
hur man dekonstruerar en modell från en databas eller ett skript
Reverse engineering är processen att skapa en datamodell från en databas eller ett skript. Modelleringsverktyget skapar en grafisk representation av de valda databasobjekten och relationerna mellan objekten. Denna grafiska representation kan vara en logisk eller en fysisk modell.
Obs: Du kan bakåtkompilera endast i en tom modell. Du kan inte omvända till en modell som har objekt i den.
en databas kan omvandlas av följande skäl:
- för att förstå hur objekten är relaterade till varandra och sedan bygga vidare på det
- för att visa databasstrukturen
när processen för omvänd teknik är klar kan du utföra följande uppgifter:
- Lägg till nya databasobjekt
- skapa systemdokumentationen
- omforma databasstrukturen så att den passar dina behov
det mesta av den information som du bakåtkompilerar är uttryckligen definierad i det fysiska schemat. Omvänd teknik härleder emellertid också information från schemat och införlivar den i modellen. Till exempel, om mål-DBMS stöder utländska nyckeldeklarationer, härleder reverse engineering-processen identifierande och icke-identifierande relationer och standardrollnamn.
du kan härleda all viktig modellinformation, förutom subtyprelationer, eftersom det för närvarande inte finns något SQL-databashanteringssystem som stöder det. Måldatabaserna varierar dock i mängden logisk datamodellinformation som ingår i det fysiska schemat. Av denna anledning kan de resulterande modellerna variera beroende på måldatabasen som väljs. Du kan också härleda viss logisk information, inklusive primärnycklar, främmande nycklar och tabellrelationer. Du kan använda tabellindexdefinitionerna eller kolumnnamnen för att härleda dessa nycklar och relationer.
du kan inkludera eller utesluta ri-utlösare i omvänd teknik. Du kan välja att behandla RI-utlösare som modellobjekt eller använda alternativet forward engineering för att inkludera RI-utlösare i schemat. Du kan också välja att inkludera eller utesluta dessa alternativ under omvänd teknik.
när du bakåtkompilerar en databas kan du ställa in en spårningsfil för att spela in de frågor som körs för att hämta objekt. Du kan granska frågorna när processen för omvänd teknik är klar.
följande diagram illustrerar stegen för att omvända en modell från en databas eller ett skript:
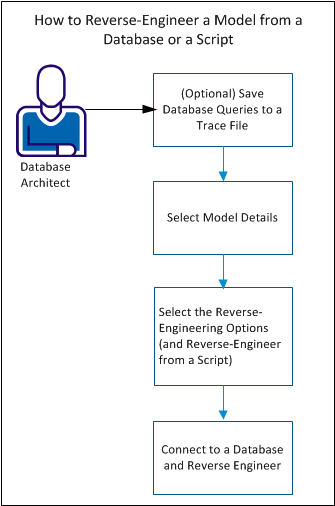
Slutför följande steg för att omvända en modell:
- (valfritt) spara databasfrågor till en spårningsfil.
- Välj modelldetaljer.
- Välj alternativ för omvänd teknik.
- Anslut till en databas och bakåtkompilera.
Reverse Engineering specifika objekt
det här avsnittet innehåller detaljer om hur reverse engineering processen fungerar för olika databasobjekt.
Index
när du bakåtkompilerar en databas importeras namn, definition och parametrar för varje index som definieras på servern. När du importerar indexinformationen från en server behålls lagringsplatsinformationen för varje index. Därför kan du återskapa databasen med samma lagringstilldelningar. Du behöver inte tilldela lagringsplatsen för varje index manuellt.
när du har importerat index kan du visa eller ändra indexegenskaper, definitioner och tabellassociationer i dialogrutan Index. Du kan tilldela ett index till ett fysiskt lagringsobjekt i dialogrutan Index för en DB2 z/OS, Informix, Oracle, SQL Server och SAP ASE-databas. Om måldatabasen är DB2 z/OS, Informix och Oracle kan du också ändra lagringsparametrarna i dialogrutan Index.
om ett fysiskt lagringsalternativ är valt för en DB2 z/OS -, Informix -, Oracle-eller SAP ASE-databas, innehåller schemat indexparametrar för fysisk lagring.
fysiskt lagringsobjekt
när du bakåtkompilerar en databas kan du importera namn och definitioner på fysiska lagringsobjekt som du har definierat på målservern. Importen sker på samma sätt som fysiska tabeller, index och annan fysisk schemainformation importeras. När du har importerat fysiska lagringsobjekt kan du visa eller ändra objektdefinitionerna och tabellassociationerna med hjälp av standardredigerarna.
valideringsregel
när reverse-engineering från ett schema fil, skript eller systemkatalog, valideringsregler importeras och bifogas lämplig tabell eller kolumn i den resulterande modellen. Konventionen som används för att namnge de importerade valideringsreglerna är följande:
VALID_RULEn
här är n ett löpnummer som börjar vid noll. Den första valideringsregeln som påträffas heter VALID_RULE0, nästa regel VALID_RULE1, och så vidare, tills hela schemat bearbetas.