenbankobjekte hinzu
- Erstellen Sie die Systemdokumentation
- Passen Sie die Datenbankstruktur an Ihre Anforderungen an
Die meisten Informationen, die Sie zurückentwickeln, sind explizit im physischen Schema definiert. Das Reverse Engineering leitet jedoch auch Informationen aus dem Schema ab und integriert sie in das Modell. Wenn das Ziel-DBMS beispielsweise Fremdschlüsseldeklarationen unterstützt, leitet der Reverse Engineering-Prozess identifizierende und nicht identifizierende Beziehungen und Standardrollennamen ab.
Sie können alle wichtigen Modellinformationen mit Ausnahme von Subtypbeziehungen ableiten, da derzeit kein SQL-Datenbankverwaltungssystem dies unterstützt. Die Zieldatenbanken unterscheiden sich jedoch in der Menge der Informationen zum logischen Datenmodell, die im physischen Schema enthalten sind. Aus diesem Grund können die resultierenden Modelle je nach ausgewählter Zieldatenbank variieren. Sie können auch einige logische Informationen einschließlich Primärschlüssel, Fremdschlüssel und Tabellenbeziehungen ableiten. Sie können die Tabellenindexdefinitionen oder Spaltennamen verwenden, um diese Schlüssel und Beziehungen abzuleiten.
Sie können RI-Trigger in den Reverse Engineering-Prozess einbeziehen oder ausschließen. Sie können RI-Trigger als Modellobjekte behandeln oder die Option Forward Engineering verwenden, um RI-Trigger in das Schema aufzunehmen. Sie können diese Optionen auch während des Reverse Engineerings ein- oder ausschließen.
Beim Reverse Engineering einer Datenbank können Sie eine Ablaufverfolgungsdatei festlegen, um die Abfragen aufzuzeichnen, die zum Abrufen von Objekten ausgeführt werden. Sie können die Abfragen nach Abschluss des Reverse Engineering-Prozesses überprüfen.
Das folgende Diagramm veranschaulicht die Schritte zum Reverse Engineering eines Modells aus einer Datenbank oder einem Skript:
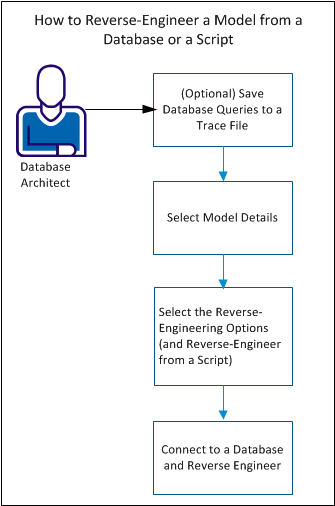
Führen Sie die folgenden Schritte aus, um ein Modell zurückzuentwickeln:
- ( Optional) Speichern Sie Datenbankabfragen in einer Trace-Datei.
- Modelldetails auswählen.
- Wählen Sie die Reverse Engineering-Optionen.
- Stellen Sie eine Verbindung zu einer Datenbank her und führen Sie ein Reverse Engineering durch.
Reverse Engineering Spezifischer Objekte
Dieser Abschnitt enthält Details zur Funktionsweise des Reverse Engineering-Prozesses für verschiedene Datenbankobjekte.
Index
Beim Reverse Engineering einer Datenbank werden Name, Definition und Parameter jedes auf dem Server definierten Index importiert. Wenn Sie die Indexinformationen von einem Server importieren, werden die Speicherortinformationen für jeden Index beibehalten. Daher können Sie die Datenbank mit denselben Speicherzuweisungen neu erstellen. Sie müssen den Speicherort nicht für jeden Index manuell neu zuweisen.
Nachdem Sie Indizes importiert haben, können Sie die Indexeigenschaften, Definitionen und Tabellenzuordnungen im Dialogfeld Indizes anzeigen oder ändern. Sie können einem physischen Speicherobjekt im Dialogfeld Indizes für eine DB2 z/OS-, Informix-, Oracle-, SQL Server- und SAP ASE-Datenbank einen Index zuweisen. Wenn Ihre Zieldatenbank DB2 z/OS, Informix und Oracle ist, können Sie die Speicherparameter auch im Dialogfeld Indizes ändern.
Wenn eine physische Speicheroption für eine DB2 z/OS-, Informix-, Oracle- oder SAP ASE-Datenbank ausgewählt ist, enthält das Schema Indexparameter für physischen Speicher.
Physisches Speicherobjekt
Beim Reverse Engineering einer Datenbank können Sie die Namen und Definitionen physischer Speicherobjekte importieren, die Sie auf dem Zielserver definiert haben. Der Import erfolgt auf die gleiche Weise, wie physische Tabellen, Indizes und andere physische Schemainformationen importiert werden. Nachdem Sie physische Speicherobjekte importiert haben, können Sie die Objektdefinitionen und Tabellenzuordnungen mit den Standardeditoren anzeigen oder ändern.
Validierungsregel
Beim Reverse Engineering aus einer Schemadatei, einem Skript oder einem Systemkatalog werden Validierungsregeln importiert und an die entsprechende Tabelle oder Spalte im resultierenden Modell angehängt. Die Konvention, die verwendet wird, um die importierten Validierungsregeln zu benennen, lautet wie folgt:
VALID_RULEn
Hier ist n eine fortlaufende Zahl, die bei Null beginnt. Die erste Validierungsregel, die gefunden wird, heißt VALID_RULE0, die nächste Regel VALID_RULE1 usw., bis das gesamte Schema verarbeitet ist.