met complexe netwerken bestaande uit cloud, hybride IT, virtualisatie, storage area networks, enzovoort, kunnen veelzijdige IT-problemen moeilijk te lokaliseren en diagnosticeren zijn. Wanneer een probleem opduikt, bijvoorbeeld een slecht presterende applicatie of server, kan het onderzoek veel tijd in beslag nemen om het kernprobleem te lokaliseren. Het probleem kan zijn in opslag, netwerkconnectiviteit, gebruikerstoegang, of een mix van bronnen en configuraties.
om het probleem te onderzoeken, kunt u problemen oplossen met het Performance Analysis (PerfStack™) dashboard dat Historische gegevens van meerdere SolarWinds-producten en entiteitstypen visueel correleert in één weergave.
met dashboards voor prestatieanalyse kunt u het volgende doen:
- vergelijk en analyseer meerdere metrische typen in één weergave, inclusief status, gebeurtenissen en statistieken.
- vergelijk en analyseer metrics voor meerdere entiteiten in één weergave, waaronder knooppunten, interfaces, volumes, toepassingen en meer.
- correleer gegevens van over het Orion-Platform op één gedeelde tijdlijn.
- visualiseer hybride gegevens voor on-premises, cloud en alles daartussenin.
- deel een probleemoplossingsproject met uw teams en experts om historische gegevens te bekijken voor een probleem.
voor VMAN zijn de mogelijkheden eindeloos voor toepassingsanalyse en hybride omgevingen:
- loop visueel door historische gegevens voor VM ’s in uw omgeving
- Controleer problemen met brontoewijzing in hybride omgevingen
- correleer gegevens om problemen op te lossen met netwerkverkeer verzonden en ontvangen door virtuele servers (hosts, clusters, datastores en VM’ s), On-premises servers en cloudinstances
het volgende voorbeeld laat u zien hoe u een hoofdoorzaak kunt identificeren voor een VM die prestatieproblemen ondervindt. In dit scenario kreeg een virtuele host te maken met een bron-en prestatieprobleem tot het punt waarop gebruikers tragere antwoorden en toegang krijgen. Het probleem veroorzaakte een waarschuwing, die de eigenaar van de toepassing op de hoogte, die het probleem escaleerde naar Systeem-en netwerkbeheerders.
Maak een nieuw project voor probleemoplossing om het probleem te onderzoeken om metrics voor de host en alle gerelateerde virtuele omgevingsystemen te vergelijken om trends en pieken in gebruik bij te houden.
-
selecteer in de Orion-webconsole mijn Dashboards > Home > prestatieanalyse.
Hiermee opent u het dashboard Performance Analysis, of PerfStack, om grafieken en grafieken te bouwen met behulp van statistieken uit bewaakte applicaties en servers in het metrische palet. Elke grafiek kan meerdere statistieken bevatten om gegevens direct te correleren.
-
klik in het nieuwe Analyseproject op entiteiten toevoegen.
om te beginnen, moet u de VM in nood lokaliseren en toevoegen. Voer in het zoekveld syd in om een lijst te tonen van virtuele servers die die naam delen. Vouw en selecteer Types of Status om de lijst te filteren indien nodig.
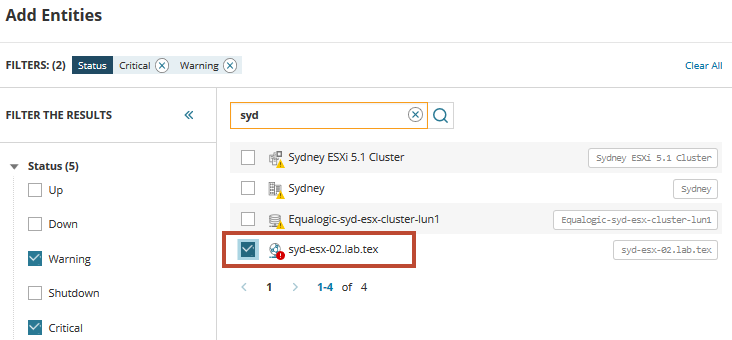
uit de lijst, vinden we de virtuele host tegenkomen van de problemen en triggering waarschuwingen. Selecteer de host en voeg deze toe aan het dashboard metrische palet. Klik op het pictogram gerelateerde entiteiten om alle gerelateerde servers en services weer te geven aan de host.
geïnteresseerd in alle geassocieerde knooppunten, toepassingen, servers en meer aan dit geselecteerde knooppunt? Klik op het pictogram gerelateerde entiteiten.
 alle gerelateerde entiteiten worden weergegeven in het metrische palet en bieden meer opties voor metrics die mogelijk problemen veroorzaken.
alle gerelateerde entiteiten worden weergegeven in het metrische palet en bieden meer opties voor metrics die mogelijk problemen veroorzaken.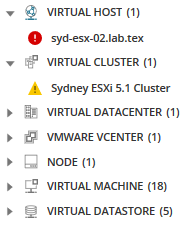
-
Selecteer het Syd host-knooppunt om te bekijken en selecteer metrics om naar het dashboard te slepen en neer te zetten. U kunt ze naar dezelfde grafiek slepen om waarden tussen statistieken te vergelijken.
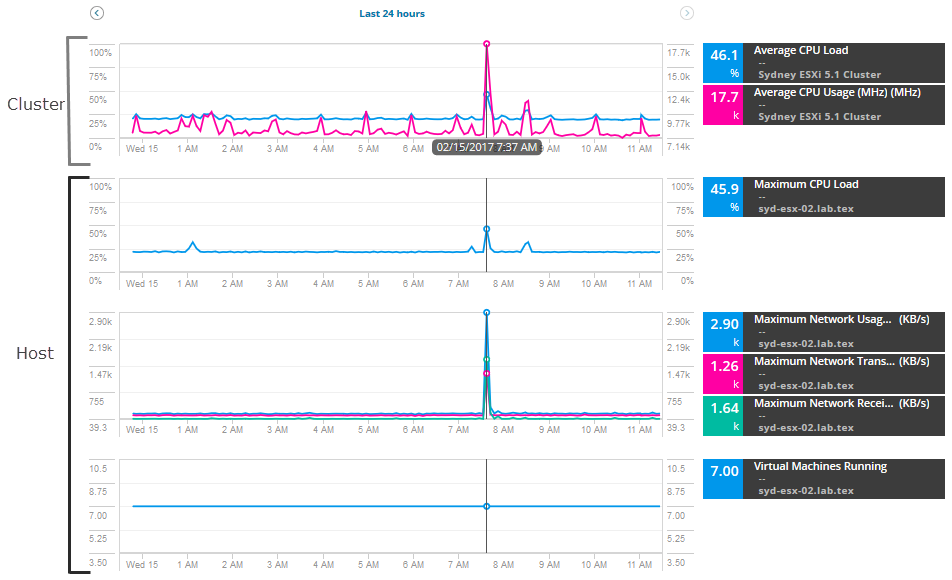
om te beginnen met het onderzoeken, trek een reeks metrics voor de host en cluster, het vergelijken van metrics om pieken of hoog gebruik te vinden. Voor dit scenario, voeg deze host metrics:
- maximaal netwerkgebruik
- maximale Netwerkdoorzendsnelheid
- maximale Netwerkontvangsnelheid
- virtuele Machines waarop
voor het cluster, voeg deze maatstaven toe:
- gemiddelde CPU-belasting
- gemiddeld CPU-gebruik
de grafieken en grafieken worden weergegeven met gegevens en waarschuwingen voor de laatste 12 uur van statistieken. U kunt de datum en tijd uit te breiden om extra historische statistieken te zien in de loop van de waarschuwing.
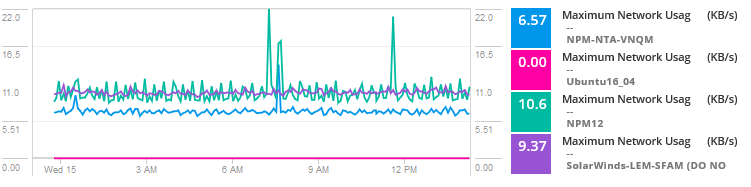
voeg gebruiksstatistieken toe voor VM ‘ s op de host om het netwerkgebruik en de activiteit te vergelijken.
-
door de gegevens te analyseren, lijkt het probleem een lawaaierige buur te zijn voor een van de virtuele machines die resources verbruiken en veel verkeer ervaren, waardoor knelpunten en problemen ontstaan voor VM ‘ s die de host delen. Kortom, een andere server, service, of toepassing verbruikt hogere bandbreedte, disk I/O, CPU, en andere bronnen die problemen veroorzaken voor deze specifieke toepassing.
deze informatie geeft uw netwerk-en systeembeheerders een richting voor verder onderzoek en het oplossen van latency problemen. Om dit op te lossen, kunnen ze middelen opnieuw toewijzen of de toepassing met hoog verbruik verplaatsen naar een andere locatie.
-
klik op Opslaan en geef het project een naam.
het project slaat op als een dashboard met de geselecteerde statistieken in het ingestelde datum-en tijdbereik.
wanneer deze wordt opgeslagen, wordt de URL een deelbare link. Kopieer en deel de link naar het opgeslagen dashboard in tickets of e-mails verzonden door het systeem en netwerkbeheerders en de eigenaar van het product. Ze hebben toegang tot de link om de verzamelde gegevens te bekijken en problemen op te lossen.
na het opnieuw toewijzen van middelen en het maken van wijzigingen in het netwerk, heropenen van het dashboard om wijzigingen en nieuwe gebruikstrends voor polled metrics controleren.