Seien wir schmerzlich ehrlich, wenn Ihr Unternehmen nicht im Internet vertreten ist, ist es für die Welt nicht existent. Wenn Sie keine Website haben, verlieren Sie außerdem die Gelegenheit, mehr hochwertige Leads anzuziehen. Jedes Unternehmen, von einem Unternehmensriesen wie Amazon bis zu einem Ein-Personen-Unternehmen, strebt eine Website und Inhalte an, die sein Publikum ansprechen. Sie und Ihr Unternehmen online zu entdecken, hört hier nicht auf. Hinter Websites verbirgt sich eine ganze „für das menschliche Auge unsichtbare“ Welt, in der Webcrawler eine wichtige Rolle spielen.
Inhalt
- Was ist ein Webcrawler und Indexierung?
- Wie funktioniert eine Websuche?
- Wie funktioniert ein Webcrawler?
- Was sind die wichtigsten Webcrawler-Typen?
- Was sind Beispiele für Webcrawler?
- Was ist ein Googlebot?
- Web Crawler vs Web Scraper – Was ist der Unterschied?
- Benutzerdefinierter Webcrawler – Was ist das?
- Einpacken
Was ist ein Webcrawler und Indizierung?
Beginnen wir mit einer Webcrawler-Definition:
Ein Webcrawler (auch bekannt als Web Spider, Spider Bot, Web Bot oder einfach Crawler) ist ein Computersoftwareprogramm, das von einer Suchmaschine verwendet wird, um Webseiten und Inhalte im gesamten World Wide Web zu indizieren.
Die Indizierung ist ein wesentlicher Prozess, da Benutzer relevante Abfragen innerhalb von Sekunden finden können. Die Suchindizierung kann mit der Buchindizierung verglichen werden. Wenn Sie beispielsweise die letzten Seiten eines Lehrbuchs öffnen, finden Sie einen Index mit einer Liste von Abfragen in alphabetischer Reihenfolge und Seiten, auf denen sie im Lehrbuch erwähnt werden. Das gleiche Prinzip unterstreicht den Suchindex, aber anstelle der Seitennummerierung zeigt Ihnen eine Suchmaschine einige Links, über die Sie nach Antworten auf Ihre Anfrage suchen können.
Der wesentliche Unterschied zwischen den Such- und Buchindizes besteht darin, dass der erstere dynamisch ist und daher geändert werden kann und der letztere immer statisch ist.
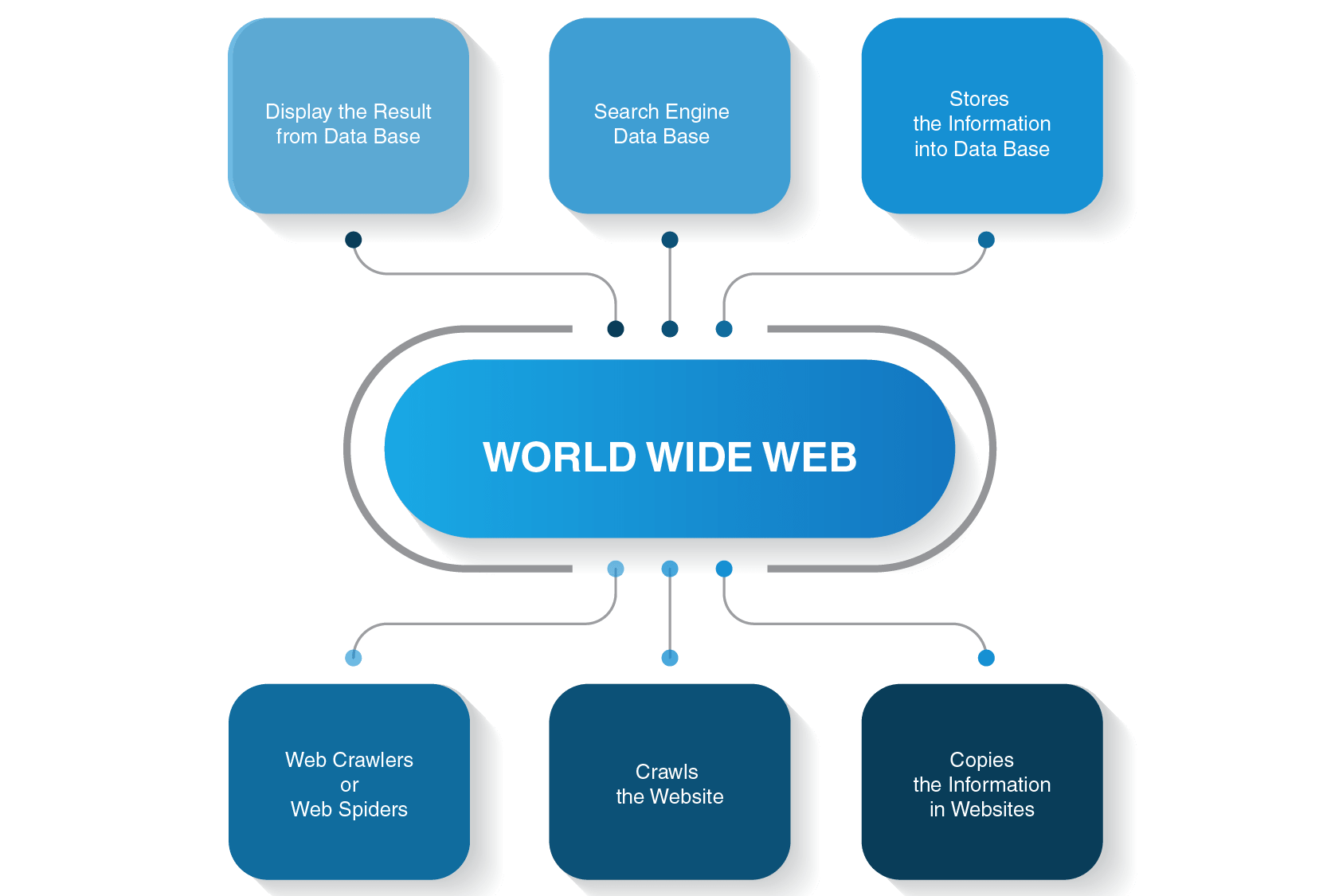
Wie funktioniert eine Websuche?
Bevor wir uns mit den Details der Funktionsweise eines Raupenroboters befassen, sollten wir uns ansehen, wie der gesamte Suchvorgang ausgeführt wird, bevor Sie eine Antwort auf Ihre Suchanfrage erhalten.
Wenn Sie beispielsweise „Was ist die Entfernung zwischen Erde und Mond“ eingeben und die Eingabetaste drücken, zeigt Ihnen eine Suchmaschine eine Liste relevanter Seiten. In der Regel sind drei Hauptschritte erforderlich, um Benutzern die erforderlichen Informationen für ihre Suche bereitzustellen:
- Eine Webspinne crawlt Inhalte auf Websites
- Es erstellt einen Index für eine Suchmaschine
- Suchalgorithmen ordnen die relevantesten Seiten
Außerdem muss man zwei wesentliche Punkte beachten:
- Sie suchen nicht in Echtzeit, da dies unmöglich ist
Es gibt viele Websites im World Wide Web, und viele weitere werden bereits jetzt erstellt, wenn Sie diesen Artikel lesen. Aus diesem Grund kann es Äonen dauern, bis eine Suchmaschine eine Liste von Seiten erstellt, die für Ihre Anfrage relevant sind. Um den Suchvorgang zu beschleunigen, crawlt eine Suchmaschine die Seiten, bevor sie sie der Welt zeigt.
- Sie suchen nicht im World Wide Web
Tatsächlich suchen Sie nicht im World Wide Web, sondern in einem Suchindex, und dann betritt ein Webcrawler das Schlachtfeld.
Kontaktieren Sie uns jetzt!
Wie funktioniert ein Webcrawler?
Es gibt viele Suchmaschinen – Google, Bing, Yahoo!, DuckDuckGo, Baidu, Yandex und viele andere. Jeder von ihnen verwendet seinen Spider-Bot, um Seiten zu indizieren.
Sie starten ihren Crawling-Prozess von den beliebtesten Websites. Ihr Hauptzweck von Web-Bots besteht darin, den Kern dessen zu vermitteln, worum es bei den einzelnen Seiteninhalten geht. Daher suchen Webspinnen auf diesen Seiten nach Wörtern und erstellen dann eine praktische Liste dieser Wörter, die beim nächsten Mal von einer Suchmaschine verwendet werden, wenn Sie Informationen zu Ihrer Abfrage suchen.
Alle Seiten im Internet sind durch Hyperlinks verbunden, sodass Site-Spider diese Links entdecken und ihnen zu den nächsten Seiten folgen können. Web-Bots stoppen nur, wenn sie alle Inhalte und verbundenen Websites finden. Dann senden sie die aufgezeichneten Informationen einen Suchindex, der auf Servern rund um den Globus gespeichert ist. Der ganze Prozess ähnelt einem echten Spinnennetz, in dem alles miteinander verflochten ist.
Das Crawlen stoppt nicht sofort, sobald Seiten indiziert wurden. Suchmaschinen verwenden regelmäßig Webspinnen, um festzustellen, ob Änderungen an Seiten vorgenommen wurden. Bei einer Änderung wird der Index einer Suchmaschine entsprechend aktualisiert.
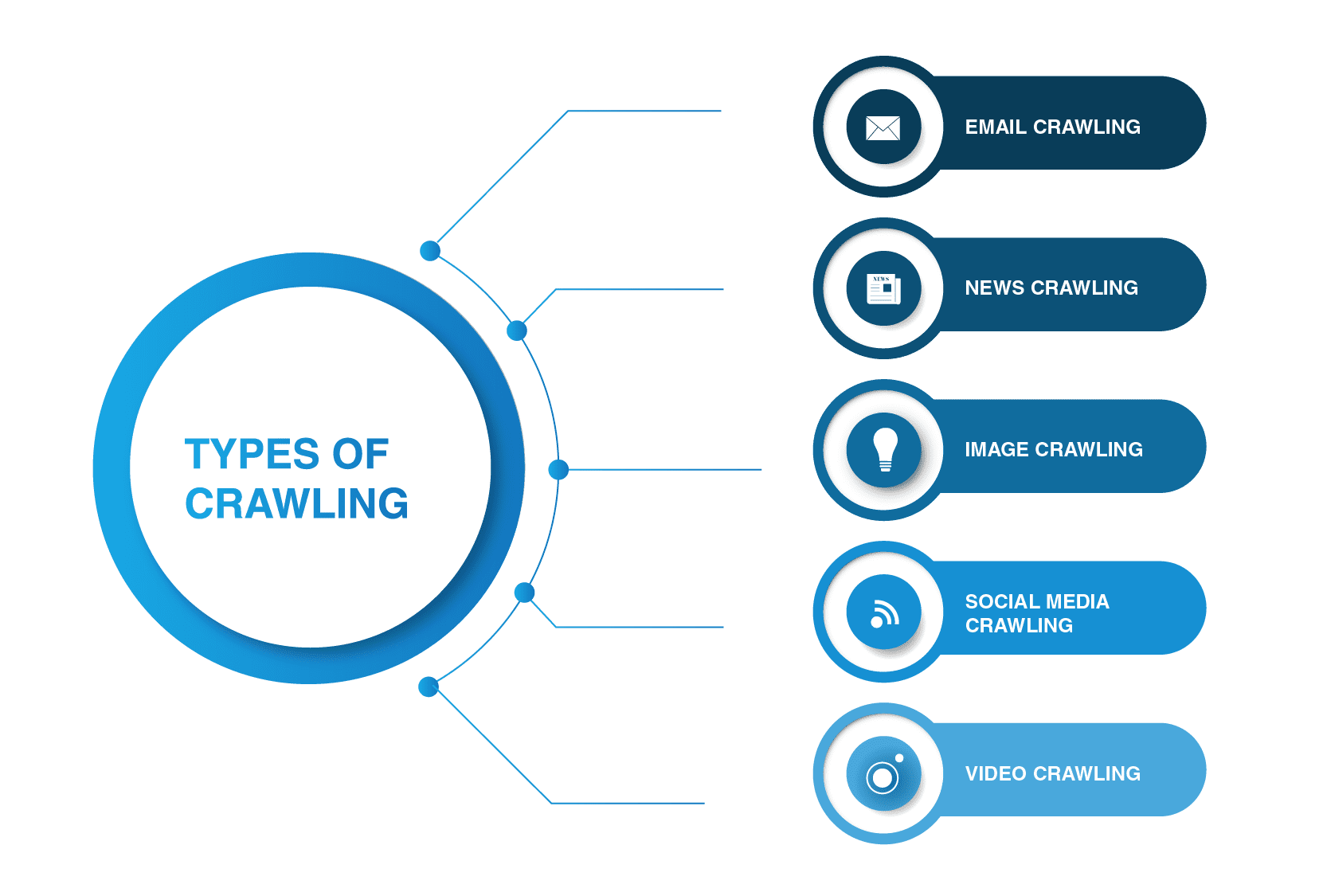
Was sind die wichtigsten Webcrawler-Typen?
Webcrawler sind nicht auf Suchmaschinen-Spider beschränkt. Es gibt andere Arten von Webcrawling.
- E-Mail-Crawling
E-Mail-Crawling ist besonders nützlich bei der Generierung ausgehender Leads, da diese Art des Crawlings beim Extrahieren von E-Mail-Adressen hilft. Es ist erwähnenswert, dass diese Art des Crawlens illegal ist, da sie die Privatsphäre verletzt und nicht ohne Benutzerberechtigung verwendet werden kann.
- News Crawling
Mit dem Aufkommen des Internets können Nachrichten aus der ganzen Welt schnell im Internet verbreitet werden, und das Extrahieren von Daten von verschiedenen Websites kann ziemlich unüberschaubar sein.
Es gibt viele Webcrawler, die diese Aufgabe bewältigen können. Solche Crawler können Daten aus neuen, alten und archivierten Nachrichteninhalten abrufen und RSS-Feeds lesen. Sie extrahieren die folgenden Informationen: veröffentlichungsdatum, Name des Autors, Überschriften, Leitsätze, Haupttext und Veröffentlichungssprache.
- Bildcrawling
Wie der Name schon sagt, wird diese Art des Crawlings auf Bilder angewendet. Das Internet ist voll von visuellen Darstellungen. So helfen solche Bots Menschen, relevante Bilder in einer Vielzahl von Bildern im Web zu finden.
- Social-Media-Crawling
Social-Media-Crawling ist eine interessante Angelegenheit, da nicht alle Social-Media-Plattformen gecrawlt werden können. Sie sollten auch bedenken, dass eine solche Art von Crawling illegal sein kann, wenn sie gegen die Einhaltung des Datenschutzes verstößt. Dennoch gibt es viele Anbieter von Social-Media-Plattformen, die mit dem Crawlen einverstanden sind. Zum Beispiel erlauben Pinterest und Twitter Spider-Bots, ihre Seiten zu scannen, wenn sie nicht benutzersensibel sind und keine persönlichen Informationen preisgeben. Facebook, LinkedIn sind in dieser Angelegenheit streng.
- Video Crawling
Manchmal ist es viel einfacher, ein Video anzusehen, als viele Inhalte zu lesen. Wenn Sie sich entscheiden, Youtube, Soundcloud, Vimeo oder andere Videoinhalte in Ihre Website einzubetten, können diese von einigen Webcrawlern indiziert werden.
Was sind Beispiele für Webcrawler?
Viele Suchmaschinen verwenden ihre eigenen Such-Bots. Zum Beispiel sind die häufigsten Webcrawler Beispiele:
- Alexabot
Amazon Web Crawler Alexabot wird zur Identifizierung von Webinhalten und zur Erkennung von Backlinks verwendet. Wenn Sie einige Ihrer Informationen privat halten möchten, können Sie Alexabot vom Crawlen Ihrer Website ausschließen.3643 7383 1191Yahoo! Schlürfen Bot
Yahoo Crawler Yahoo! Slurp Bot wird zum Indizieren und Scraping von Webseiten verwendet, um personalisierte Inhalte für Benutzer zu verbessern.
- Bingbot
Bingbot ist einer der beliebtesten Webspinnen von Microsoft. Es hilft einer Suchmaschine, Bing, den relevantesten Index für seine Benutzer zu erstellen.
- DuckDuckGo
DuckDuckGo ist wahrscheinlich eine der beliebtesten Suchmaschinen, die Ihren Verlauf nicht verfolgt und Ihnen auf den von Ihnen besuchten Websites folgt. Der DuckDuck Bot-Webcrawler hilft dabei, die relevantesten und besten Ergebnisse zu finden, die die Bedürfnisse eines Benutzers erfüllen.
- Facebook Externer Treffer
Facebook hat auch seinen Crawler. Wenn ein Facebook-Nutzer beispielsweise einen Link zu einer externen Inhaltsseite mit einer anderen Person teilen möchte, kratzt der Crawler den HTML-Code der Seite und versieht beide mit dem Titel, einem Tag des Videos oder Bildern des Inhalts.
- Baiduspider
Dieser Crawler wird von der dominierenden chinesischen Suchmaschine Baidu betrieben. Wie jeder andere Bot durchläuft er eine Vielzahl von Webseiten und sucht nach Hyperlinks, um Inhalte für die Engine zu indizieren.
- Exabot
Die französische Suchmaschine Exalead verwendet Exabot zur Indexierung von Inhalten, damit diese in den Index der Suchmaschine aufgenommen werden können.
- Yandex Bot
Dieser Bot gehört zur größten russischen Suchmaschine Yandex. Sie können die Indizierung Ihrer Inhalte blockieren, wenn Sie dort keine Geschäfte tätigen möchten.
Was ist ein Googlebot?
Wie oben erwähnt, haben fast alle Suchmaschinen ihre Spider-Bots, und Google ist keine Ausnahme. Googlebot ist ein Google-Crawler, der von der beliebtesten Suchmaschine der Welt betrieben wird und zum Indizieren von Inhalten für diese Engine verwendet wird.
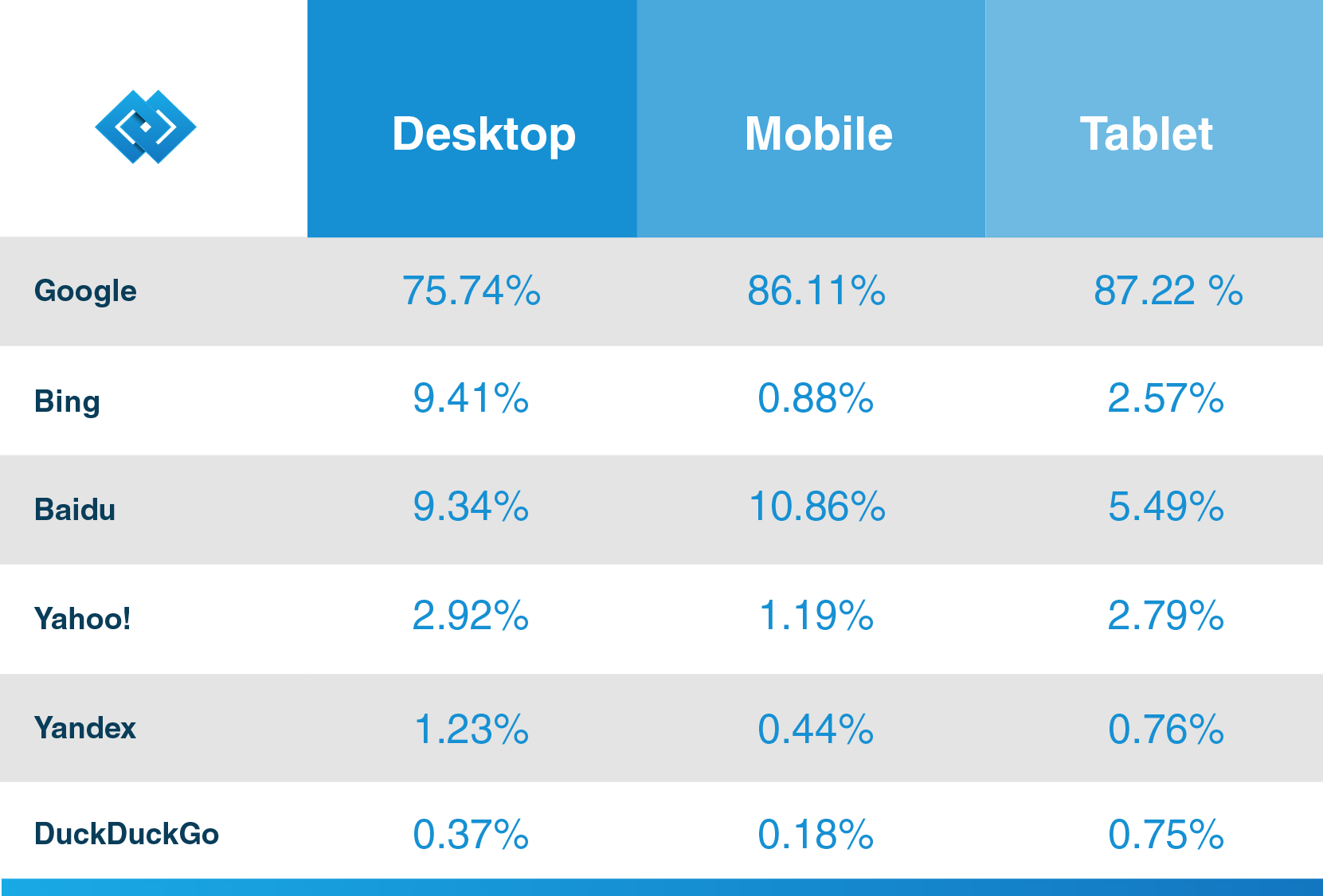
Wie Hubspot, ein renommierter CRM-Anbieter, in seinem Blog feststellt, hat Google mehr als 92.42% des Suchmarktanteils und der mobile Traffic liegt bei über 86%. Wenn Sie also das Beste aus der Suchmaschine für Ihr Unternehmen herausholen möchten, informieren Sie sich über deren Web Spider, damit Ihre zukünftigen Kunden Ihre Inhalte dank Google entdecken können.
Googlebot kann von zwei Arten sein – ein Desktop-Bot und eine mobile App Crawler, die den Benutzer auf diesen Geräten simulieren. Es verwendet das gleiche Crawling-Prinzip wie jeder andere Web-Spider, z. B. das Folgen von Links und das Scannen von Inhalten, die auf Websites verfügbar sind. Der Prozess ist auch voll automatisiert und kann wiederkehrend sein, was bedeutet, dass es die gleiche Seite mehrmals in unregelmäßigen Abständen besuchen kann.
Wenn Sie bereit sind, Inhalte zu veröffentlichen, dauert es Tage, bis der Google-Crawler sie indiziert. Wenn Sie der Eigentümer der Website sind, können Sie den Vorgang manuell beschleunigen, indem Sie eine Indexierungsanfrage über Fetch as Google senden oder die Sitemap Ihrer Website aktualisieren.
Sie können auch Roboter verwenden.txt (oder das Robots Exclusion Protocol) zum „Geben von Anweisungen“ an einen Spider-Bot, einschließlich Googlebot. Dort können Sie Crawlern erlauben oder verbieten, bestimmte Seiten Ihrer Website zu besuchen. Beachten Sie jedoch, dass auf diese Datei problemlos von Dritten zugegriffen werden kann. Sie sehen, welche Teile der Website Sie von der Indizierung ausgeschlossen haben.
Web Crawler vs Web Scraper – Was ist der Unterschied?
Viele Leute verwenden Webcrawler und Web Scraper austauschbar. Dennoch gibt es einen wesentlichen Unterschied zwischen diesen beiden. Wenn sich Ersteres hauptsächlich mit Metadaten von Inhalten wie Tags, Überschriften, Schlüsselwörtern und anderen Dingen befasst, „stiehlt“ ersteres Inhalte von einer Website, die auf der Online-Ressource einer anderen Person veröffentlicht werden sollen.
Ein Web Scraper „jagt“ auch nach bestimmten Daten. Wenn Sie beispielsweise Informationen von einer Website extrahieren müssen, auf der Informationen wie Börsentrends, Bitcoin-Preise oder andere Informationen vorhanden sind, können Sie Daten von diesen Websites mithilfe eines Web-Scraping-Bots abrufen.
Wenn Sie Ihre Website crawlen und Ihre Inhalte zur Indizierung einreichen möchten oder die Absicht haben, dass andere Personen sie finden, ist dies völlig legal, andernfalls verstößt das Scraping von Websites anderer Personen und Unternehmen gegen das Gesetz.
Benutzerdefinierter Webcrawler – Was ist das?
Ein benutzerdefinierter Webcrawler ist ein Bot, der verwendet wird, um einen bestimmten Bedarf zu decken. Sie können Ihren Spider-Bot erstellen, um jede Aufgabe abzudecken, die gelöst werden muss. Wenn Sie beispielsweise Unternehmer, Vermarkter oder ein anderer Fachmann sind, der sich mit Inhalten befasst, können Sie es Ihren Kunden und Benutzern erleichtern, die gewünschten Informationen auf Ihrer Website zu finden. Sie können eine Vielzahl von Web-Bots für verschiedene Zwecke erstellen.
Wenn Sie keine praktische Erfahrung mit der Erstellung Ihres benutzerdefinierten Webcrawlers haben, können Sie sich jederzeit an einen Softwareentwicklungsdienstleister wenden, der Ihnen dabei helfen kann.
Einwickeln
Website-Crawler sind ein wesentlicher Bestandteil jeder großen Suchmaschine, die zum Indizieren und Entdecken von Inhalten verwendet wird. Viele Suchmaschinenunternehmen haben ihre Bots, zum Beispiel wird Googlebot vom Unternehmensriesen Google betrieben. Abgesehen davon gibt es mehrere Arten von Crawling, die verwendet werden, um spezifische Bedürfnisse abzudecken, wie Video-, Bild- oder Social-Media-Crawling.
Wenn man bedenkt, was Spider Bots können, sind sie sehr wichtig und vorteilhaft für Ihr Unternehmen, da Webcrawler Sie und Ihr Unternehmen der Welt offenbaren und neue Benutzer und Kunden gewinnen können.
Wenn Sie einen benutzerdefinierten Webcrawler erstellen möchten, wenden Sie sich an LITSLINK, einen erfahrenen Anbieter von Webentwicklungsdiensten, um weitere Informationen zu erhalten.