i den här artikeln skriven av en leverantör av en säkerhetsövervakningslösning var huvudargumentet (ofta echoed i andra publikationer och olika mässor) att patching OT-system är svårt. Författaren hävdar att eftersom det är svårt bör vi vända oss till andra metoder för att förbättra säkerheten. Hans teori är att slå på en varningsteknik som hans och koppla ihop de pågående larmen med ett säkerhetsincidentsvarsteam. Med andra ord, bara acceptera patching är svårt, ge upp och häll mer pengar på att lära sig tidigare (kanske?) och svara mer kraftfullt.
men denna slutsats (patching är svår så stör inte) är felaktig av ett par skäl. För att inte tala om, glansar han också över en mycket stor faktor som väsentligt komplicerar alla svar eller saneringar som bör övervägas.
den första anledningen till att detta är farligt råd är att du helt enkelt inte kan ignorera patching. Du måste göra vad du kan, när du kan, och när patching inte är ett alternativ, flyttar du till plan B, C och D. Att göra ingenting betyder att alla cyberrelaterade incidenter som tar sig in i din miljö kommer att ge maximal skada. Detta låter mycket som m &m försvar från 20 år sedan. Detta är tanken att din säkerhetslösning ska vara hård och krispig på utsidan, men mjuk och seg på insidan.
den andra anledningen till att detta råd är felaktigt är antagandet att OT-säkerhetspersonal (för incidentrespons eller patching) är lätta att hitta och distribuera! Detta är inte sant-i själva verket, en av de ICS säkerhetsincidenter som refereras i artikeln påpekar att medan en patch var tillgängliga och redo för installation, det fanns inga ICS experter tillgängliga för att övervaka patch installationen! Om vi inte kan frigöra våra säkerhetsexperter för att distribuera känt skydd före händelsen som en del av ett proaktivt patchhanteringsprogram, Varför tror vi att vi kan hitta budgeten för ett fullständigt incidenthanteringsteam efter det faktum när det är för sent?
slutligen är det saknade stycket från detta argument att utmaningarna för OT/ICS-patchhantering förvärras ytterligare av mängden och komplexiteten hos tillgångar och arkitektur i ett OT-nätverk. För att vara tydlig, när en ny patch eller sårbarhet släpps, är de flesta organisationers förmåga att förstå hur många tillgångar som finns och var de är en utmaning. Men samma nivå av insikt och tillgångsprofiler kommer att krävas av alla incidenthanteringsteam för att vara effektiva. Även hans råd att ignorera praktiken av patching kan inte låta dig undvika att behöva bygga en robust, kontextuell inventering (grunden för patching!) som en grund för din ot cyber security program.
så, vad ska vi göra? Först och främst måste vi försöka lappa. Det finns tre saker som ett moget ICS-patchhanteringsprogram måste innehålla för att lyckas:
- realtids, kontextuell inventering
- automatisering av sanering (både patchfiler och ad hoc-skydd)
- identifiering och tillämpning av kompensationskontroller
realtids kontextuell inventering för patchhantering
de flesta ot-miljöer använder skanningsbaserade patchverktyg som WSUS/SCCM som är ganska standard men inte alltför insiktsfulla för att visa oss vilka tillgångar vi har och hur de är konfigurerade. Vad som verkligen behövs är robusta tillgångsprofiler med deras operativa sammanhang inkluderat. Vad menar jag med detta? Tillgång IP, modell, OS, etc. är en mycket kortfattad lista över vad som kan finnas i utrymme för den senaste korrigeringen. Det som är mer värdefullt är det operativa sammanhanget som tillgångskritikalitet för säker verksamhet, tillgångsplats, tillgångsägare etc. för att korrekt kontextualisera vår framväxande risk eftersom inte alla ot-tillgångar skapas lika. Så varför inte först skydda de kritiska systemen eller identifiera lämpliga testsystem (som återspeglar kritiska fältsystem) och strategiskt minska risken?
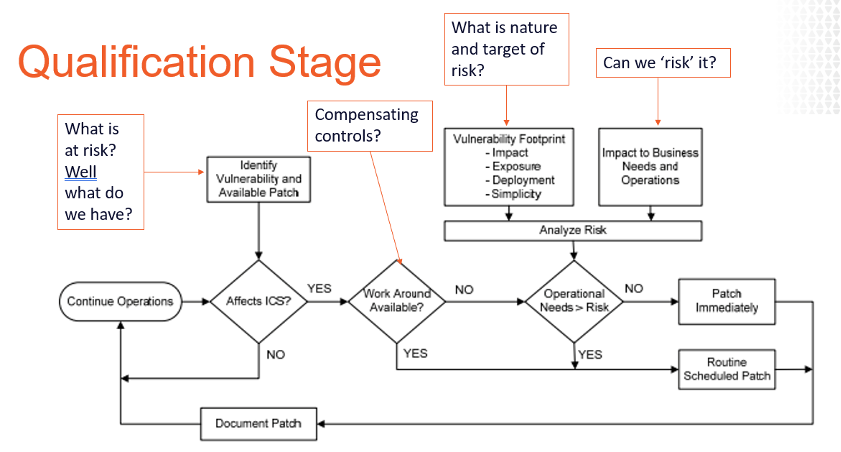
och medan vi bygger dessa tillgångsprofiler måste vi inkludera så mycket information som möjligt om tillgångarna utöver IP, Mac-adress och OS-version. Information som installerad programvara, användare / konto, portar, tjänster, registerinställningar, minst behörighetskontroller, av, vitlista och säkerhetskopieringsstatus etc. Dessa typer av informationskällor ökar vår förmåga att noggrant prioritera och strategisera våra åtgärder när ny risk uppstår. Vill du ha bevis? Ta en titt på det vanliga analysflödet som erbjuds nedan. Var får du data för att svara på frågorna i de olika stadierna? Tribal kunskap? Instinkt? Varför inte data?
automatisera sanering för programvara patching
en annan programvara patching utmaning är utplacering och förberedelse för att distribuera patchar (eller kompensera kontroller) till slutpunkterna. En av de mest tidskrävande uppgifterna i OT-patchhantering är prep-arbetet. Det inkluderar vanligtvis att identifiera målsystem, konfigurera patchdistributionen, felsöka när de misslyckas eller skanna först, trycka på patchen och skanna igen för att bestämma framgång.
men vad händer om, till exempel, nästa gång en risk som BlueKeep dök upp, kan du förinstallera dina filer på målsystemen för att förbereda dig för nästa steg? Du och ditt mindre, mer smidiga ot-säkerhetsteam kan strategiskt planera vilka industriella system du rullade patchuppdateringar till första, andra och tredje baserat på ett antal faktorer i dina robusta tillgångsprofiler som tillgångsplats eller kritik.
ta det ett steg längre, föreställ dig om patchhanteringstekniken inte krävde en skanning först, utan snarare redan hade kartlagt patchen till tillgångar i omfattning och när du installerade dem (antingen på distans för låg risk eller personligen för hög risk), verifierade dessa uppgifter deras framgång och återspeglade framstegen i din globala instrumentpanel?
för alla dina högrisktillgångar som du inte kan eller inte vill patcha just nu kan istället skapa en port, tjänst eller användar-/kontoändring som en Ad hoc-kompensationskontroll. Så för en sårbarhet som BlueKeep kan du inaktivera fjärrskrivbordet eller gästkontot. Detta tillvägagångssätt minskar omedelbart och signifikant nuvarande risk och ger också mer tid att förbereda sig för den eventuella patchen. Detta leder mig till ’falla tillbaka’ åtgärder vad man ska göra när lapp är inte ett alternativ – kompensera kontroller.
vad är kompenserande kontroller?
Kompensationskontroller är helt enkelt åtgärder och säkerhetsinställningar som du kan och bör distribuera i stället för (eller snarare såväl som) patching. De distribueras vanligtvis proaktivt (om möjligt), men kan distribueras i en händelse eller som tillfälliga skyddsåtgärder som att inaktivera fjärrskrivbord medan du patchar för BlueKeep, som jag utökar i fallstudien i slutet av den här bloggen.
identifiera och tillämpa kompensationskontroller I OT-säkerhet
Kompensationskontroller har många former från vitlistning av applikationer och hålla antivirus uppdaterat. Men i det här fallet vill jag fokusera på ICS endpoint management som en viktig stödjande komponent i OT patch management.
Kompensationskontroller kan och bör användas både proaktivt och situationellt. Det skulle inte vara någon överraskning för någon i OT cyber security att upptäcka vilande administratörskonton och onödig eller oanvänd programvara installerad på slutpunkter. Det är inte heller någon hemlighet att principerna för bästa praxis för systemhärdning inte är så universella som vi skulle vilja.
för att verkligen skydda våra OT-system måste vi också härda våra värdefulla ägodelar. En robust tillgångsprofil i realtid gör det möjligt för industriella organisationer att exakt och effektivt rensa ut den lågt hängande frukten (dvs. vilande användare, onödig programvara och systemhärdningsparametrar) för att avsevärt minska attackytan.
i den olyckliga händelsen har vi ett framväxande hot (som BlueKeep) att lägga till tillfälliga kompensationskontroller är genomförbart. En snabb fallstudie för att lyfta fram min poäng:
- BlueKeep sårbarhet släpps.
- det centrala teamet inaktiverar omedelbart fjärrskrivbord på alla fälttillgångar och e-postfältteam som kräver specifika förfrågningar system för system för att fjärrskrivbordstjänsten ska aktiveras under riskperioden.
- Central team laddar patchfiler på alla tillgångar i omfattning-ingen åtgärd, bara förbereda.
- det centrala teamet sammanträder för att bestämma den mest rimliga handlingsplanen genom tillgångskritikalitet, plats, närvaro eller frånvaro av kompensationskontroller (dvs. en kritisk risk för en högeffektstillgång som misslyckades med sin senaste säkerhetskopiering går till toppen av listan. En låg effekt tillgång med vitlistning i kraft och en nyligen bra Full backup kan sannolikt vänta).
- Patching rollout börjar, och framsteg uppdateras live i global rapportering.
- vid behov är OT-tekniker vid konsolen som övervakar patchutplaceringen.
- schemat och kommunikationen för detta behov planeras och prioriteras fullt ut av de data som används av centralteamet.
så här ska OT-patchhantering hanteras. Och fler och fler organisationer börjar sätta denna typ av program på plats.
var proaktiv med kompensationskontroller
ICS patchhantering är svårt, ja, men att bara ge upp försök är inte heller ett bra svar. Med lite framsynthet är det enkelt att tillhandahålla de tre mest kraftfulla verktygen för enklare och effektivare patchning och/eller kompensationskontroller. Insight visar vad du har, hur det är konfigurerat, och hur viktigt det är för dig. Kontext låter dig prioritera (första försöket att lappa – andra låter dig veta hur och var du ska tillämpa kompensationskontroller). Åtgärden låter dig korrigera, skydda, avböja etc. Att bara förlita sig på övervakning är att erkänna att du förväntar dig Brand och att köpa fler rökdetektorer kan minimera skadan. Vilket tillvägagångssätt tror du att din organisation föredrar?