Database Snapshot is het maken van een onveranderlijke afbeelding van de database, Je kunt het zien als het nemen van de huidige foto van de database.
als ik het aan de hand van een voorbeeld uitleg zal het duidelijker zijn.
bijvoorbeeld, we nemen de snapshot van de AdventureWorks2014 database. We lezen deze momentopname door. Er zijn nog geen wijzigingen aangebracht in de AdventureWorks2014 database. Onze selects gaan naar de oorspronkelijke database omdat er geen verandering is in de oorspronkelijke database.
als er veranderingen optreden in de oorspronkelijke database, worden deze veranderingen naar een speciale ruimte op de schijf geschreven voor snapshots (Sparse Files genoemd).
wanneer we de gegevens willen lezen, als de gegevens zijn gewijzigd in de oorspronkelijke database, wordt de ongewijzigde versie van de gegevens gelezen uit het sparse bestand. Op deze manier wordt de foto intact.
hoewel het geen schijfruimte in beslag neemt zodra we Snapshot krijgen, zal de grootte van de schaarse bestanden toenemen naarmate de veranderingen in de oorspronkelijke database toenemen. Als de grootte van de schaarse bestanden groeit en er is geen ruimte meer over in de schijf, wordt de snapshot verdacht en MOET u de snapshot verwijderen.
het wordt meestal gebruikt met Mirroring-technologie.
lees mijn artikel “Database Mirroring On SQL Server”. In Mirroring kunnen we niet lezen uit de secundaire database. Als we willen lezen uit de secundaire database, kunnen we dit doen door een snapshot van de secundaire database.
en op deze manier creëren we geen last voor het rapport in de primaire database door het maken van onze rapport query ‘ s vanuit de secundaire database.
of u kunt de momentopname van de database krijgen voordat u een batch-update of verwijderbewerking uitvoert. Een onjuiste update-of verwijderbewerking kan worden omgekeerd met behulp van snapshot. Het zou een veel snellere methode dan terug te keren van back-up.
Snapshot moet op dezelfde instantie staan als de database.
laten we doorgaan met twee voorbeelden.
in het eerste voorbeeld krijgen we een snapshot om te kunnen lezen uit de secundaire database van de gespiegelde database.
in het tweede voorbeeld krijgen we een snapshot om een onjuiste updatebewerking om te keren.
Voorbeeld1:
eerst moet de gespiegelde database synchroon zijn. Dus het beeld van je secundaire database moet als volgt zijn.
![]()
vervolgens maken we de Snapshot met behulp van het volgende script. U moet alle bestanden in de database opgeven.
in ons voorbeeld waren er twee bestanden. We hebben snapshot gemaakt voor deze twee bestanden. Als u niet bekend bent met FileGroup en File, kunt u mijn artikel lezen “Hoe maak je een Database op SQL Server”.
|
1
2
3
4
5
|
MAAK een DATABASE AdventureWorks2014_Snapshot OP
( NAAM = AdventureWorks2012_Data, FILENAME = ‘C:\DB\Data\AdventureWorks2012_Data.ss’ ),
( NAME = AdventureWorks2014_Deneme, FILENAME = ‘C:\DB\Data\AdventureWorks2014_Deneme.ss’)
als momentopname van Avontuurwerken2014;
GO
|
ik kreeg het volgende script van msdn.
met het volgende script kunt u de grootte van de snapshot op de schijf vinden en de maximale grootte die deze kan vergroten.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
SELECTEER DB_NAME(sd.source_database_id) AS,
sd.name AS,
mf.name AS,
size_on_disk_bytes / 1024 AS,
mf2.grootte / 128 als
van sys.master_files MF
JOIN sys.databases sd
op mf.database_id = sd.database_id
JOIN sys.master_files mf2
op sd.source_database_id = mf2.database_id
en mf.bestand_id = mf2.file_id
CROSS APPLY sys. dm_io_virtual_file_stats(sd. database_id, mf.file_id)
waarbij MF. is_sparse = 1
en mf2. is_sparse = 0
1;
|
de volgende resultaatset kwam terug toen ik het script uitvoerde. Ik stel de grootte van deze twee gegevensbestanden in op 256 mb.
daarom kan de snapshot groeien tot maximaal 256 MB.
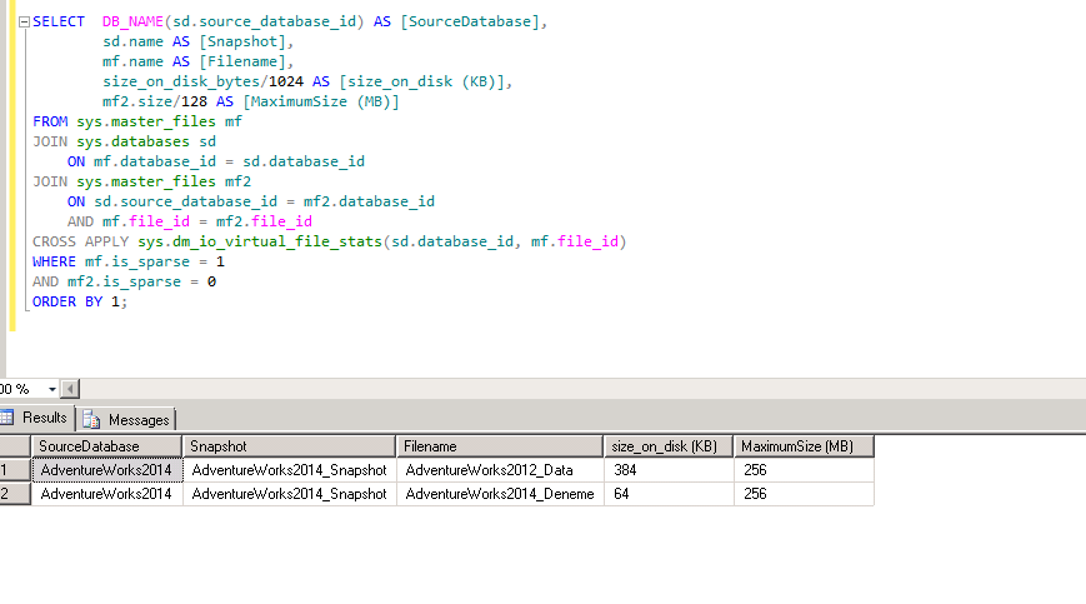
we hebben onze snapshot gemaakt.
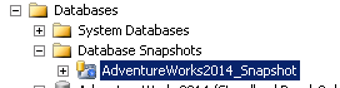
u kunt van uw snapshot lezen alsof het een database is uit de sectie Databases-> Database Snapshots op SSM ‘ s.
normaal gesproken kunt u niet lezen uit secundaire database bij mirroring. Maar je kunt lezen uit de snapshot van de secundaire database.
Voorbeeld 2:
laten we het script hieronder in de primaire database uitvoeren.
|
1
2
3
4
5
|
MAAK een DATABASE AdventureWorks2014_Snapshot OP
( NAAM = AdventureWorks2012_Data, FILENAME = ‘C:\DB\Data\AdventureWorks2012_Data.ss’ ),
( NAME = AdventureWorks2014_Deneme, FILENAME = ‘C:\DB\Data\AdventureWorks2014_Deneme.ss’)
als momentopname van Avontuurwerken2014;
GO
|
nadat u een Snapshot hebt gemaakt, verwijdert u alle records in een tabel met behulp van het volgende script. Ik verwijder records uit de tabel met de naam Snapshot_deneme die ik eerder in de AdventureWorks2014-database heb gemaakt.
|
1
|
verwijderen uit Snapshot_deneme
|
na het verwijderingsproces, kunt u uw verwijderde records te herstellen met behulp van het volgende script.
maar als u een andere bewerking hebt uitgevoerd na het maken van een snapshot, verliest u deze wijzigingen.
|
1
2
3
|
GEBRUIK de master
NAAR
RESTORE DATABASE AdventureWorks2014 VAN DATABASE_SNAPSHOT = ‘AdventureWorks2014_Snapshot’
|


Auteur: dbtut
Wij zijn een team met meer dan 10 jaar van database management en BI-ervaring. Onze Expertises: Oracle, SQL Server, PostgreSQL, MySQL, MongoDB, Elasticsearch, Kibana, Grafana.