Låt oss vara smärtsamt ärliga, när ditt företag inte är representerat på Internet är det obefintligt för världen. Dessutom, om du inte har en webbplats, du förlorar en riklig möjlighet att locka fler kvalitet leder. Alla företag från en företagsgigant som Amazon till ett enmansföretag strävar efter att ha en webbplats och innehåll som tilltalar deras publik. Att upptäcka dig och ditt företag online slutar inte där. Bakom webbplatser finns det en hel” osynlig för det mänskliga ögat ” värld där webbsökare spelar en viktig roll.
innehåll
- Vad är en sökrobot och indexering?
- Hur fungerar en webbsökning?
- Hur fungerar en sökrobot?
- vilka är de viktigaste sökrobotar typer?
- Vad är exempel på sökrobotar?
- Vad är en Googlebot?
- Web Crawler vs Web Scraper – Vad är skillnaden?
- Anpassad Webbsökare-Vad Är Det?
- inslagning upp
Vad är en sökrobot och indexering?
låt oss börja med en sökrobot definition:
en sökrobot (även känd som en webb spindel, spindel bot, webb bot, eller helt enkelt en sökrobot) är ett datorprogram som används av en sökmotor för att indexera webbsidor och innehåll över World Wide Web.
indexering är en ganska viktig process eftersom det hjälper användarna att hitta relevanta frågor inom några sekunder. Sökindexeringen kan jämföras med bokindexeringen. Om du till exempel öppnar sista sidorna i en lärobok hittar du ett index med en lista med frågor i alfabetisk ordning och sidor där de nämns i läroboken. Samma princip understryker sökindexet, men istället för sidnumrering visar en sökmotor några länkar där du kan leta efter svar på din förfrågan.
den signifikanta skillnaden mellan Sök-och bokindex är att den förra är dynamisk, därför kan den ändras, och den senare är alltid statisk.
Hur fungerar en webbsökning?
innan du dyker in i detaljerna om hur en sökrobot fungerar, låt oss se hur hela sökprocessen körs innan du får svar på din sökfråga.
om du till exempel skriver ”vad är avståndet mellan jorden och månen” och trycker på enter, kommer en sökmotor att visa dig en lista med relevanta sidor. Vanligtvis, det tar tre stora steg för att ge användarna den information som krävs för sina sökningar:
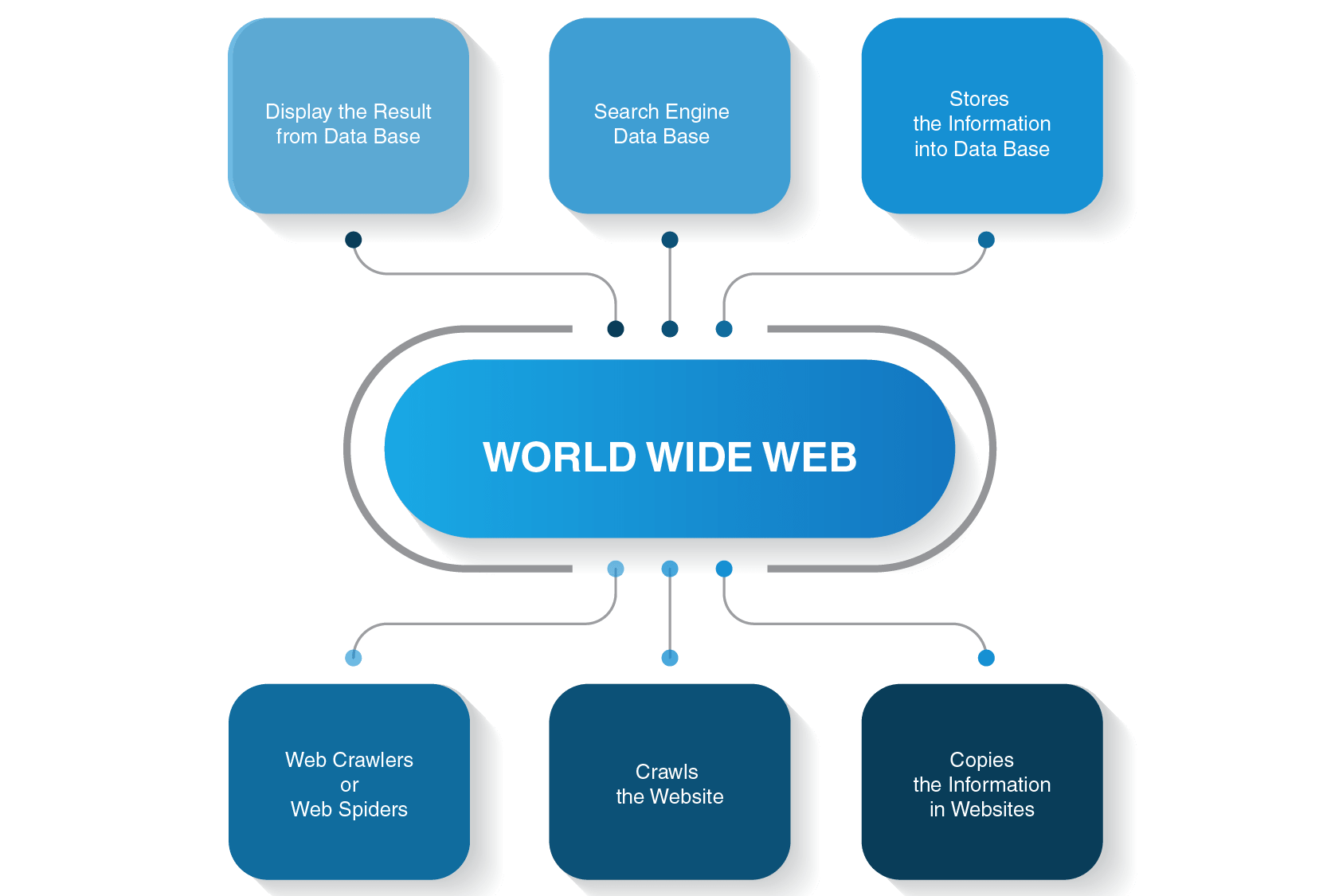
- en webbspindel kryper innehåll på webbplatser
- det bygger ett index för en sökmotor
- sökalgoritmer rankar de mest relevanta sidorna
man måste också komma ihåg två viktiga punkter:
- du behöver inte göra dina sökningar i realtid eftersom det är omöjligt
det finns gott om webbplatser på World Wide Web, och många fler skapas även nu när du läser den här artikeln. Det är därför det kan ta eoner för en sökmotor att komma med en lista över sidor som skulle vara relevanta för din fråga. För att påskynda sökprocessen genomsöker en sökmotor sidorna innan de visas för världen.
- du gör inte dina sökningar på World Wide Web
faktum är att du inte utför sökningar på World Wide Web utan i ett sökindex och det är när en webbrobot går in på slagfältet.
Kontakta Oss Nu!
Hur fungerar en sökrobot?
det finns många sökmotorer där ute − Google, Bing, Yahoo!, DuckDuckGo, Baidu, Yandex och många andra. Var och en av dem använder sin spindelbot för att indexera sidor.
de startar sin genomsökningsprocess från de mest populära webbplatserna. Deras primära syfte med webbrots är att förmedla kärnan i vad varje sidinnehåll handlar om. Således söker webbspindlar ord på dessa sidor och bygger sedan en praktisk lista över dessa ord som kommer att användas av en sökmotor nästa gång när du vill hitta information om din fråga.
alla sidor på Internet är anslutna med hyperlänkar, så webbplats spindlar kan upptäcka dessa länkar och följa dem till nästa sidor. Webbrobotar slutar bara när de hittar allt innehåll och anslutna webbplatser. Sedan skickar de den inspelade informationen ett sökindex som lagras på servrar runt om i världen. Hela processen liknar en verklig spindelväv där allt är sammanflätat.
genomsökning slutar inte omedelbart när sidor har indexerats. Sökmotorer använder regelbundet webbspindlar för att se om några ändringar har gjorts på sidor. Om det finns en förändring uppdateras indexet för en sökmotor i enlighet därmed.
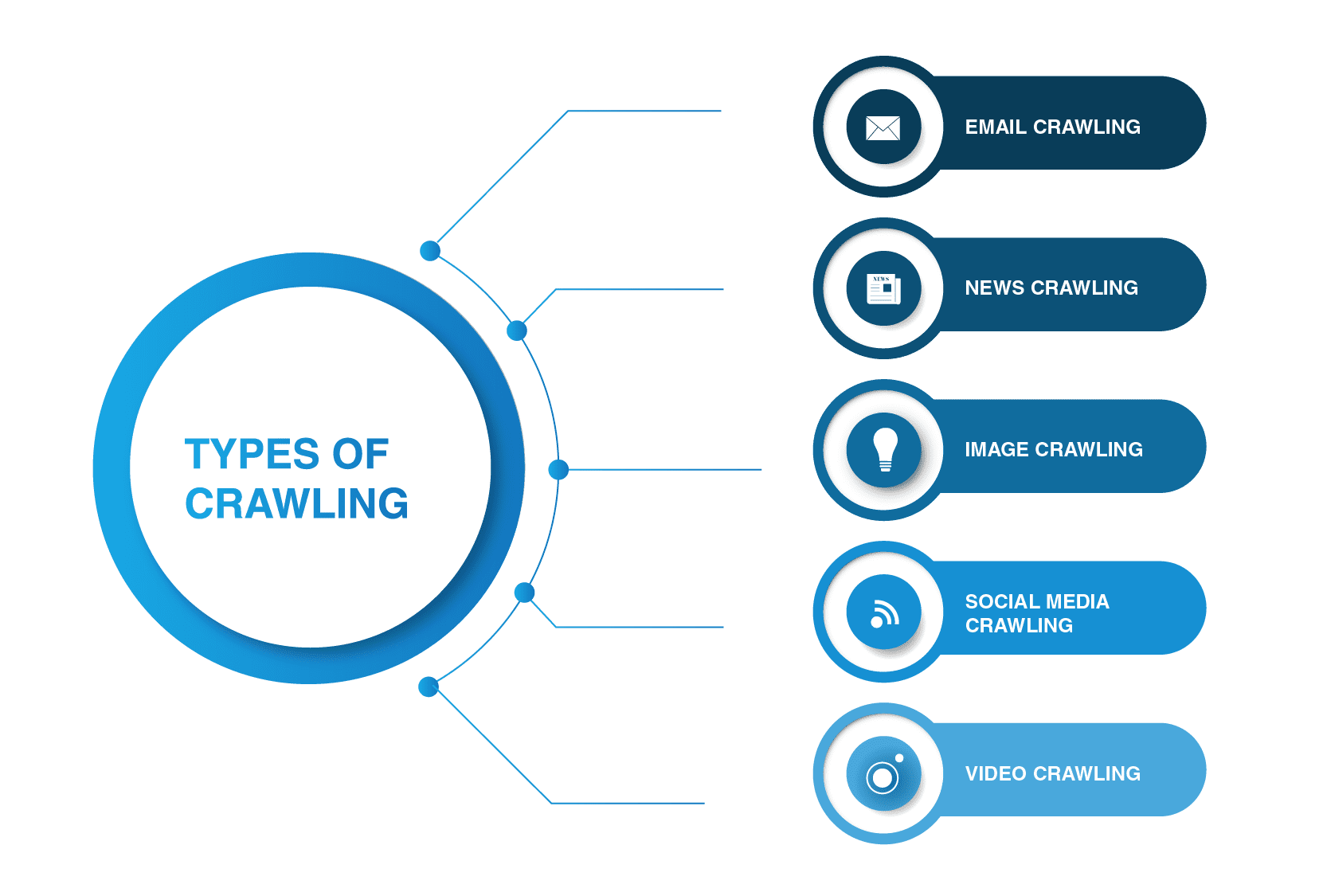
vilka är de viktigaste sökrobotar typer?
webbsökare är inte begränsade till sökmotorspindlar. Det finns andra typer av webbsökning där ute.
- genomsökning av e-post
genomsökning av e-post är särskilt användbart vid utgående leadgenerering eftersom denna typ av genomsökning hjälper till att extrahera e-postadresser. Det är värt att nämna att denna typ av genomsökning är olaglig eftersom den bryter mot personlig integritet och inte kan användas utan användarbehörighet.
- nyheter genomsökning
med tillkomsten av Internet, nyheter från hela världen kan spridas snabbt runt på webben, och att extrahera data från olika webbplatser kan vara ganska ohanterliga.
det finns många webbsökare som klarar av den här uppgiften. Sådana sökrobotar kan hämta data från nytt, gammalt och arkiverat nyhetsinnehåll och läsa RSS-flöden. De extraherar följande information: Datum för publicering, författarens namn, rubriker, huvudpunkter, huvudtext och publiceringsspråk.
- bildgenomsökning
som namnet antyder tillämpas denna typ av genomsökning på bilder. Internet är fullt av visuella representationer. Således hjälper sådana bots människor att hitta relevanta bilder i en mängd bilder på webben.
- genomsökning av sociala medier
genomsökning av sociala medier är en ganska intressant fråga eftersom inte alla sociala medieplattformar tillåter att genomsökas. Du bör också komma ihåg att en sådan typ av genomsökning kan vara olaglig om den bryter mot datasekretessens efterlevnad. Fortfarande, det finns många sociala medier plattform leverantörer som är bra med genomsökning. Pinterest och Twitter tillåter till exempel spindelbots att skanna sina sidor om de inte är användarkänsliga och inte avslöjar någon personlig information. Facebook, LinkedIn är strikta i denna fråga.
- genomsökning av Video
ibland är det mycket lättare att titta på en video än att läsa mycket innehåll. Om du väljer att bädda in Youtube, Soundcloud, Vimeo eller något annat videoinnehåll på din webbplats kan det indexeras av vissa webbsökare.
Vad är exempel på web Crawlers?
många sökmotorer använder sina egna sökrobotar. Till exempel är de vanligaste exemplen på sökrobotar:
- Alexabot
Amazon Web crawler Alexabot används för webbinnehåll identifiering och bakåtlänk upptäckt. Om du vill hålla en del av din information privat kan du utesluta Alexabot från att genomsöka din webbplats.
- Yahoo! Slurp Bot
Yahoo sökrobot Yahoo! Slurp Bot används för indexering och skrapning av webbsidor för att förbättra personligt innehåll för användare.
- Bingbot
Bingbot är en av de mest populära webbspindlarna som drivs av Microsoft. Det hjälper en sökmotor, Bing, att skapa det mest relevanta indexet för sina användare.
- DuckDuck Bot
DuckDuckGo är förmodligen en av de mest populära sökmotorerna som inte spårar din historia och följer dig på vilka webbplatser du besöker. Dess DuckDuck Bot sökrobot hjälper till att hitta de mest relevanta och bästa resultat som kommer att tillfredsställa en användares behov.
- Facebook extern träff
Facebook har också sin sökrobot. Till exempel, när en Facebook-användare vill dela en länk till en extern innehållssida med en annan person, skrapar sökroboten HTML-koden på sidan och ger dem båda titeln, en tagg av videon eller bilder av innehållet.
- Baiduspider
denna sökrobot drivs av den dominerande kinesiska sökmotorn − Baidu. Som alla andra bot, reser den genom en mängd olika webbsidor och letar efter hyperlänkar för att indexera innehåll för motorn.
- Exabot
franska sökmotorn Exalead använder Exabot för indexering av innehåll så att det kan ingå i motorns index.
- Yandex Bot
denna bot tillhör den största ryska sökmotorn Yandex. Du kan blockera det från att indexera ditt innehåll om du inte planerar att göra affärer där.
Vad är en Googlebot?
som nämnts ovan har nästan alla sökmotorer sina spindelbots, och Google är inget undantag. Googlebot är en Google-sökrobot som drivs av den mest populära sökmotorn i världen, som används för indexering av innehåll för denna motor.
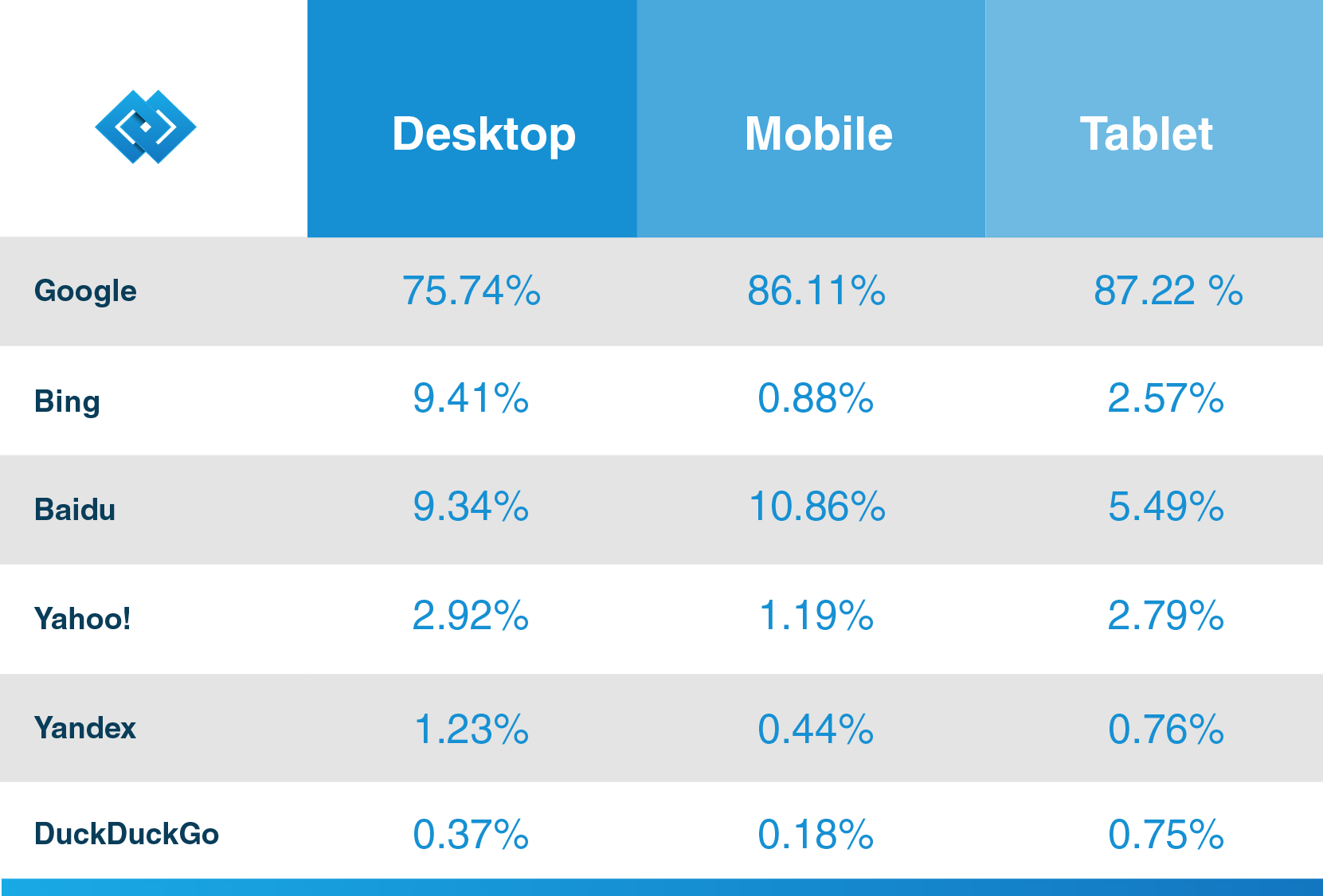
som Hubspot, en känd CRM-leverantör, säger i sin blogg, har Google mer än 92.42% av sökmarknadsandelen och dess mobiltrafik är över 86%. Så om du vill få ut det mesta av sökmotorn för ditt företag, ta reda på mer information på dess webbspindel så att dina framtida kunder kan upptäcka ditt innehåll tack vare Google.
Googlebot kan vara av två typer — en stationär bot och en mobilappsökare som simulerar användaren på dessa enheter. Den använder samma genomsökningsprincip som alla andra webbspindlar, som att följa länkar och skanna innehåll tillgängligt på webbplatser. Processen är också helt automatiserad och kan vara återkommande, vilket innebär att den kan besöka samma sida flera gånger med jämna mellanrum.
om du är redo att publicera innehåll tar det dagar för Googles sökrobot att indexera det. Om du är ägare till webbplatsen kan du påskynda processen manuellt genom att skicka in en indexeringsförfrågan via Hämta som Google eller uppdatera webbplatsens webbplatskarta.
du kan också använda robotar.txt (eller Robots Exclusion Protocol) för att ”ge instruktioner” till en spindelbot, inklusive Googlebot. Där kan du tillåta eller förbjuda sökrobotar att besöka vissa sidor på din webbplats. Tänk dock på att den här filen lätt kan nås av tredje part. De kommer att se vilka delar av webbplatsen du begränsade från indexering.
Web Crawler vs Web Scraper – Vad är skillnaden?
många människor använder sökrobotar och webbskrapor omväxlande. Ändå finns det en väsentlig skillnad mellan dessa två. Om den förstnämnda mest handlar om metadata av innehåll, som taggar, rubriker, nyckelord och andra saker, ”stjäl” det senare innehållet från en webbplats som ska publiceras på någon annans online-resurs.
en webbskrapa ”jagar” också för specifika data. Om du till exempel behöver extrahera information från en webbplats där det finns information som aktiemarknadstrender, bitcoinpriser eller någon annan, kan du hämta data från dessa webbplatser med hjälp av en webbskrapningsbot.
om du genomsöker din webbplats och vill skicka in ditt innehåll för indexering eller har för avsikt att andra ska hitta det — är det helt lagligt, annars är skrapning av andras och företags webbplatser mot lagen.
Anpassad Webbsökare-Vad Är Det?
en anpassad webbrobot är en bot som används för att täcka ett specifikt behov. Du kan bygga din spindelbot för att täcka alla uppgifter som behöver lösas. Om du till exempel är en entreprenör eller marknadsförare eller någon annan professionell som hanterar innehåll kan du göra det lättare för dina kunder och användare att hitta den information de vill ha på din webbplats. Du kan skapa en mängd olika webbrots för olika ändamål.
om du inte har någon praktisk erfarenhet av att bygga din anpassade webbsökrobot kan du alltid kontakta en mjukvaruutvecklingsleverantör som kan hjälpa dig med det.
inslagning upp
webbplats sökrobotar är en integrerad del av någon större sökmotor som används för indexering och upptäcka innehåll. Många sökmotorföretag har sina bots, till exempel drivs Googlebot av företagsjätten Google. Bortsett från det finns det flera typer av genomsökning som används för att täcka specifika behov, som video, bild eller genomsökning av sociala medier.
med hänsyn till vad spider bots kan göra är de mycket viktiga och fördelaktiga för ditt företag eftersom webbsökare avslöjar dig och ditt företag för världen och kan ta in nya användare och kunder.
om du vill skapa en anpassad webbsökrobot, kontakta LITSLINK, en erfaren leverantör av webbutvecklingstjänster, för mer information.