i den här artikeln diskuterar vi den första fasen i kompilatordesign där högnivåinmatningsprogrammet omvandlas till en sekvens av tokens. Denna fas är känd som lexikal analys i Kompilatordesign.
Innehållsförteckning:
- definitioner för lexikal analys
- ett exempel på lexikal analys
- arkitektur lexikal analysator
- reguljära uttryck
- ändliga automater
- förhållandet mellan reguljära uttryck och ändliga automater
- Längsta Match regel
- lexikala fel
- felåterställningssystem
- behov av lexikala analysatorer
- behov av lexikala analysatorer
lexikalisk analys är processen att konvertera en sekvens av tecken från ett källprogram som tas som inmatning till en sekvens av tokens.
en lex är ett program som genererar lexikala analysatorer.
en lexikal analysator/lexer/scanner är ett program som utför lexikal analys.
rollerna för lexikal analysator medför;
- läsning av inmatade tecken från källprogrammet.
- korrelation av felmeddelanden med källprogrammet.
- Striping vita utrymmen och kommentarer från källprogrammet.
- Expansionsmakron om de finns i källprogrammet.
- ange identifierade tokens till symboltabellen.
Lexeme är en instans av en token, det vill säga en sekvens av tecken som ingår i källprogrammet enligt matchningsmönstret för en token.
ett exempel med tanke på uttrycket;
c = A + b * 5
lexemerna och tokens är;
| Lexemes | Tokens |
|---|---|
| C | identifierare |
| = | uppgift symbol |
| a | identifierare |
| + | +(tillägg symbol) |
| B | identifierare |
| * | *(multiplikation symbol) |
| 5 | 5(nummer) |
sekvensen av tokens som produceras av den lexikala analysatorn gör det möjligt för parsern att analysera syntaxen för en programmeringsspråk.
en token är en giltig sekvens av tecken som ges av ett lexem, det behandlas som en enhet i grammatiken i programmeringsspråket.
i ett programmeringsspråk kan detta inkludera;
- nyckelord
- operatorer
- skiljetecken symboler
- konstanter
- identifierare
- siffror
ett mönster är en regel som matchas av en sekvens av tecken(lexemer) som används av token. Det kan definieras med reguljära uttryck eller grammatikregler.
ett exempel på lexikal analys
kod
#include<iostream>// exampleint main(){ int a, b; a = 7; return 0;}Tokens
| Lexemes | Tokens |
|---|---|
| int | nyckelord |
| Huvud | nyckelord |
| ( | operatör |
| ) | operatör |
| { | operatör |
| int | nyckelord |
| a | identifierare |
| , | operatör |
| b | identifierare |
| ; | operatör |
| a | identifierare |
| = | uppgift symbol |
| 10 | 10(nummer) |
| ; | operatör |
| returnera | nyckelord |
| 0 | 0(nummer) |
| ; | operatör |
| } | operatör |
icke Tokens
| Typ | Tokens |
|---|---|
| preprocessordirektivet | #include<iostream> |
| kommentar | / / exempel |
processen med lexisk analys består av två steg.
- skanning – Detta innebär läsning av inmatningsteckenoch borttagning av vita mellanslag och kommentarer.
- Tokenization – Detta är produktionen av tokens som utgång.
arkitektur lexical analyzer
Huvuduppgiften för lexical analyzer är att skanna hela källprogrammet och identifiera tokens en efter en.
Skannrar implementeras för att producera tokens på begäran av tolkaren.

steg:
- ”få nästa token” skickas från parsern till den lexikala analysatorn.
- den lexikala analysatorn skannar ingången tills ”nästa token” finns.
- token returneras till tolken.
reguljära uttryck
vi använder reguljära uttryck för att uttrycka ändliga språk genom att definiera mönster för en ändlig uppsättning symboler.
grammatik definierad av reguljära uttryck kallas vanlig grammatik och språket definierat av vanlig grammatik kallas vanligt språk.
det finns algebraiska regler som följs av reguljära uttryck som används för att manipulera reguljära uttryck till likvärdiga former.
operationer.
unionen av två språk A och B skrivs som
A U B = {s | S är i A eller s är i b}
sammanfogning av två språk A och B skrivs som
AB = {ss | s är i A och s är i b}
kleen-stängningen av ett språk A skrivs som
A* = vilket är noll eller flera förekomster av språk A.
noteringar.
om x och y är reguljära uttryck som anger språk a(x) och B(y) då;
(x) är ett reguljärt uttryck som anger A(x).
Union (x) / (y) är ett reguljärt uttryck som betecknar A(x) B (y).
sammanfogning (x) (y)är ett reguljärt uttryck denting A(x) B (y).
Kleen closure( x)*är ett reguljärt uttryck som betecknar (A(x)) *
företräde och associativitet.
* ’ sammankoppling .’och / (rör) lämnas associativa.
Kleen stängning * har högsta prioritet.
sammanfogning (.) följer i företräde.
(rör) / har LÄGSTA prioritet.
representerar giltiga tokens av ett språk i reguljära uttryck.
X är ett reguljärt uttryck, därför;
- x * representerar noll eller mer förekomst av x.
- x + representerar en eller flera förekomst av x, dvs{x, xx, xxx}
- x? representerar högst en förekomst av x ie {x}
- representerar alla små bokstäver på engelska.
- representerar alla versaler alfabet på engelska.
- representerar alla naturliga tal.
representerar förekomst av symboler med reguljära uttryck
Letter = eller
Digit = eller|0|1|2|3|4|5|6|7|8|9
Sign =
representerar språktoken med reguljära uttryck.
Decimal = (tecken)?(digit)+
Identifier = (letter) (letter | digit)*
finita automater
detta är kombinationen av fem tuplar (Q, Bisexuell, q0, qf, Bisexuell) med fokus på tillstånd och övergångar genom ingångssymboler.
den känner igen mönster genom att ta symbolsträngen som inmatning och ändrar dess tillstånd i enlighet därmed.
den matematiska modellen för ändlig automat består av;
- ändlig uppsättning av stater (Q)
- ändlig uppsättning av inmatningssymboler (Ontario)
- en start tillstånd (q0)
- uppsättning av slutliga tillstånd (qf)
- Övergångsfunktion (Ontario)
finita automater används i lexikal analys för att producera tokens i form av identifierare, nyckelord och konstanter från inmatningsprogrammet.
finita automater matar den reguljära uttryckssträngen och tillståndet ändras för varje bokstav.
om inmatningen behandlas framgångsrikt når automaten det slutliga tillståndet och accepteras annars avvisas det.
konstruktion av ändliga automater
låt L(r) vara ett vanligt språk av vissa ändliga automater F(A).
därför;
- stater: cirklar kommer att representera fa-staterna och deras namn är skrivna inuti cirklarna.
- starttillstånd: Detta är det tillstånd där automaten startar. Det kommer att ha en pil som pekar mot den.
- mellanliggande tillstånd: dessa har två pilar, en pekar på den och en annan pekar ut från mellanliggande tillstånd.
- Slutligt Tillstånd: Automater förväntas vara i slutligt tillstånd när ingångssträngen har analyserats framgångsrikt och representeras av dubbla cirklar annars avvisas ingången. Det kan innehålla ett udda antal pilar som pekar mot det och ett jämnt antal som pekar ut från det, det vill säga
udda pilar = jämna pilar + 1. - övergång: när en önskad symbol finns i ingången kommer övergången från ett tillstånd till ett annat tillstånd att ske. Automaten flyttar antingen till nästa tillstånd eller kvarstår.
en riktad pil visar rörelsen från ett tillstånd till ett annat medan en pil pekar mot destinationstillståndet.
om automaten förblir i samma tillstånd dras en pil som pekar från ett tillstånd till sig själv.
ett exempel; anta att ett 3-siffrigt binärt värde som slutar i 1 accepteras av FA.
sedan FA = {Q (q0, qf), 2,1 (0,1), q0, qf, 2}
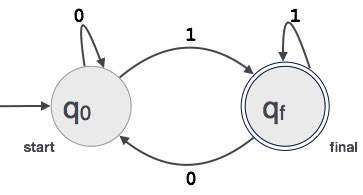
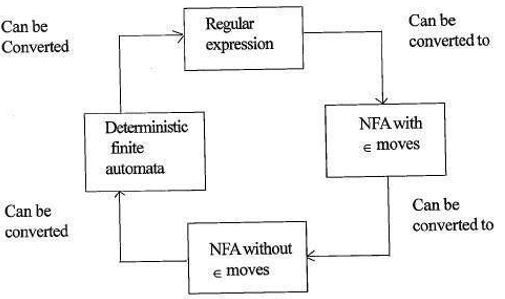
förhållandet mellan reguljära uttryck och ändliga automater
förhållandet mellan reguljära uttryck och ändliga automater är som följer;
figuren nedan visar att det är lätt att konvertera;
- reguljära uttryck för icke-deterministiska ändliga automater (NFA) med rör sig om IX.
- icke-deterministiska finita automater med Macau flyttar till utan Macau flyttar
- icke-deterministiska finita automater utan Macau flyttar till deterministiska finita automater(DFA).
- deterministisk ändlig automat till Reguljärt uttryck.
en Lex accepterar reguljära uttryck som indata och returnerar ett program som simulerar en ändlig automat för att känna igen reguljära uttryck.
därför kommer lex att kombinera strängmönstergenerering (reguljära uttryck som definierar strängarna av intresse för lex) och strängmönsterigenkänning (en ändlig automat som känner igen strängarna av intresse).
Längsta matchningsregel
det anges att lexemet som skannas ska bestämmas baserat på den längsta matchen bland alla tillgängliga tokens.
detta används för att lösa tvetydigheter när man bestämmer nästa token i inmatningsströmmen.
under analys av källkod, kommer den lexikala analysatorn skanna kod bokstav för bokstav och när en operatör, specialsymbol eller blanksteg upptäcks Det avgör om ett ord är klar.
exempel:
int intvalue;när du skannar ovanstående kan analysatorn inte avgöra om’ int ’ är ett sökord int eller prefixet för identifieraren intvalue.
Regelprioritet tillämpas där ett nyckelord prioriteras framför användarinmatning, vilket innebär att analysatorn i ovanstående exempel genererar ett fel.
lexikala fel
ett lexikalt fel uppstår när en teckensekvens inte kan skannas till en giltig token.
dessa fel kan orsakas av felstavning av identifierare, nyckelord eller operatörer.
generellt även om mycket ovanliga lexikala fel orsakas av olagliga tecken i en token.
fel kan vara;
- stavfel.
- införlivande av två tecken.
- olagliga tecken.
- överstiger längden på identifierare eller numeriska konstanter.
- ersättning av ett tecken med ett felaktigt tecken
- borttagning av ett tecken som ska vara närvarande.
felåterställning medför;
- ta bort ett tecken från den återstående ingången
- transponering av två intilliggande tecken
- ta bort ett tecken från den återstående ingången
- infoga saknat tecken i den återstående ingången
- ersätta ett tecken med ett annat tecken.
- ignorerar successiva tecken tills en juridisk token bildas (panikläge återhämtning).
felåterställningssystem
återställning av panikläge.
i detta felåterställningsschema raderas oöverträffade mönster från den återstående ingången tills den lexikala analysatorn kan hitta en välformad token i början av den återstående ingången.
enklare implementering är en fördel för detta tillvägagångssätt.
det har begränsningen att en stor mängd inmatning hoppas över utan att kontrollera några ytterligare fel.
Lokal Korrigering.
när ett fel upptäcks vid en punkt infogning/radering och/eller ersättningsoperationer utförs tills en välformad text uppnås.
analysatorn startas om med den resulterande nya texten som inmatning.
Global korrigering.
det är en förbättrad återställning av panikläge som föredras när lokal korrigering misslyckas.
det har höga krav på tid och utrymme, därför implementeras det inte praktiskt.
behov av lexikala analysatorer
- förbättrad kompilatoreffektivitet – specialiserade buffringstekniker för att läsa tecken påskyndar kompilatorns process.
- enkelhet i kompilatordesign – borttagning av vita mellanslag och kommentarer möjliggör effektiva syntaktiska konstruktioner för syntaxanalysatorn.
- Kompilatorportabilitet – endast skannern kommunicerar med den yttre världen.
- specialisering – specialiserade tekniker kan användas för att förbättra den lexikala analysprocessen
problem med lexikal analys
- Lookahead
med en inmatningssträng läses tecken från vänster till höger en efter en.
för att avgöra om en token är klar eller inte måste vi titta på nästa tecken.
exempel: är ’ = ’en tilldelningsoperator eller det första tecknet i ’= = ’ operator.
Lookahead hoppar över tecken i ingången tills en välformad token hittas, detta visar att blicken framåt inte kan fånga betydande fel förutom enkla fel som olagliga symboler. - tvetydigheter
programmen skrivna med lex accepterar tvetydiga specifikationer och väljer därför den längsta matchningen och när flera uttryck matchar inmatningen föredras antingen den längsta matchningen eller den första regeln bland matchningsreglerna prioriteras. - reserverade nyckelord
vissa språk har reserverade ord som inte är reserverade i andra programmeringsspråk, t.ex. elif är ett reserverat ord i python men inte i C. - kontextberoende
exempel:
med tanke på uttalandet DO 10 l = 10.86 är DO10l en identifierare och DO är inte ett nyckelord.
och med tanke på uttalandet DO 10 l = 10, 86, är DO ett nyckelord
sådana uttalanden skulle kräva betydande blickar framåt för upplösning.
applikationer
- används av kompilatorer skapar uppfyllda binära körbara filer från tolkad kod.
- används av webbläsare för att formatera och visa en webbsida som tolkas HTML, CSS och java script.
med den här artikeln på OpenGenus måste du ha en stark uppfattning om lexikal analys i Kompilatordesign.