laten we eerlijk zijn, wanneer uw bedrijf niet vertegenwoordigd is op het Internet, is het onbestaand voor de wereld. Bovendien, als je niet beschikt over een website, verliest u een ruime kans om meer kwaliteit leads aan te trekken. Elk bedrijf van een corporate Gigant zoals Amazon om een eenpersoonsbedrijf streeft ernaar om een website en inhoud die een beroep op hun publiek. Het online ontdekken van u en uw bedrijf houdt daar niet op. Achter websites, Er is een hele “onzichtbaar voor het menselijk oog” wereld waar webcrawlers een belangrijke rol spelen.
inhoud
- Wat Is een webcrawler en indexering?
- Hoe werkt een zoekopdracht op het Web?
- Hoe werkt een webcrawler?
- Wat zijn de belangrijkste typen webcrawlers?
- Wat zijn voorbeelden van webcrawlers?
- Wat Is een Googlebot?
- Webcrawler vs Webscraper-Wat Is het verschil?
- Aangepaste Webcrawler — Wat Is Het?
- inpakken
Wat Is een webcrawler en indexering?
laten we beginnen met een webcrawler definitie:
een webcrawler (ook bekend als een webspin, spider bot, webbot, of gewoon een crawler) is een computerprogramma dat wordt gebruikt door een zoekmachine om webpagina ‘ s en inhoud te indexeren over het wereldwijde Web.
indexeren is een essentieel proces omdat het gebruikers helpt relevante query ‘ s binnen enkele seconden te vinden. De zoekindexering kan worden vergeleken met de boekindexering. Als u bijvoorbeeld de laatste pagina ’s van een leerboek opent, vindt u een index met een lijst met zoekopdrachten in alfabetische volgorde en pagina’ s waar ze in het leerboek staan. Hetzelfde principe onderstreept de zoekindex, maar in plaats van paginanummering toont een zoekmachine u enkele links waar u naar antwoorden op uw vraag kunt zoeken.
het significante verschil tussen de zoekindexen en de boekindexen is dat de eerste dynamisch is, dus kan worden gewijzigd, en de laatste altijd statisch is.
Hoe werkt een zoekopdracht op het Web?
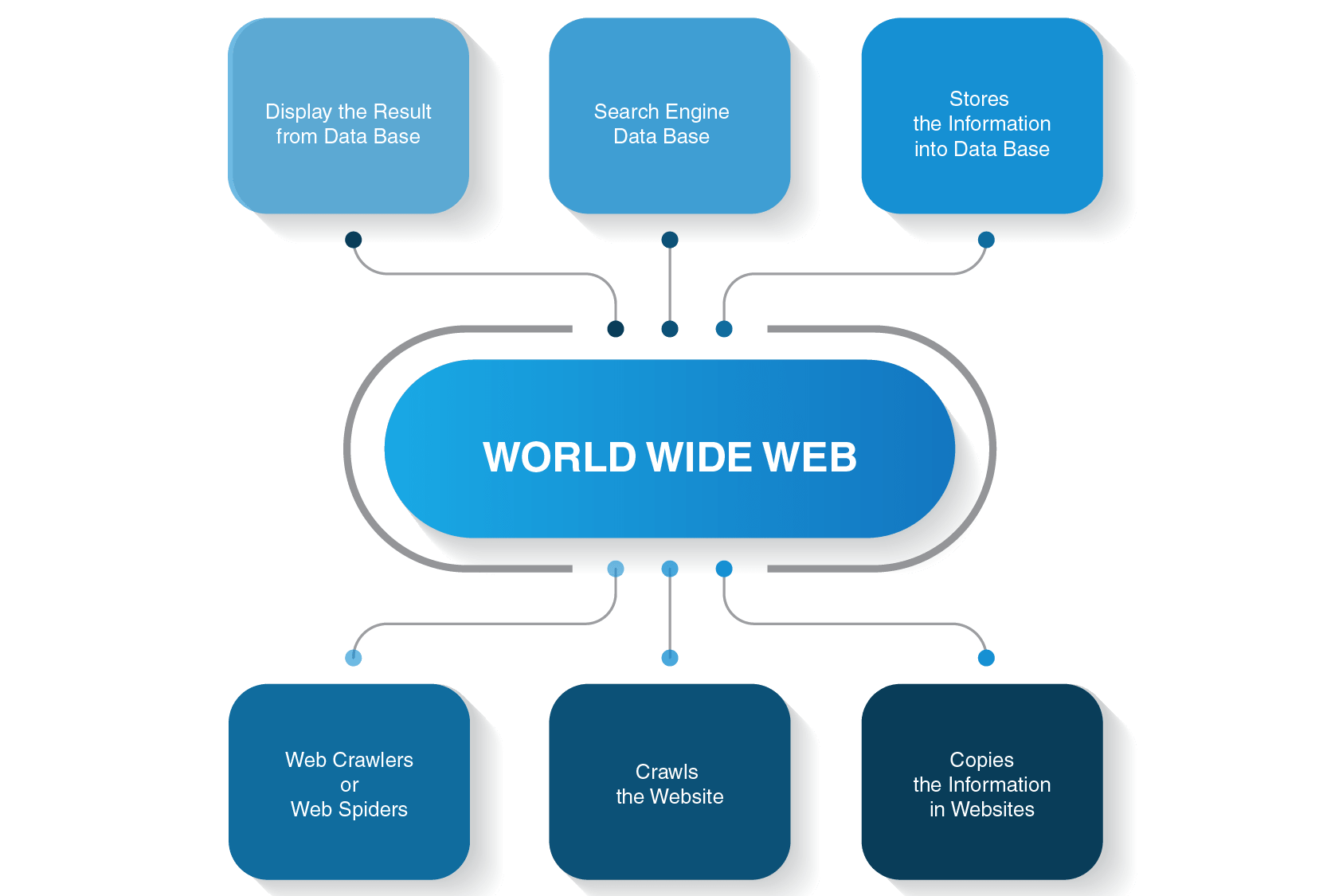
voordat we ingaan op de details van hoe een crawler robot werkt, laten we eens kijken hoe het hele zoekproces wordt uitgevoerd voordat u een antwoord op uw zoekopdracht krijgt.
als u bijvoorbeeld “Wat is de afstand tussen aarde en Maan” typt en op enter drukt, zal een zoekmachine u een lijst van relevante pagina ‘ s tonen. Meestal, het duurt drie belangrijke stappen om gebruikers te voorzien van de vereiste informatie om hun zoekopdrachten:
- een webspin kruipt inhoud op websites
- het bouwt een index voor een zoekmachine
- zoekalgoritmen rangschikken de meest relevante pagina ‘ s
ook moet men rekening houden met twee essentiële punten:
- u doet uw zoekopdrachten niet in real-time omdat het onmogelijk is
er zijn tal van websites op het World Wide Web, en er worden er nog veel meer gemaakt, zelfs nu u dit artikel leest. Dat is de reden waarom het zou kunnen duren eons voor een zoekmachine om te komen met een lijst van pagina ‘ s die relevant zijn voor uw zoekopdracht zou zijn. Om het proces van zoeken te versnellen, kruipt een zoekmachine de pagina ‘ s voordat ze aan de wereld worden getoond.
- u doet uw zoekopdrachten niet in het World Wide Web
u doet inderdaad geen zoekopdrachten in het World Wide Web maar in een zoekindex en dit is wanneer een webcrawler het slagveld betreedt.
Neem Nu Contact Met Ons Op!
Hoe werkt een webcrawler?
er zijn veel zoekmachines die er zijn − Google, Bing, Yahoo!, DuckDuckGo, Baidu, Yandex, en vele anderen. Elk van hen gebruikt zijn spider bot om pagina ‘ s te indexeren.
ze starten hun kruipproces vanaf de meest populaire websites. Hun primaire doel van web bots is om de essentie van wat elke pagina inhoud is alles over te brengen. Dus, web spiders zoeken woorden op deze pagina ‘ s en vervolgens het bouwen van een praktische lijst van deze woorden die zal worden gebruikt door een zoekmachine volgende keer wanneer u wilt informatie over uw zoekopdracht te vinden.
alle pagina ’s op het Internet zijn verbonden door hyperlinks, zodat site spiders deze links kunnen ontdekken en ze kunnen volgen naar de volgende pagina’ s. Web bots stoppen alleen wanneer ze alle inhoud en verbonden websites te vinden. Vervolgens sturen ze de opgenomen informatie een zoekindex, die wordt opgeslagen op servers over de hele wereld. Het hele proces lijkt op een echt spinnenweb waar alles met elkaar verweven is.
het crawlen stopt niet onmiddellijk nadat pagina ‘ s zijn geïndexeerd. Zoekmachines gebruiken periodiek web spiders om te zien of er wijzigingen zijn aangebracht aan pagina ‘ s. Als er een wijziging is, zal de index van een zoekmachine dienovereenkomstig worden bijgewerkt.
Wat zijn de belangrijkste Webcrawler Types?
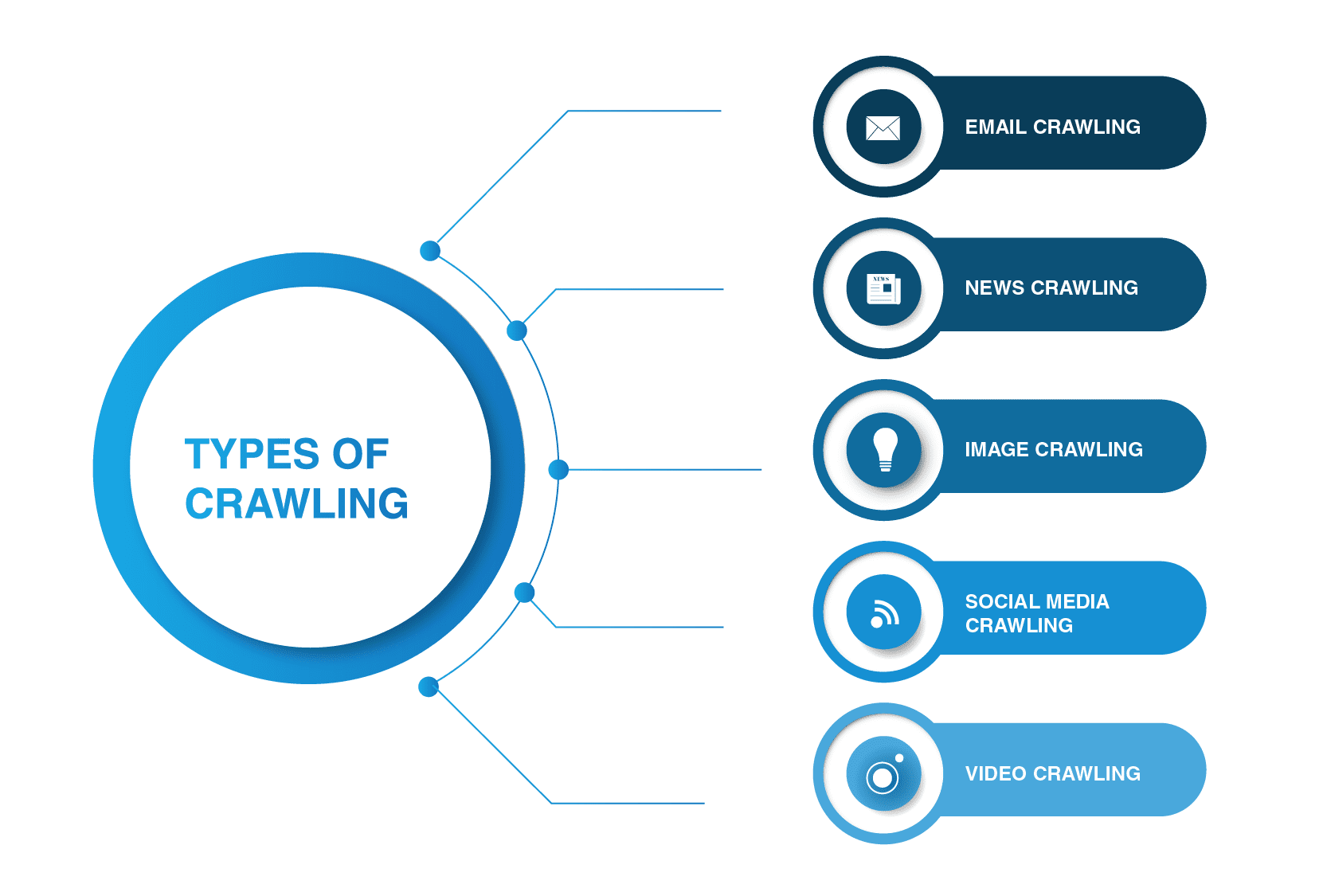
webcrawlers zijn niet beperkt tot zoekmachine spiders. Er zijn andere soorten web kruipen er.
- e-mail crawlen
e-mail crawlen is vooral nuttig bij uitgaande leadgeneratie, omdat dit type crawlen helpt bij het extraheren van e-mailadressen. Het is vermeldenswaard dat dit soort kruipen illegaal is omdat het de persoonlijke privacy schendt en niet kan worden gebruikt zonder toestemming van de gebruiker.
- News crawling
met de komst van het Internet kan nieuws van over de hele wereld snel verspreid worden over het Web, en het extraheren van gegevens van verschillende websites kan behoorlijk onbeheersbaar zijn.
er zijn veel webcrawlers die deze taak aankunnen. Dergelijke crawlers zijn in staat om gegevens op te halen uit nieuwe, oude, en gearchiveerde nieuws inhoud en lees RSS-feeds. Ze halen de volgende informatie: Publicatiedatum, naam van de auteur, koppen, lead alinea ‘ s, hoofdtekst en publicatietaal.
- Image crawling
zoals de naam al aangeeft, wordt dit type crawling toegepast op afbeeldingen. Het Internet staat vol met visuele representaties. Zo, dergelijke bots helpen mensen relevante foto ‘ s te vinden in een overvloed aan afbeeldingen op het Web.
- crowling van sociale media
crowling van sociale media is een interessante zaak omdat niet alle sociale media platforms het mogelijk maken om te crawlen. U moet ook in gedachten houden dat een dergelijk type kruipen illegaal kan zijn als het in strijd is met de naleving van de privacy van gegevens. Nog steeds, er zijn veel social media platform providers die goed zijn met kruipen. Bijvoorbeeld, Pinterest en Twitter laten spider bots om hun pagina ‘ s te scannen als ze niet Gebruiker-gevoelig zijn en geen persoonlijke informatie vrij te geven. Facebook, LinkedIn zijn strikt in deze kwestie.
- video crawling
soms is het veel gemakkelijker om een video te bekijken dan veel inhoud te lezen. Als u besluit om Youtube, Soundcloud, Vimeo of andere video-inhoud in te sluiten op uw website, kan deze worden geïndexeerd door sommige webcrawlers.
Wat zijn voorbeelden van webcrawlers?
veel zoekmachines gebruiken hun eigen zoekrobots. Bijvoorbeeld, de meest voorkomende webcrawlers voorbeelden zijn:
- Alexabot
Amazon web crawler Alexabot wordt gebruikt voor web content identificatie en backlink discovery. Als u een deel van uw informatie privé wilt houden, kunt u Alexabot uitsluiten van het crawlen van uw website.
- Yahoo! Slurp Bot
Yahoo crawler Yahoo! Slurp Bot wordt gebruikt voor het indexeren en schrapen van webpagina ‘ s om gepersonaliseerde inhoud voor gebruikers te verbeteren.
- Bingbot
Bingbot is een van de populairste webspinnen van Microsoft. Het helpt een zoekmachine, Bing, om de meest relevante index voor de gebruikers te creëren.
- Duckduck Bot
DuckDuckGo is waarschijnlijk een van de meest populaire zoekmachines die uw geschiedenis niet bijhouden en u volgen op welke sites u ook bezoekt. De DuckDuck Bot web crawler helpt om de meest relevante en beste resultaten die zal voldoen aan de behoeften van een gebruiker te vinden.
- Facebook externe Hit
Facebook heeft ook zijn crawler. Bijvoorbeeld, wanneer een Facebook-gebruiker een link naar een externe inhoudspagina met een andere persoon wil delen, schraapt de crawler de HTML-code van de pagina en voorziet hen beiden van de titel, een tag van de video of afbeeldingen van de inhoud.
- Baiduspider
deze crawler wordt geëxploiteerd door de dominante Chinese zoekmachine − Baidu. Net als elke andere bot, het reist door een verscheidenheid van webpagina ‘ s en zoekt naar hyperlinks om inhoud te indexeren voor de motor.
- Exabot
de Franse zoekmachine Exalead gebruikt Exabot voor de indexering van inhoud, zodat deze in de index van de motor kan worden opgenomen.
- Yandex Bot
deze bot behoort tot de grootste Russische zoekmachine Yandex. U kunt het blokkeren van het indexeren van uw inhoud als u niet van plan bent om er zaken te doen.
Wat Is een Googlebot?
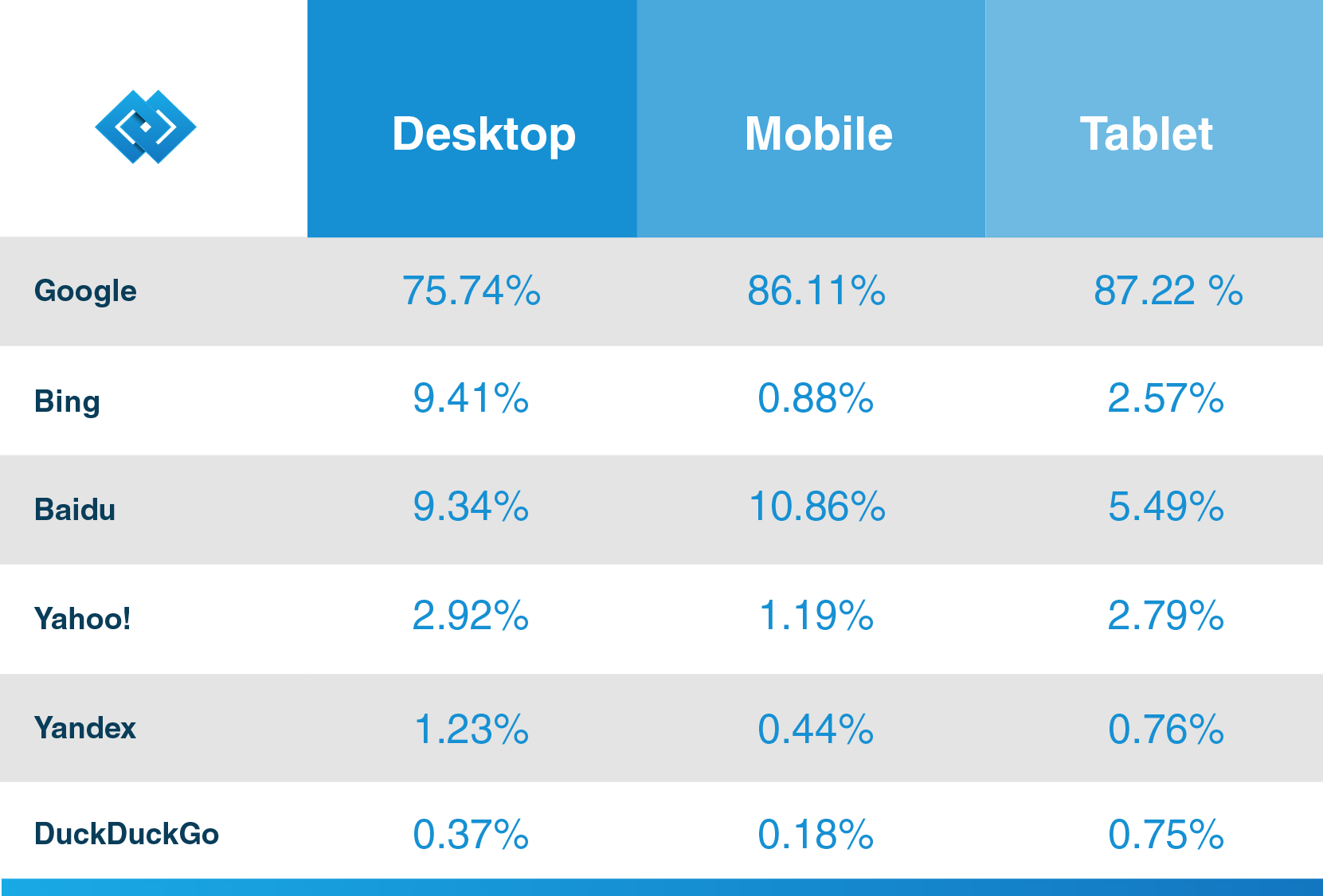
zoals hierboven vermeld, hebben bijna alle zoekmachines hun spider-bots, en Google is geen uitzondering. Googlebot is een Google crawler aangedreven door de meest populaire zoekmachine in de wereld, die wordt gebruikt voor het indexeren van inhoud voor deze Motor.Zoals Hubspot, een gerenommeerde CRM-leverancier, in zijn blog stelt, heeft Google meer dan 92,42% van de zoekmarkt en is het mobiele verkeer meer dan 86%. Dus, als u het meeste uit de zoekmachine voor uw bedrijf wilt halen, ontdek meer informatie over de web spider, zodat uw toekomstige klanten Uw inhoud kunnen ontdekken dankzij Google.
Googlebot kan uit twee typen bestaan: een desktop bot en een mobiele app crawlers, die de gebruiker op deze apparaten simuleren. Het gebruikt hetzelfde crawling principe als elke andere webspin, zoals het volgen van links en het scannen van inhoud die beschikbaar is op websites. Het proces is ook volledig geautomatiseerd en kan terugkerend zijn, wat betekent dat het dezelfde pagina meerdere keren op niet-regelmatige intervallen kan bezoeken.
als u klaar bent om inhoud te publiceren, duurt het dagen voordat de Google crawler deze indexeert. Als u de eigenaar van de website bent, kunt u het proces handmatig versnellen door een indexeringsverzoek in te dienen via Fetch als Google of door de sitemap van uw website bij te werken.
u kunt ook robots gebruiken.txt (of het Robots Exclusion Protocol) voor “het geven van instructies” aan een spider bot, waaronder Googlebot. Daar kunt u toestaan of verbieden crawlers om bepaalde pagina ‘ s van uw website te bezoeken. Houd er echter rekening mee dat dit bestand gemakkelijk toegankelijk is voor derden. Zij zullen zien welke delen van de site u beperkt van het indexeren.
Webcrawler vs Webscraper-Wat Is het verschil?
veel mensen gebruiken webcrawlers en webscrapers door elkaar. Toch is er een wezenlijk verschil tussen deze twee. Als de eerste gaat meestal over metadata van inhoud, zoals tags, koppen, trefwoorden, en andere dingen, de laatste “steelt” inhoud van een website te worden geplaatst op iemand anders online bron.
een schraper “jaagt” ook op specifieke gegevens. Bijvoorbeeld, als je nodig hebt om informatie te extraheren van een website waar er informatie zoals aandelenmarkt trends, Bitcoin prijzen, of een andere, kunt u gegevens van deze websites op te halen met behulp van een web schrapen bot.
als u uw website crawl, en u wilt uw inhoud in te dienen voor indexering, of een intentie voor andere mensen om het te vinden — het is volkomen legaal, anders schrapen van andere mensen en bedrijven websites is tegen de wet.
Aangepaste Webcrawler — Wat Is Het?
een aangepaste webcrawler is een bot die wordt gebruikt om een specifieke behoefte te dekken. U kunt uw spider bot te bouwen om elke taak die moet worden opgelost te dekken. Bijvoorbeeld, als u een ondernemer of marketeer of een andere professional die zich bezighoudt met inhoud, kunt u het gemakkelijker maken voor uw klanten en gebruikers om de informatie die ze willen vinden op uw website. U kunt een verscheidenheid van web bots voor verschillende doeleinden.
Als u geen praktische ervaring hebt met het bouwen van uw aangepaste webcrawler, kunt u altijd contact opnemen met een software development service provider die u daarbij kan helpen.
Wrapping Up
websitecrawlers zijn een integraal onderdeel van elke belangrijke zoekmachine die wordt gebruikt voor het indexeren en ontdekken van inhoud. Veel zoekmachine bedrijven hebben hun bots, bijvoorbeeld, Googlebot wordt aangedreven door de corporate gigant Google. Afgezien van dat, er zijn meerdere soorten kruipen die worden gebruikt om specifieke behoeften te dekken, zoals video, beeld, of sociale media kruipen.
rekening houdend met wat spider bots kunnen doen, zijn ze zeer essentieel en gunstig voor uw bedrijf, omdat webcrawlers u en uw bedrijf aan de wereld onthullen en nieuwe gebruikers en klanten kunnen brengen.
als u een aangepaste webcrawler wilt maken, neem dan contact op met LITSLINK, een ervaren provider van web development services, voor meer informatie.