In dit artikel bespreken we de eerste fase in compilerontwerp waarbij het invoerprogramma op hoog niveau wordt omgezet in een reeks tokens. Deze fase staat bekend als lexicale analyse in Compiler ontwerp.
inhoudsopgave:
- Definities voor Lexicale Analyse
- Een voorbeeld van Lexicale Analyse
- de Architectuur van lexical analyzer
- Regular Expressions
- Eindige Automaten
- de Relatie tussen reguliere expressies en eindige automaten
- Langste Match Regel
- Lexicale fouten
- Error recovery regelingen
- Moet voor lexicale analyzers
- Moet voor lexicale analyzers
Lexicale analyse is het proces van het omzetten van een reeks van tekens van een source-programma dat als invoer voor een reeks tokens.
een lexicale Analyzer is een programma dat lexicale analyzers genereert.
een lexicale analyzer / lexer / scanner is een programma dat lexicale analyse uitvoert.
de rollen van lexical analyzer impliceren;
- het lezen van invoerkarakters uit het bronprogramma.
- correlatie van foutmeldingen met het bronprogramma.
- witruimten en opmerkingen uit het bronprogramma strippen.
- Uitbreidingsmacro ‘ s indien gevonden in het bronprogramma.
- het invoeren van geïdentificeerde tokens in de symbolentabel.
Lexeme is een instantie van een token, dat wil zeggen een reeks tekens die in het bronprogramma zijn opgenomen volgens het overeenkomende patroon van een token.
een voorbeeld, gegeven de uitdrukking;
c = a + b * 5
de lexemen en tokens zijn;
| Lexemes | Penningen |
|---|---|
| c | id |
| = | opdracht symbool |
| een | id |
| + | +(naast symbool) |
| b | id |
| * | *(vermenigvuldiging symbool) |
| 5 | 5(aantal) |
De volgorde van de lopers geproduceerd door de lexical analyzer kan de parser voor het analyseren van de syntaxis van een programmeertaal.
een token is een geldige reeks tekens gegeven door een lexeme, het wordt behandeld als een eenheid in de grammatica van de programmeertaal.
in een programmeertaal;
- trefwoorden
- Operators
- Interpunctiesymbolen
- constanten
- Identifiers
- getallen
een patroon is een regel die overeenkomt met een reeks tekens(lexemen) die door het token wordt gebruikt. Het kan worden gedefinieerd door reguliere expressies of grammatica regels.
Een voorbeeld van Lexicale Analyse
Code
#include<iostream>// exampleint main(){ int a, b; a = 7; return 0;}Penningen
| Lexemes | Penningen |
|---|---|
| int | zoekwoorden |
| main | zoekwoorden |
| ( | operator |
| ) | operator |
| { | operator |
| int | zoekwoorden |
| een | id |
| , | operator |
| b | id |
| ; | operator |
| een | id |
| = | opdracht symbool |
| 10 | 10(aantal) |
| ; | operator |
| terug | zoekwoorden |
| 0 | 0(aantal) |
| ; | operator |
| } | operator |
Niet Penningen
| Type | Penningen |
|---|---|
| preprocessor richtlijn | #include<iostream> |
| reactie | // voorbeeld |
Het proces van lexicale analyse bestaat uit twee fasen.
- scannen-dit omvat het lezen van invoerkarakterenen het verwijderen van spaties en commentaren.
- tokenisatie-Dit is de productie van tokens als output.
architectuur van lexical analyzer
de belangrijkste taak van de lexical analyzer is om het gehele bronprogramma te scannen en tokens één voor één te identificeren.
Scanners worden geà mplementeerd om tokens te produceren wanneer de parser daarom verzoekt.

stappen:
- “get next token” wordt verzonden van de parser naar de lexical analyzer.
- de lexical analyzer scant de invoer totdat het” volgende token ” is gevonden.
- het token wordt teruggegeven aan de parser.
reguliere expressies
we gebruiken reguliere expressies om eindige talen uit te drukken door patronen te definiëren voor een eindige verzameling symbolen.
grammatica gedefinieerd door reguliere expressies is bekend als reguliere grammatica en de taal gedefinieerd door reguliere grammatica is bekend als reguliere taal.
er zijn algebraïsche regels die worden gevolgd door reguliere expressies die worden gebruikt om reguliere expressies in gelijkwaardige vormen te manipuleren.
operaties.
Unie van twee talen A en B wordt geschreven als
A U B = {s | S staat in A of s staat in B}
aaneenschakeling van twee talen A en B wordt geschreven als
AB = {ss | S Staat In A en s staat in B}
de kleenafsluiting van een taal A wordt geschreven als
A* = wat gelijk is aan nul of meer voorkomen van taal A.
Notaties.
als x en y reguliere expressies zijn die talen A(x) en B(y) aanduiden, dan is
(x) een reguliere expressie die A(x) aanduidt.
Union|x) / (y) is een reguliere expressie die A(x) B (y) aangeeft.
concatenatie (x) (y)is een reguliere expressie die A(x) B(y) deuken.
Kleen closure (x)*is een reguliere expressie die aangeeft (A(x)) *
voorrang en associativiteit.
* ‘ concatenatie .’en / (pipe) zijn links associatief.
Kleen closure * heeft de hoogste prioriteit.
aaneenschakeling (.) volgt in voorrang.
(pipe) / heeft de LAAGSTE prioriteit.
vertegenwoordigt geldige tokens van een taal in reguliere expressies.
X is een reguliere expressie, daarom;
- x * staat voor nul of meer voorkomen van x.
- x + staat voor één of meer voorkomen van x, dat wil zeggen{x, xx, xxx}
- x? vertegenwoordigt ten hoogste één gebeurtenis van x ie {x}
- vertegenwoordigt alle kleine letters alfabetten in de Engelse taal.
- staan voor alle hoofdletters in de Engelse taal.
- vertegenwoordigen alle natuurlijke getallen.
die het voorkomen van symbolen met behulp van reguliere expressies
Letter = of
Digit = of|0|1|2|3|4|5|6|7|8|9
Sign =
vertegenwoordigt taaltokens met reguliere expressies.
decimaal = (teken)?(cijfer)+
Identifier = (letter) (letter | cijfer)*
eindige automaten
dit is de combinatie van vijf tupels (Q, Σ, q0, qf, δ) gericht op toestanden en overgangen door middel van invoersymbolen.
het herkent patronen door de tekenreeks als invoer te nemen en verandert zijn toestand dienovereenkomstig.
het wiskundige model voor eindige automaten bestaat uit;
- eindige verzameling van toestanden (Q)
- eindige verzameling van inputsymbolen (Σ)
- één begintoestand (q0)
- verzameling eindtoestanden (qf)
- overgangsfunctie (δ)
eindige automata wordt gebruikt in lexicale analyse om tokens in de vorm van identifiers, trefwoorden en constanten van het invoerprogramma te produceren.
eindige automaten voeden de reguliere expressie string en de status wordt gewijzigd voor elke letter.
als de invoer met succes wordt verwerkt, bereikt de automaat de uiteindelijke status en wordt deze geaccepteerd.
constructie van eindige automaten
zij L(r) een reguliere taal door sommige eindige automaten F (A).
daarom;
- Staten: Cirkels zullen de Staten van FA vertegenwoordigen en hun namen worden geschreven in de cirkels.
- Startstatus: Dit is de status waarin de automata start. Er zal een pijl naar hem wijzen.
- tussenliggende toestanden: deze hebben twee pijlen, één die ernaar wijst en een andere die vanuit de tussenliggende toestanden wijst.
- Eindtoestand: Automata zullen naar verwachting in de eindtoestand zijn wanneer de invoerstring met succes is ontleed en wordt weergegeven door dubbele Cirkels anders wordt de invoer geweigerd. Het kan een oneven aantal pijlen bevatten die ernaar wijzen en een even getal dat erop wijst, dat wil zeggen,
oneven pijlen = even pijlen + 1. - overgang: wanneer een gewenst symbool wordt gevonden in de invoer, zal de overgang van de ene toestand naar de andere plaatsvinden. De automata gaat naar de volgende staat of blijft bestaan.
een gerichte pijl toont de beweging van de ene toestand naar de andere, terwijl een pijl naar de doeltoestand wijst.
als de automaten in dezelfde toestand blijven, wordt een pijl getrokken die van een toestand naar zichzelf wijst.
een voorbeeld; neem aan dat een binaire waarde van 3 cijfers die eindigt op 1 door FA wordt geaccepteerd.
dan FA = {Q (q0, qf), Σ (0,1), q0, qf, δ}
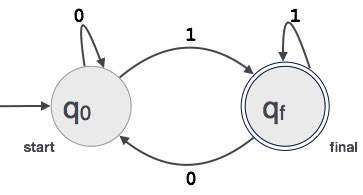
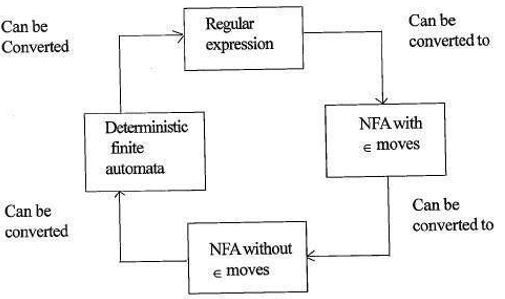
relatie tussen reguliere expressies en eindige automaten
de relatie tussen reguliere expressies en eindige automaten is als volgt;
de onderstaande figuur laat zien dat het gemakkelijk is om te converteren;
- reguliere expressies naar niet-deterministische eindige automaten (NFA) met moves-bewegingen.
- niet-deterministische eindige automaten met ∈ beweegt naar zonder moves beweegt
- niet-deterministische eindige automaten zonder ∈ beweegt naar deterministische eindige automaten (DFA).
- deterministische eindige automaten tot reguliere expressie.
een Lex accepteert reguliere expressies als invoer, en geeft een programma terug dat een eindige automaat simuleert om de reguliere expressies te herkennen.
daarom zal lex string pattern generation (regular expressions defining the strings of interest to lex) en string pattern recognition (een eindige automaat die de strings of interest herkent) combineren.
regel met langste overeenkomst
Hierin staat dat de gescande lexeme moet worden bepaald op basis van de langste overeenkomst tussen alle beschikbare tokens.
dit wordt gebruikt om dubbelzinnigheden op te lossen bij het bepalen van het volgende token in de invoerstroom.
tijdens de analyse van de broncode scant de lexical analyzer code letter voor letter en wanneer een operator, speciaal symbool of witruimte wordt gedetecteerd, beslist het of een woord volledig is.
voorbeeld:
int intvalue;tijdens het scannen van het bovenstaande, kan de analyzer niet bepalen of’ int ‘ een trefwoord is Int of het voorvoegsel van de identifier intvalue.
Regelprioriteit wordt toegepast waarbij een trefwoord voorrang krijgt boven invoer door de gebruiker, wat betekent dat in het bovenstaande voorbeeld de analyzer een fout genereert.
lexicale fouten
een lexicale fout treedt op wanneer een tekenreeks niet kan worden gescand in een geldig token.
deze fouten kunnen worden veroorzaakt door een spelfout van identifiers, trefwoorden of operators.
over het algemeen, hoewel zeer ongewone lexicale fouten worden veroorzaakt door ongeldige tekens in een token.
fouten kunnen;
- spelfout.
- omzetting van twee tekens.
- ongeldige tekens.
- groter is dan de lengte van de identifier of numerieke constanten.
- vervanging van een teken door een onjuist teken
- verwijdering van een teken dat aanwezig zou moeten zijn.
foutherstel met zich meebrengt;
- een teken verwijderen uit de resterende invoer
- twee aangrenzende tekens omzetten
- een teken verwijderen uit de resterende invoer
- ontbrekende tekens invoegen in de resterende invoer
- een teken vervangen door een ander teken.
- het negeren van opeenvolgende tekens totdat een juridisch token wordt gevormd (panic mode recovery).
Foutherstelschema ‘ s
Panic mode recovery.
in dit foutherstelschema worden ongeëvenaarde patronen verwijderd uit de resterende invoer totdat de lexical analyzer een goed gevormd token kan vinden aan het begin van de resterende invoer.
eenvoudiger implementatie is een voordeel voor deze aanpak.
het heeft de beperking dat een grote hoeveelheid invoer wordt overgeslagen zonder te controleren op extra fouten.
Lokale Correctie.
wanneer een fout wordt gedetecteerd op een punt worden invoegen / verwijderen en / of vervangen totdat een goed gevormde tekst is bereikt.
de analyzer wordt herstart met de resulterende nieuwe tekst als invoer.
globale correctie.
het is een verbeterde paniekmodus herstel bij voorkeur wanneer lokale correctie mislukt.
het heeft hoge tijd – en ruimtevereisten en wordt daarom in de praktijk niet toegepast.
behoefte aan lexicale analyzers
- verbeterde efficiëntie van de compiler-gespecialiseerde buffertechnieken voor het lezen van tekens versnellen het proces van de compiler.
- eenvoud van compilerontwerp-het verwijderen van witruimtes en commentaren zal efficiënte syntactische constructies voor de syntaxisanalysator mogelijk maken.
- portabiliteit van compilers – alleen de scanner communiceert met de buitenwereld.
- specialisatie-gespecialiseerde technieken kunnen worden gebruikt om het lexicale analyseproces te verbeteren
problemen met lexicale analyse
- Lookahead
bij een invoerstring worden tekens één voor één van links naar rechts gelezen.
om te bepalen of een token klaar is of niet, moeten we naar het volgende teken kijken.
voorbeeld: Is ‘ = ‘een toegewezen operator of het eerste teken in ‘= = ‘ operator.
Lookahead slaat tekens over in de invoer totdat een goed gevormd token is gevonden, dit laat zien dat vooruitkijken geen significante fouten kan opvangen, behalve eenvoudige fouten zoals illegale symbolen. - ambiguïteiten
de met lex geschreven programma ‘ s accepteren ambigue specificaties en kiezen daarom de langste overeenkomst en wanneer meerdere expressies overeenkomen met de invoer wordt ofwel de langste overeenkomst gekozen of wordt de eerste regel van de overeenkomende regels voorrang gegeven. - gereserveerde sleutelwoorden
bepaalde talen hebben gereserveerde woorden die niet zijn gereserveerd in andere programmeertalen, bijvoorbeeld elif is een gereserveerde woord in python, maar niet in C. - Contextafhankelijkheid
voorbeeld:
gegeven het statement DO 10 l = 10.86, is DO10l een identifier en DO is geen trefwoord.
en gezien de verklaring DO 10 l = 10, 86, is DO een sleutelwoord
.
toepassingen
- gebruikt door compilers Maken voldaan binaire uitvoerbare bestanden van ontleed code.
- gebruikt door webbrowsers om een webpagina te formatteren en weer te geven die HTML -, CSS-en java-script bevat.
met dit artikel op OpenGenus moet u een sterk idee hebben van lexicale analyse in Compiler Design.