Bei komplexen Netzwerken, die aus Cloud, Hybrid-IT, Virtualisierung, Storage Area Networks usw. bestehen, können facettenreiche IT-Probleme schwer zu lokalisieren und zu diagnostizieren sein. Wenn ein Problem auftritt, z. B. eine schlecht funktionierende Anwendung oder ein Server, kann die Untersuchung viel Zeit in Anspruch nehmen, um das Kernproblem zu lokalisieren. Das Problem kann im Speicher, in der Netzwerkkonnektivität, im Benutzerzugriff oder in einer Mischung aus Ressourcen und Konfigurationen liegen.
Um das Problem zu untersuchen, erstellen Sie Projekte zur Fehlerbehebung mit dem Perfstack™-Dashboard (Performance Analysis), mit dem Verlaufsdaten mehrerer SolarWinds-Produkte und -Entitätstypen in einer einzigen Ansicht visuell korreliert werden.
Mit Dashboards zur Leistungsanalyse können Sie Folgendes tun:
- Vergleichen und analysieren Sie mehrere Metriktypen in einer einzigen Ansicht, einschließlich Status, Ereignissen und Statistiken.
- Vergleichen und analysieren Sie Metriken für mehrere Entitäten in einer einzigen Ansicht, einschließlich Knoten, Schnittstellen, Volumes, Anwendungen und mehr.
- Korrelieren Sie Daten aus der gesamten Orion-Plattform auf einer einzigen gemeinsamen Zeitlinie.
- Visualisieren Sie hybride Daten für On-Premises, Cloud und alles dazwischen.
- Teilen Sie Ihren Teams und Experten ein Projekt zur Fehlerbehebung mit, um historische Daten für ein Problem zu überprüfen.
Für VMAN sind die Möglichkeiten für Anwendungsanalysen und hybride Umgebungen endlos:
- Visueller Überblick über historische Daten für VMs in Ihrer Umgebung
- Überprüfen von Ressourcenzuordnungsproblemen in Hybridumgebungen
- Korrelieren von Daten zur Fehlerbehebung bei Netzwerkdatenverkehr, der von virtuellen Servern (Hosts, Clustern, Datenspeichern und VMs), lokalen Servern und Cloud-Instanzen gesendet und empfangen wird
Im folgenden Beispiel wird gezeigt, wie Sie eine Grundursache für eine VM mit Leistungsproblemen. In diesem Szenario ist ein virtueller Host auf ein Ressourcen- und Leistungsproblem gestoßen, sodass Benutzer auf langsamere Antworten und langsameren Zugriff stoßen. Das Problem löste eine Warnung aus, die den Anwendungseigentümer benachrichtigte, der das Problem an System- und Netzwerkadministratoren weiterleitete.
Erstellen Sie ein neues Projekt zur Fehlerbehebung, um das Problem zu untersuchen und Metriken für den Host und alle zugehörigen virtuellen Umgebungssysteme zu vergleichen, um Trends und Spitzenwerte bei der Nutzung zu verfolgen.
-
Wählen Sie in der Orion-Webkonsole Meine Dashboards > Startseite > Leistungsanalyse aus.
Dies öffnet das Dashboard für die Leistungsanalyse oder PerfStack, um Diagramme und Grafiken mit Metriken zu erstellen, die aus überwachten Anwendungen und Servern in der Metrikpalette abgerufen wurden. Jedes Diagramm kann mehrere Metriken enthalten, um Daten direkt zu korrelieren.
-
Klicken Sie im neuen Analyseprojekt auf Entitäten hinzufügen.
Um zu beginnen, müssen Sie die betreffende VM suchen und hinzufügen. Geben Sie im Suchfeld syd ein, um eine Liste der virtuellen Server mit diesem Namen aufzurufen. Erweitern und wählen Sie Typen oder Status, um die Liste bei Bedarf zu filtern.
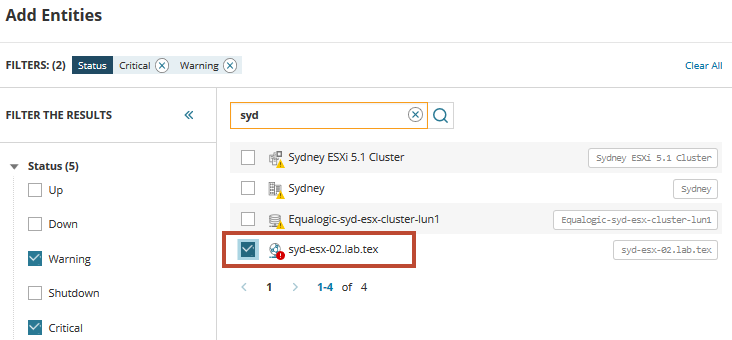
Aus der Liste finden wir den virtuellen Host, der auf die Probleme stößt und Warnungen auslöst. Wählen Sie den Host aus und fügen Sie ihn der Dashboard-Metrikpalette hinzu. Klicken Sie auf das Symbol zugehörige Entitäten, um alle zugehörigen Server und Dienste für den Host anzuzeigen.
Interessieren Sie sich für alle Knoten, Anwendungen, Server und mehr, die diesem ausgewählten Knoten zugeordnet sind? Klicken Sie auf das Symbol verwandte Entitäten.
 Alle zugehörigen Entitäten werden in der Metrikpalette angezeigt und bieten mehr Optionen für Metriken, die möglicherweise Probleme verursachen.
Alle zugehörigen Entitäten werden in der Metrikpalette angezeigt und bieten mehr Optionen für Metriken, die möglicherweise Probleme verursachen.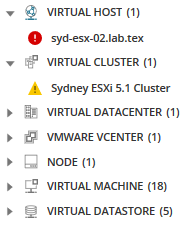
-
Wählen Sie den Syd-Hostknoten aus, um ihn anzuzeigen, und wählen Sie Metriken aus, die Sie per Drag & Drop auf das Dashboard ziehen möchten. Sie können sie in dasselbe Diagramm ziehen, um Werte zwischen Metriken zu vergleichen.
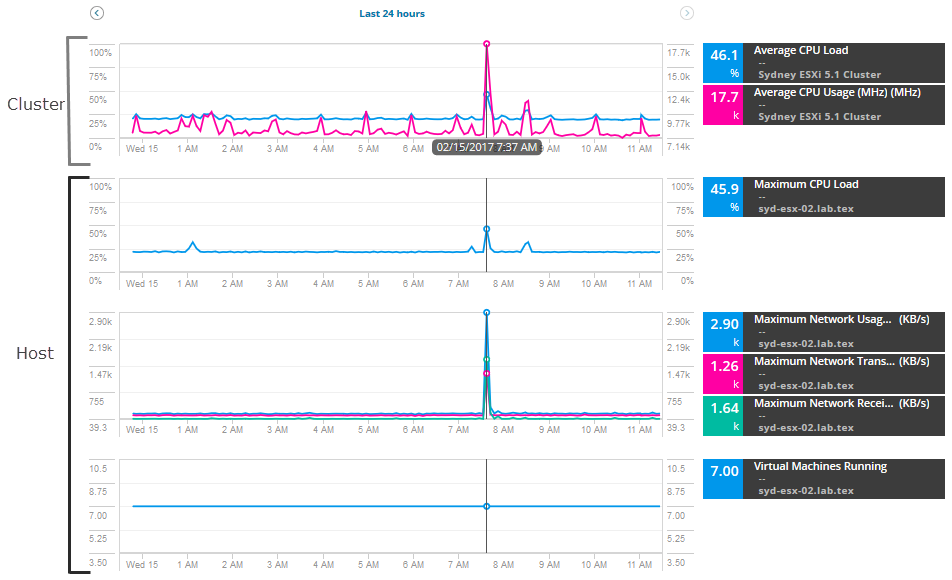
Um mit der Untersuchung zu beginnen, ziehen Sie eine Reihe von Metriken für den Host und den Cluster und vergleichen Sie Metriken, um Spitzenwerte oder eine hohe Auslastung zu ermitteln. Fügen Sie für dieses Szenario diese Hostmetriken hinzu:
- Maximale Netzwerkauslastung
- Maximale Netzwerkübertragungsrate
- Maximale Netzwerkempfangsrate
- Laufende virtuelle Maschinen
Fügen Sie für den Cluster die folgenden Metriken hinzu:
- Durchschnittliche CPU-Auslastung
- Durchschnittliche CPU-Auslastung
Die Diagramme und Grafiken werden mit Daten und Warnungen für die letzten 12 Stunden der Metriken angezeigt. Sie können das Datum und die Uhrzeit erweitern, um zusätzliche historische Metriken im Verlauf der Warnung anzuzeigen.
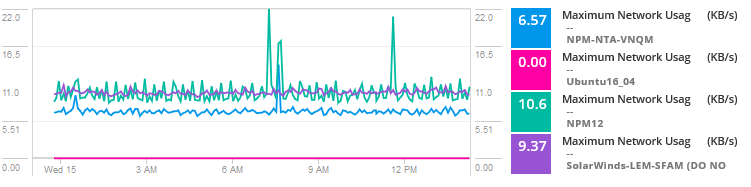
Fügen Sie Nutzungsmetriken für VMs auf dem Host hinzu, um die Netzwerknutzung und -aktivität zu vergleichen.
-
Bei der Analyse der Daten scheint das Problem ein verrauschter Nachbar für eine der virtuellen Maschinen zu sein, die Ressourcen verbrauchen und hohen Datenverkehr aufweisen, was zu Engpässen und Problemen für VMs führt, die den Host gemeinsam nutzen. Grundsätzlich verbraucht ein anderer Server, Dienst oder eine andere Anwendung eine höhere Bandbreite, Festplatten-E / A, CPU und andere Ressourcen, die Probleme für diese spezielle Anwendung verursachen.
Diese Informationen geben Ihren Netzwerk- und Systemadministratoren eine Anleitung zur weiteren Untersuchung und Lösung von Latenzproblemen. Zur Lösung können sie Ressourcen neu zuweisen oder die Anwendung mit hohem Verbrauch an einen anderen Speicherort verschieben.
-
Klicken Sie auf Speichern und geben Sie dem Projekt einen Namen.
Das Projekt wird als Dashboard mit den ausgewählten Metriken im festgelegten Datums- und Zeitbereich gespeichert.
Beim Speichern wird die URL zu einem gemeinsam nutzbaren Link. Kopieren und teilen Sie den Link zum gespeicherten Dashboard in Tickets oder E-Mails, die von den System- und Netzwerkadministratoren und dem Product Owner gesendet werden. Sie können auf den Link zugreifen, um die gesammelten Daten zu überprüfen und Fehler zu beheben.
Nachdem Sie Ressourcen neu zugewiesen und Netzwerkänderungen vorgenommen haben, öffnen Sie das Dashboard erneut, um Änderungen und neue Nutzungstrends für abgefragte Metriken zu überprüfen.