dit artikel werd gepubliceerd als onderdeel van de Data Science Blogathon.
“de grootste religie ter wereld is niet eens een religie.”- Fernando Torres
Inleiding
voetbal is geliefd bij iedereen en zijn schoonheid ligt in zijn onvoorspelbare aard. Een ding dat sterk wordt geassocieerd met dit spel is de fans, broeden en debatteren voor een spel over wie het spel zal winnen. En sommige fans gaan zelfs tot de limiet van het speculeren van de score voor de wedstrijd. Laten we proberen een aantal van deze vragen logisch te beantwoorden.
Poisson leren kennen
zoals ik al eerder heb gezegd is voetbal een onvoorspelbaar spel, een doel kan op elk moment in de wedstrijd volledig willekeurig optreden zonder afhankelijk te zijn van eerdere doelen of teams of andere factoren. Wacht, zei Ik “willekeurig”. Omdat er een verdeling in de statistieken die wordt gebruikt voor het vinden van de waarschijnlijkheid van willekeurig voorkomende gebeurtenissen, Poisson distributie.
stel dat je vriend zegt dat er gemiddeld 2 goals per spel gebeuren, nou, heeft hij gelijk? Als rechts dan wat zijn de werkelijke kansen op het zien van twee doelpunten in een wedstrijd? Hier komt onze redding Poisson distributie helpt ons om de waarschijnlijkheid van het observeren van ‘n’ gebeurtenissen (lees ‘n’ doelen) in een vaste periode gezien het feit dat we het voorzien van de verwachting van gebeurtenissen die plaatsvinden (gemiddelde gebeurtenissen per periode) te vinden. Laten we eens wiskundig kijken.
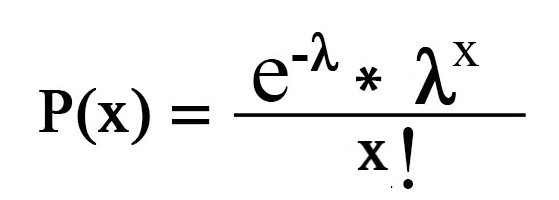
(waar λ = gemiddelde gebeurtenissen per periode)
kans op Scoren
laten we nu enkele vragen beantwoorden met deze vergelijking, maar eerst hebben we gegevens nodig, dus hiervoor heb ik de internationale voetbalresultaten van 1872 tot 2020 Data gedownload van Kaggle. Een voorbeeld van onze dataset wordt hieronder weergegeven.
code:
data.head(3)
.png)
laten we beginnen met het vinden van de gemiddelde doelen die we binnen 90 minuten kunnen verwachten.
hiervoor heb ik een aparte dataset gemaakt die gegevens filtert voor wedstrijden die gespeeld worden in de 21e eeuw(2000-2020) en de home_score en away_score toegevoegd om het totaal aantal te achterhalen. van doelen die zich voordoen in elke wedstrijd en vervolgens genomen het gemiddelde van de totale doelen kolom om de gemiddelde doelen die we kunnen verwachten in een wedstrijd te krijgen.
code:
data=data+datadata=data.apply(lambda x : int(str.split(x,'-')))rec_data=data.loc>=2000)]rec_data.iloc]print(rec_data.total_goals.mean())
2.744112130054189
nu zetten deze verwachting in Poissson distributie formule laten we eens kijken wat zijn de werkelijke kans op het zien van 3 doelen in een wedstrijd.
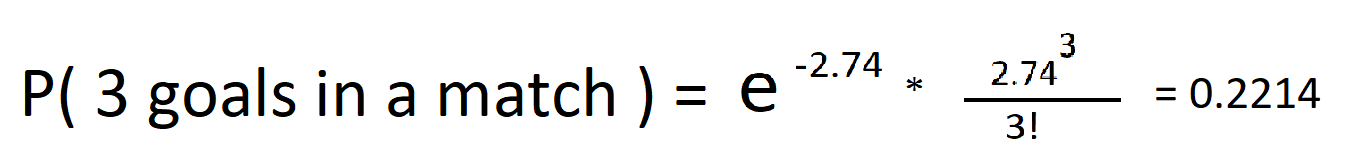
slechts 22% kans. Laten we de kansen van de nee plotten. van doelen in een wedstrijd om een beter beeld te krijgen.
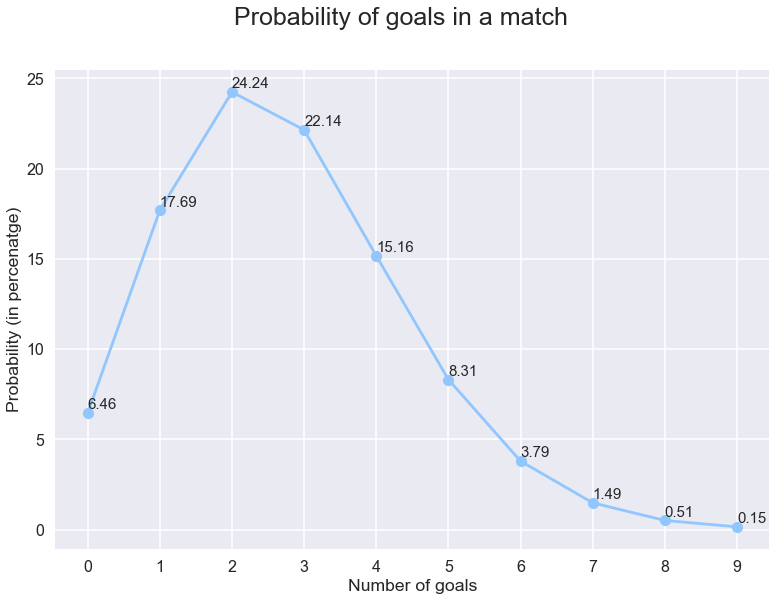
hieruit kunnen we de kans berekenen om ‘x ‘of minder aantal doelen te zien door simpelweg de waarschijnlijkheden van ‘x’ en de getallen toe te voegen die kleiner zijn dan ‘x’.En door dit gewoon af te trekken van 1 kunnen we de kans krijgen om meer dan ‘X’ doelen te zien in een wedstrijd. Laten we dit ook plotten.
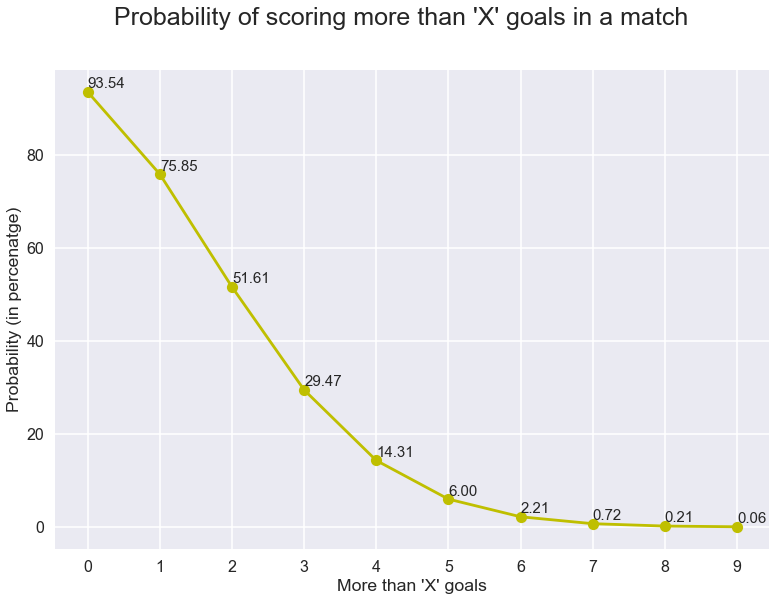
het wachten is voorbij…
stel nu dat je een ongeduldige vriend hebt die niet het hele spel wil zitten. En hij komt naar je toe tijdens een wedstrijd en vraagt hoeveel tijd hij moet wachten om een doel te zien. Woah, dat is een moeilijke vraag rechts, maar maak je geen zorgen, vraag hem om te zitten door 10000 wedstrijden en noteer de tijd tussen elk doel. Grapje, hij zou uit zijn dak gaan. Eigenlijk simuleerde ik 10000 wedstrijden en ontdekte de gemiddelde tijd.
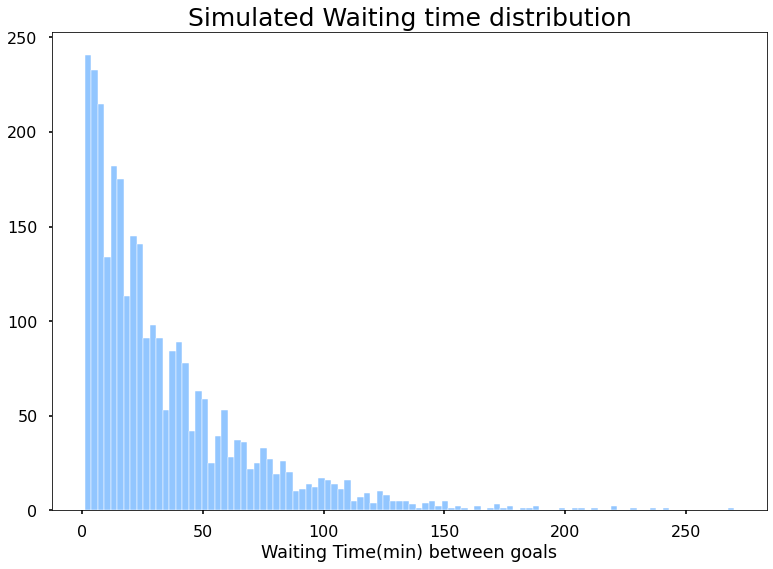
de meest waarschijnlijke wachttijd is 2 minuten. Maar wacht dit niet echt wat ik zocht, ik wil de gemiddelde tijd dat ik moet wachten om een doel te zien als ik begin te kijken naar het spel op een willekeurig moment. Voor dat, Ik zal nemen 10000 gevallen, waar elke instantie is het kijken naar 10000 games en het berekenen van de gemiddelde wachttijd tussen doelen in die 10000 games en het rapporteren van ons. Tot slot, Ik zal het plotten van die 10000 rapporten van elk van mijn instanties en ontdek de verwachte gemiddelde wachttijd.
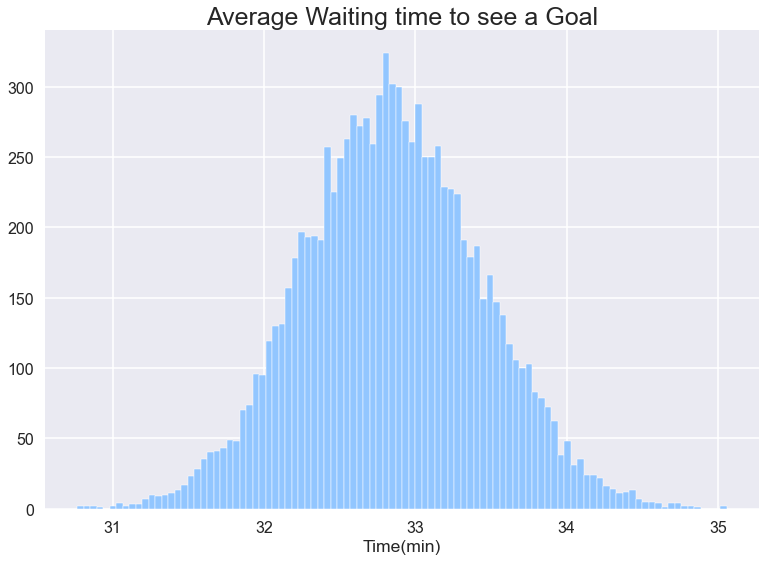
het lijkt erop dat we ongeveer 33 minuten moeten wachten. Hoe we ook moeten wachten op meer, Dit is een klassieke wachttijd Paradox.
het voorspellen van de score
ten slotte, laten we de vraag waarmee we begonnen en de meest opwindende vraag dat wie zal winnen en wat zal de score om precies te zijn.
hiervoor zal ik de geschiedenis tussen twee teams gebruiken (laat ze beschouwen als het thuis team en het uit team) en neem de average_home_score als de verwachte doelen voor het thuis team en average_away_score als de verwachte doelen voor het uit team en voorspel de score met behulp van Poisson distributie. In het geval dat de teams minder ontmoetingen tussen hen hebben, zullen we rekening houden met een paar factoren
HS = gemiddelde van thuisdoelpunten gescoord door het thuisteam door de geschiedenis heen.
AS = gemiddelde uitdoelpunten door de hele geschiedenis.
HC = gemiddelde van doelpunten in thuiswedstrijden door de thuisploeg.
AC = gemiddelde van doelpunten in uitwedstrijden door het uitteam.
So, de verwachte score van het thuisteam wordt berekend als (HS + AC) / 2
So, de verwachte score van het expeditieteam wordt berekend als (AS + HC) / 2
wacht, de verwachte score is niet de voorspelde score. De verwachte score is het gemiddelde aantal doelpunten dat we verwachten dat ze scoren in een wedstrijd tussen hen.
code:
import pandas as pdimport numpy as npfrom scipy import stats
def PredictScore(): home_team = input("Enter Home Team: ") ht = (''.join(home_team.split())).lower() away_team = input("Enter Away Team: ") at = (''.join(away_team.split())).lower() if len(data) > 20: avg_home_score = data.home_score.mean() avg_away_score = data.away_score.mean() home_goal = int(stats.mode(np.random.poisson(avg_home_score,100000))) away_goal = int(stats.mode(np.random.poisson(avg_away_score,100000))) else: avg_home_goal_conceded = data.away_score.mean() avg_away_goal_scored = data.away_score.mean() away_goal = int(stats.mode(np.random.poisson(1/2*(avg_home_goal_conceded+avg_away_goal_scored),100000))) avg_away_goal_conceded = data.home_score.mean() avg_home_goal_scored = data.home_score.mean() home_goal = int(stats.mode(np.random.poisson(1/2*(avg_away_goal_conceded+avg_home_goal_scored),100000))) avg_total_score = int(stats.mode( np.random.poisson((data.total_goals.mean()),100000))) print(f'Expected total goals are {avg_total_score}') print(f'They have played {len(data)} matches') print(f'The scoreline is {home_team} {home_goal}:{away_goal} {away_team}')
laten we het proberen met Brazilië als thuisteam en Mexico als expeditieteam.
code:
PredictScore()
.png)
Poisson Distribution voorspelt dat Brazilië met een 2-0 score wint. Ik zocht het net en vond dat de laatste wedstrijd tussen hen werd gespeeld op 2 Jul 2018 en de score zegt Brazilië won met 2-0. Nou, ik had geluk, jij misschien niet.
conclusie
als u verder wilt verkennen geen zorgen, hier is mijn code. Verder is dit slechts een eenvoudige manier om het spel te voorspellen, tegenwoordig worden classificatiealgoritmen gebruikt om de uitkomst te voorspellen en regressiealgoritme om de score te voorspellen. Maar dat is het onderwerp voor een andere dag, tot dan veel plezier spelen met dit. Adios!