in dit artikel geschreven door een verkoper van een beveiligingsmonitoringoplossing was het belangrijkste argument (vaak weerklinkt in andere publicaties en verschillende beurzen) dat het patchen van OT-systemen moeilijk is. De auteur stelt dat, aangezien het moeilijk is, we moeten wenden tot andere methoden om de veiligheid te verbeteren. Zijn theorie is om een waarschuwingstechnologie als de zijne aan te zetten en de lopende alarmen te koppelen aan een security incident response team. Met andere woorden, gewoon accepteren patchen is moeilijk, opgeven, en giet meer geld in het leren eerder (misschien?) en krachtiger reageren.
echter, deze conclusie (patchen is moeilijk dus doe geen moeite) is defect om een paar redenen. Niet te vergeten, hij verdoezelt ook een zeer grote factor die aanzienlijk compliceert elke reactie of sanering die moet worden overwogen.
de eerste reden dat dit een gevaarlijk advies is, is dat je patching gewoon niet kunt negeren. Je moet doen wat je kunt, wanneer je kunt, en als patchen geen optie is, ga je naar plan B, C en D. Niets doen betekent dat alle cyber-gerelateerde incidenten die hun weg in uw omgeving zal produceren maximale schade. Dit klinkt als de M&m verdediging van 20 jaar geleden. Dit is het idee dat uw beveiligingsoplossing hard en knapperig moet zijn aan de buitenkant, maar zacht en taai aan de binnenkant.
de tweede reden dat dit advies onjuist is, is de veronderstelling dat OT-beveiligingspersoneel (voor incident response of patching) gemakkelijk te vinden en in te zetten zijn! Dit is niet waar-in feite wijst een van de ICS-beveiligingsincidenten waarnaar in het artikel wordt verwezen erop dat terwijl een patch beschikbaar was en klaar voor installatie, er geen ICS-experts beschikbaar waren om toezicht te houden op de patch-installatie! Als we onze beveiligingsexperts niet kunnen vrijstellen om bekende, pre-event bescherming in te zetten als onderdeel van een proactief patch management programma, waarom denken we dan dat we het budget kunnen vinden voor een volledig incident response team na de feiten als het te laat is?
ten slotte is het ontbrekende stuk van dit argument dat de uitdagingen voor OT/ICS-patchbeheer verder worden verergerd door de hoeveelheid en complexiteit van activa en architectuur in een OT-netwerk. Om duidelijk te zijn, wanneer een nieuwe patch of kwetsbaarheid wordt vrijgegeven, is het vermogen van de meeste organisaties om te begrijpen hoeveel activa in omvang zijn en waar ze zich bevinden een uitdaging. Maar hetzelfde niveau van inzicht en asset profielen zal nodig zijn van elk incident response team om effectief te zijn. Zelfs zijn advies om de praktijk van het patchen te negeren kan je niet laten voorkomen dat je een robuuste, contextuele inventaris moet bouwen (de basis voor het patchen!) als een basis van uw OT cyber security programma.
dus, wat moeten we doen? Eerst en vooral moeten we proberen te patchen. Er zijn drie dingen die een volwassen ICS patch management programma moet bevatten om succesvol te zijn:
- real-time, contextuele inventaris
- automatisering van herstel (zowel patchbestanden als ad-hocbeveiliging)
- identificatie en toepassing van compenserende controles
real-time contextuele inventaris voor patchbeheer
de meeste OT-omgevingen gebruiken scangebaseerde patchingtools zoals WSUS/SCCM, die vrij standaard zijn, maar niet te veel inzicht hebben om ons te laten zien welke activa we hebben en hoe ze zijn geconfigureerd. Wat echt nodig is, zijn robuuste assetprofielen met hun operationele context. Wat bedoel ik hiermee? Asset IP, model, OS, enz. is een zeer vluchtige lijst van wat in het kader van de nieuwste patch zou kunnen zijn. Wat waardevoller is, is de operationele context, zoals de kritische waarde van activa voor veilige operaties, de locatie van activa, de eigenaar van activa, enz. om ons opkomende risico goed te contextualiseren omdat niet alle OT-activa gelijk worden gecreëerd. Dus waarom niet eerst de kritische systemen beschermen of geschikte testsystemen identificeren (die kritische veldsystemen weerspiegelen) en strategisch risico ‘ s verminderen?
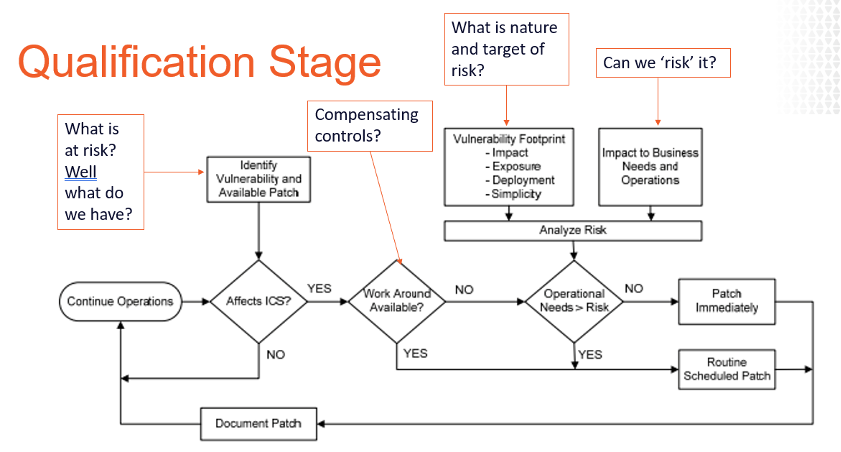
en terwijl we deze assetprofielen bouwen, moeten we zoveel mogelijk informatie over de assets bevatten naast IP, Mac-adres en OS-versie. Informatie zoals geïnstalleerde software, gebruikers / account, poorten, diensten, registerinstellingen, minst privilege controles, AV, whitelisting en back-up status etc. Deze soorten informatiebronnen vergroten ons vermogen om nauwkeurig prioriteiten te stellen en onze acties te strategiseren wanneer er nieuwe risico ‘ s ontstaan. Wil je bewijs? Neem een kijkje op de gebruikelijke analyse stroom hieronder aangeboden. Waar haal je de gegevens vandaan om de vragen in de verschillende stadia te beantwoorden? Stamkennis? Instinct? Waarom geen data?
automatiseer herstel voor softwarepatching
een andere uitdaging voor softwarepatching is het implementeren en voorbereiden van patches (of compenserende controles) naar de eindpunten. Een van de meest tijdrovende taken in OT patch management is het prep werk. Het omvat meestal het identificeren van doelsystemen, het configureren van de patch implementatie, het oplossen van problemen wanneer ze falen of eerst scannen, duwen van de patch, en opnieuw scannen om succes te bepalen.
maar wat als, bijvoorbeeld, de volgende keer dat een risico als BlueKeep verscheen, u uw bestanden op de doelsystemen kon vooraf laden om uzelf voor te bereiden op de volgende stappen? U en uw kleinere, meer wendbare OT security team kon strategisch plannen welke industriële systemen je gerold patch updates naar de eerste, tweede en derde op basis van een aantal factoren in uw robuuste asset profielen zoals asset locatie of criticaliteit.
een stap verder, Stel je voor dat de patch management technologie niet eerst een scan nodig had, maar eerder de patch al had toegewezen aan in-scope assets en terwijl je ze installeerde (ofwel op afstand voor een laag risico of persoonlijk voor een hoog risico), deze taken hun succes verifieerden en die vooruitgang weerspiegelden in je wereldwijde dashboard?
voor al uw risicovolle activa die u nu niet kunt of wilt patchen, kunt u in plaats daarvan een port, service of gebruiker/account wijzigen als een ad-hoc compensatiecontrole. Dus voor een kwetsbaarheid zoals BlueKeep, kon je de remote desktop of de gast account uit te schakelen. Deze aanpak vermindert onmiddellijk en aanzienlijk het huidige risico en laat ook meer tijd toe om zich voor te bereiden op de uiteindelijke patch. Dit brengt me bij de ’terugval’ acties van wat te doen als patchen geen optie is – compenserende controles.
wat zijn compenserende controles?
compenserende controles zijn gewoon acties en beveiligingsinstellingen die u kunt en moet implementeren in plaats van (of liever gezegd ook) patching. Ze worden meestal proactief ingezet (waar mogelijk), maar kunnen worden ingezet in een gebeurtenis of als tijdelijke maatregelen van bescherming, zoals het uitschakelen van remote desktop terwijl u patch voor BlueKeep, die ik uit te breiden op in de case study aan het einde van deze blog.
identificatie en toepassing van compenserende controles in OT-beveiliging
compenserende controles nemen vele vormen aan van de whitelisting van de toepassing en het up-to-date houden van antivirus. Maar in dit geval wil ik me richten op ICS endpoint management als een belangrijk ondersteunend onderdeel van OT patch management.
compenserende controles kunnen en moeten zowel proactief als situationeel worden gebruikt. Het zou geen verrassing voor iedereen in OT cyber security te ontdekken slapende admin accounts en onnodige of ongebruikte software geà nstalleerd op endpoints. Het is ook geen geheim dat best practice system Harding principles lang niet zo universeel zijn als we zouden willen.
om onze OT-systemen echt te beschermen, moeten we ook onze waardevolle bezittingen verharden. Een realtime, robuust assetprofiel stelt industriële organisaties in staat om de laaghangende vruchten (d.w.z. slapende gebruikers, onnodige software en systeemhardingsparameters) nauwkeurig en efficiënt te verwijderen om het aanvalsoppervlak aanzienlijk te verminderen.
in het ongelukkige geval hebben we een opkomende dreiging (zoals BlueKeep) het toevoegen van tijdelijke compenserende controles is uitvoerbaar. Een snelle casestudy om mijn punt te benadrukken:
- bluekeep kwetsbaarheid wordt vrijgegeven.
- het centrale team schakelt remote desktop onmiddellijk uit op alle veldactiva en e-mails veldteam dat specifieke verzoeken op systeem-per-systeem basis nodig heeft om remote desktop service in te schakelen tijdens de risicoperiode.
- Centraal team laadt patchbestanden op alle in-scope activa-geen actie, gewoon voorbereiden.
- het centrale team komt bijeen om het meest redelijke plan van actie te bepalen op basis van de criticaliteit van de activa, de locatie, de aanwezigheid of het ontbreken van compenserende controles (d.w.z. een kritisch risico op een actief met een hoge impact dat zijn laatste back-up faalde, wordt bovenaan de lijst geplaatst. Een lage impact asset met whitelisting in effect en een recente goede volledige back-up kan waarschijnlijk wachten).
- de Patching-uitrol begint en de voortgang wordt live bijgewerkt in de wereldwijde rapportage.
- indien nodig zijn OT-technici aanwezig op de console die toezicht houden op de implementatie van de patch.
- het schema en de mededeling van deze behoefte worden volledig gepland en geprioriteerd door de gegevens die door het centrale team worden gebruikt.
dit is hoe OT patch management moet worden behandeld. Steeds meer organisaties beginnen dit soort programma ‘ s in te voeren.
Wees proactief met compenserende controles
ICS-patchbeheer is moeilijk, Ja, maar het gewoon opgeven van het proberen is ook geen goed antwoord. Met een beetje vooruitziende blik is het eenvoudig om de drie krachtigste tools te bieden voor eenvoudiger en effectiever patchen en/of compenserende controles. Insight laat zien wat je hebt, hoe het is geconfigureerd en hoe belangrijk het voor je is. Context laat je prioriteiten stellen (eerste poging om patch – second laat je weten hoe en waar compenserende controles toe te passen). De actie stelt u in staat om te corrigeren, te beschermen, af te buigen, enz. Alleen vertrouwen op monitoring is om toe te geven dat je brand verwacht en het kopen van meer rookmelders kan de schade minimaliseren. Welke aanpak denkt u dat uw organisatie verkiest?