med komplexa nätverk som består av moln, hybrid IT, virtualisering, lagringsnätverk och så vidare kan mångfacetterade IT-problem vara svåra att hitta och diagnostisera. När ett problem dyker upp, till exempel en dåligt fungerande applikation eller server, kan utredningen ta betydande tid att hitta kärnproblemet. Problemet kan vara i lagring, nätverksanslutning, användaråtkomst eller en blandning av resurser och konfigurationer.
om du vill undersöka problemet kan du skapa felsökningsprojekt med instrumentpanelen Performance Analysis (perfstack Macau) som visuellt korrelerar historiska data från flera SolarWinds-produkter och entitetstyper i en enda vy.
med Prestandaanalyspaneler kan du göra följande:
- Jämför och analysera flera metriska typer i en enda vy, inklusive status, händelser och statistik.
- Jämför och analysera mätvärden för flera enheter i en enda vy, inklusive noder, gränssnitt, volymer, applikationer och mer.
- korrelera data från hela Orion-plattformen på en enda delad tidslinje.
- visualisera hybriddata för lokalt, moln och allt däremellan.
- dela ett felsökningsprojekt med dina team och experter för att granska historiska data för ett problem.
för VMAN är möjligheterna oändliga för applikationsanalys och hybridmiljöer:
- gå visuellt igenom historiska data för virtuella datorer i din miljö
- verifiera resursallokeringsproblem i hybridmiljöer
- korrelera data för att felsöka nätverkstrafik som skickas och tas emot av virtuella servrar (värdar, kluster, datalager och virtuella datorer), lokala servrar och molninstanser
i följande exempel visas hur du identifierar en grundorsak för en virtuell server VM upplever prestandaproblem. I det här scenariot stötte en virtuell värd på en resurs-och prestandaproblem till den punkt där användarna stöter på långsammare svar och åtkomst. Problemet utlöste en varning, som meddelade din programägare, som eskalerade problemet till system-och nätverksadministratörer.
skapa ett nytt felsökningsprojekt för att undersöka problemet för att jämföra mätvärden för värden och alla relaterade virtuella miljösystem för att spåra trender och spikar i användningen.
-
i Orions webbkonsol väljer du mina instrumentpaneler > hem > prestandaanalys.
detta öppnar instrumentpanelen Performance Analysis, eller PerfStack, för att bygga diagram och diagram med hjälp av mätvärden som dras från övervakade applikationer och servrar i metriska paletten. Varje diagram kan innehålla flera mätvärden för att direkt korrelera data.
-
klicka på Lägg till entiteter i det nya Analysprojektet.
för att komma igång måste du hitta och lägga till VM i nöd. I sökfältet anger du syd För att få fram en lista över virtuella servrar som delar det namnet. Expandera och välj typer eller Status för att filtrera listan om det behövs.
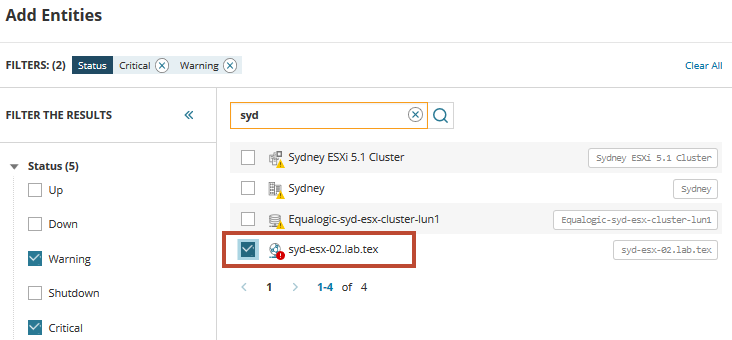
från listan hittar vi den virtuella värden som stöter på problemen och utlöser varningar. Välj värden och Lägg till den i instrumentpanelens metriska palett. Klicka på ikonen relaterade enheter om du vill visa alla relaterade servrar och tjänster för värden.
intresserad av alla associerade noder, applikationer, servrar och mer till den här valda noden? Klicka på ikonen relaterade enheter.
 alla relaterade enheter visas i paletten metriska och ger fler alternativ för mätvärden som kan orsaka problem.
alla relaterade enheter visas i paletten metriska och ger fler alternativ för mätvärden som kan orsaka problem.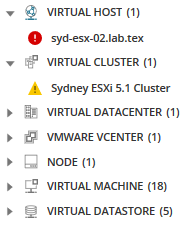
-
Välj syd – värdnoden för att visa och välj mätvärden för att dra och släppa på instrumentpanelen. Du kan dra dem till samma diagram för att jämföra värden mellan mätvärden.
för att börja undersöka, dra en serie mätvärden för värden och klustret, jämföra mätvärden för att hitta spikar eller hög användning. För det här scenariot lägger du till dessa värdmått:
- maximal nätverksanvändning
- maximal Nätverksöverföringshastighet
- maximal Nätverksmottagningshastighet
- virtuella maskiner som kör
för klustret, Lägg till dessa mätvärden:
- Genomsnittlig CPU-belastning
- Genomsnittlig CPU-användning
diagrammen och graferna visas med data och varningar för de senaste 12 timmarna av mätvärden. Du kan utöka datum och tid för att se ytterligare historiska mätvärden under varningens gång.
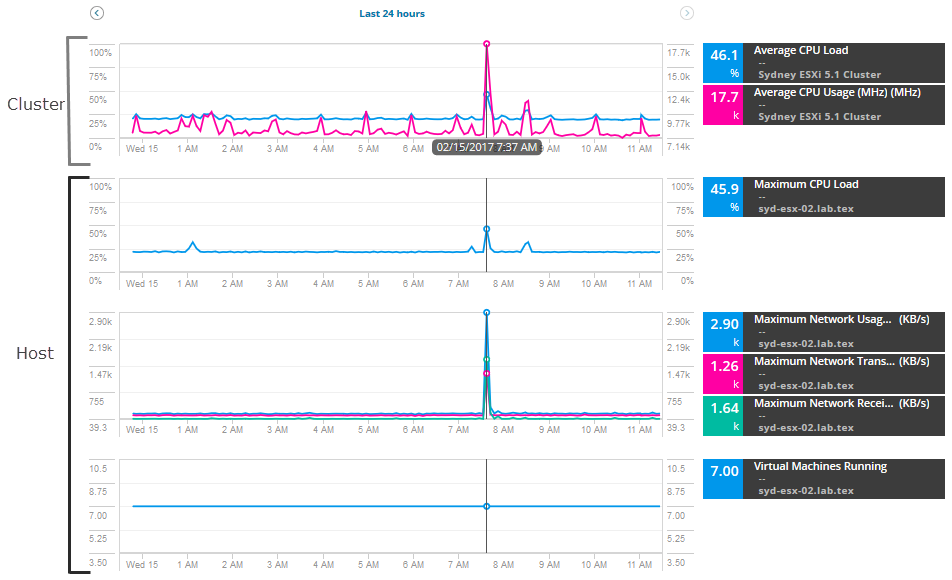
Lägg till användningsmått för virtuella datorer på värden för att jämföra nätverksanvändning och aktivitet.
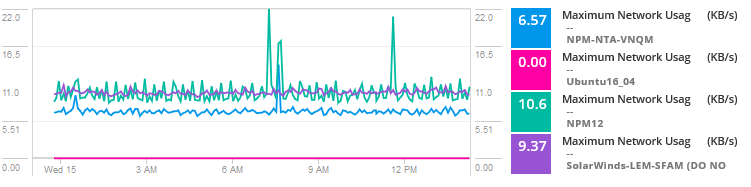
-
analysera data ser problemet ut att vara en högljudd granne för en av de virtuella maskinerna som konsumerar resurser och upplever hög trafik som orsakar flaskhalsar och problem för virtuella datorer som delar värden. I grund och botten förbrukar en annan server, tjänst eller applikation högre bandbredd, disk I/O, CPU och andra resurser som orsakar problem för denna specifika applikation.
denna information ger dina nätverks-och systemadministratörer en riktning för vidare utredning och lösning av latensproblem. För att lösa kan de omfördela resurser eller flytta applikationen med hög konsumtion till en annan plats.
-
klicka på Spara och ge projektet ett namn.
projektet sparar som en instrumentpanel med de valda mätvärdena i det inställda datum-och tidsintervallet.
när den sparas blir webbadressen en delbar länk. Kopiera och dela länken till den sparade instrumentpanelen i biljetter eller e-postmeddelanden som skickas av system-och nätverksadministratörer och produktägaren. De kan komma åt länken för att granska insamlade data och felsöka.
när du har omfördelat resurser och gjort nätverksändringar öppnar du instrumentpanelen igen för att verifiera ändringar och nya användningstrender för undersökta mätvärden.