tässä artikkelissa käsitellään kääntäjän suunnittelun ensimmäistä vaihetta, jossa korkean tason tuloohjelma muunnetaan polettisarjaksi. Tätä vaihetta kutsutaan kääntäjän suunnittelussa Leksikaaliseksi analyysiksi.
sisällysluettelo:
- leksikaalisen analyysin määritelmät
- leksikaalisen analyysin esimerkki
- leksikaalisen analysaattorin Arkkitehtuuri
- Säännölliset lausekkeet
- finiittinen Automata
- säännöllisten lausekkeiden ja finiittisen Automatan välinen suhde
- pisin täsmäyssääntö
- leksikaaliset virheet
- error recovery schemes
- need for lexical Analyzers
- need for lexical Analyzers
lexical analysis on prosessi, jossa muunnetaan sarja merkkejä Lähdeohjelmasta, joka otetaan syötteenä jonoon Tokens.
a lex on ohjelma, joka luo leksikaalisia analysaattoreita.
lexical analyzer/lexer/scanner on ohjelma, joka suorittaa lexical analysis.
leksikaalisen analysaattorin tehtäviin kuuluu;
- Lähdeohjelman syöttömerkkien lukeminen.
- virheilmoitusten korrelaatio lähdeohjelman kanssa.
- raidoittavat valkoiset välilyönnit ja lähdeohjelman Kommentit.
- Laajennusmakrot, jos ne löytyvät source-ohjelmasta.
- merkitään tunnistetut poletit symbolitaulukkoon.
Lexeme on Tokenin ilmentymä, toisin sanoen lähdeohjelmaan sisältyvä merkkien sarja Tokenin vastaavuuskaavan mukaan.
esimerkki lausekkeesta;
c = A + b * 5
lekseemit ja poletit ovat;
| Lekseemit | poletit |
|---|---|
| c | tunniste |
| = | tehtävämerkki |
| a | tunniste |
| + | +(lisäyssymboli) |
| b | tunniste |
| * | *(kertolaskusymboli) |
| 5 | 5(numero) |
leksikaalisen analysaattorin tuottaman polettisarjan avulla jäsennin voi analysoida syntaksin ohjelmointikieli.
token on lekseemin antama kelvollinen merkkisarja, sitä käsitellään ohjelmointikielen kieliopissa yksikkönä.
ohjelmointikielessä tämä voi sisältää;
- avainsanat
- operaattorit
- välimerkit
- vakiot
- tunnisteet
- numerot
kuvio on sääntö, jota vastaa merkin käyttämä sarja(lexemes). Se voidaan määritellä säännöllisillä lausekkeilla tai kielioppisäännöillä.
esimerkki Leksikaalisesta analyysistä
koodi
#include<iostream>// exampleint main(){ int a, b; a = 7; return 0;}Tokens
| Lekseemit | poletit |
|---|---|
| int | hakusana |
| main | avainsana |
| ( | operaattori |
| ) | operaattori |
| { | operaattori |
| int | hakusana |
| a | tunniste |
| , | operaattori |
| tunniste | |
| ; | operaattori |
| a | tunniste |
| = | tehtävämerkki |
| 10 | 10(numero) |
| ; | operaattori |
| paluu | avainsana |
| 0 | 0(numero) |
| ; | toimija |
| } | operaattori |
Ei Sanakkeita
| Tyyppi | poletit |
|---|---|
| esikäsittelijädirektiivi | #include<iostream> |
| kommentti | / / esimerkki |
leksikaalisessa analyysissa on kaksi vaihetta.
- skannaus-tämä edellyttää syöttömerkkien lukemista ja valkoisten välilyöntien ja kommenttien poistamista.
- Tokenointi – tämä on tokenien tuottamista tuotoksena.
leksikaalisen analysaattorin Arkkitehtuuri
leksikaalisen analysaattorin päätehtävä on skannata koko lähdeohjelma ja tunnistaa tokeneita yksi kerrallaan.
Skannerit on toteutettu tuottamaan poletteja jäsentäjän pyynnöstä.

vaiheet:
- ”get next token” lähetetään jäsentimestä leksikaaliseen analysaattoriin.
- leksikaalinen analysaattori skannaa tulon, kunnes ”seuraava token” on paikannettu.
- merkki palautetaan jäsentäjälle.
Säännölliset lausekkeet
käytämme säännöllisiä lausekkeita ilmaisemaan äärellisiä kieliä määrittelemällä kuvioita äärelliselle symbolijoukolle.
säännöllisten lausekkeiden määrittelemää kielioppia kutsutaan säännölliseksi kielioppiksi ja säännöllisen kielioopin määrittelemää kieltä säännölliseksi kieleksi.
on olemassa säännöllisten lausekkeiden noudattamia algebrallisia sääntöjä, joita käytetään manipuloimaan säännöllisiä lausekkeita vastaaviin muotoihin.
operaatiot.
kahden kielen liitto A ja B kirjoitetaan kuten
a U b = {s | s On A: ssa tai s on B: ssä
kahden kielen Yhtymä A ja B kirjoitetaan kuten
AB = {SS | s On A: ssa ja s on B: ssä
kleen sulkeuma a kirjoitetaan muodossa
a* = joka on nolla tai useampia esiintymiä kielen A: ssa.
merkinnät.
jos X ja y ovat säännöllisiä lausekkeita, jotka ilmaisevat kieliä A(x) ja B(y), niin
(x) on säännöllinen lauseke, joka ilmaisee A(x).
unioni (x)|(y) on säännöllinen lauseke, joka ilmaisee A(x) B(y).
Concatenation (x) (y)on säännöllinen lauseke, joka dentoi A(x) B (y).
Kleenin sulkeminen (x)* on säännöllinen lauseke, joka ilmaisee (A (x))*
ensisijaisuutta ja assosiatiivisuutta.
* ” concatenation .”ja / (pipe) ovat assosiatiivisia.
Kleen sulkeminen * on korkein sijoitus.
Concatenation (.) seuraa arvojärjestyksessä.
(putki) | on alin ennakkosuosikki.
, jotka edustavat kielen kelvollisia tokeneita säännöllisissä lausekkeissa.
X on säännöllinen lauseke, joten;
- x* tarkoittaa nollaa tai useampaa X: n esiintymistä.
- x+ tarkoittaa yhtä tai useampaa X: n esiintymistä, ie{x, xx, xxx}
- x? edustaa korkeintaan yhtä muotoa X ie {x}
- edustaen kaikkia englannin kielen pienaakkosia.
- edustavat kaikkia englanninkielisiä suuraakkosia.
- edustavat kaikkia luonnollisia lukuja.
, joka edustaa säännöllisiä lausekkeita käyttävien symbolien esiintymistä
Letter = tai
Digit = tai|0|1|2|3|4|5|6|7|8|9
Sign =
edustaa säännöllisiä lausekkeita käyttäviä kielimerkkejä.
desimaali = (merkki)?(numero) +
Identifier = (kirjain) (kirjain | numero)*
äärellinen Automata
tämä on yhdistelmä viidestä tuplasta (Q, Σ, q0, qf, δ), jotka keskittyvät olotiloihin ja siirtymiin syöttösymbolien avulla.
se tunnistaa kuviot ottamalla symbolijonon syötteeksi ja muuttaa tilaansa sen mukaisesti.
äärellisen automaatin matemaattinen malli koostuu;
- äärellinen tilajoukko(Q)
- äärellinen tulosymbolien joukko(Σ)
- yksi aloitustila(q0)
- lopputilojen joukko(QF)
- Siirtymäfunktio (δ)
äärellistä automataa käytetään leksikaalisessa analyysissä tuottamaan poletteja tunnisteiden, avainsanojen ja vakioiden muodossa syöteohjelmasta.
äärellinen automata syöttää säännöllisen lausekkeen merkkijonoa ja tila vaihtuu jokaisen kirjaimiston kohdalla.
jos syöte käsitellään onnistuneesti, Automaatti saavuttaa lopullisen tilan ja hyväksytään muuten se hylätään.
äärellisen Automatan konstruktio
olkoon L(r) jonkin äärellisen Automatan F(A) säännöllinen kieli.
siksi;
- valtiot: ympyrät edustavat FA: n osavaltioita ja niiden nimet kirjoitetaan ympyröiden sisään.
- Aloitustila: tämä on tila, jossa Automaatti alkaa. Siinä on nuoli, joka osoittaa sitä kohti.
- välitilat: näissä on kaksi nuolta, joista toinen osoittaa siihen ja toinen välitiloista.
- Lopullinen Tila: Automatan oletetaan olevan lopullisessa tilassa, kun syöttömerkkijono on jäsennetty onnistuneesti ja esitetty kaksoisympyröillä, muuten tulo hylätään. Siinä voi olla pariton määrä sitä kohti osoittavia nuolia ja parillinen siitä osoittava luku, eli
parittomia nuolia = parillisia nuolia + 1. - Siirtymä: kun syötteestä löytyy haluttu symboli, tapahtuu siirtyminen tilasta toiseen. Automata joko siirtyy seuraavaan tilaan tai jatkuu.
suunnattu nuoli näyttää liikkeen tilasta toiseen nuolen osoittaessa kohti kohdetilaa.
jos automata pysyy samassa tilassa, piirretään tilasta itseensä osoittava nuoli.
esimerkki; Oletetaan, että FA hyväksyy 3-numeroisen binääriarvon, joka päättyy 1: een.
silloin FA = {Q (q0, qf), Σ(0,1), q0, qf, δ}
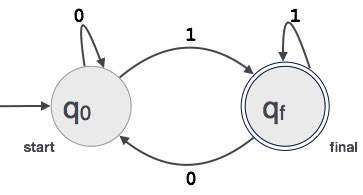
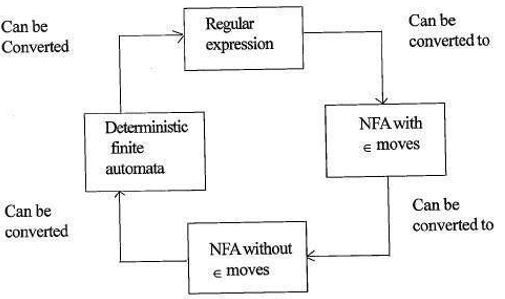
säännöllisten lausekkeiden ja äärellisen Automatan suhde
säännöllisen lausekkeen ja äärellisen Automatan suhde on seuraava;
alla oleva luku osoittaa, että se on helppo muuntaa;
- Säännölliset lausekkeet Ei-deterministiseen äärelliseen automataan (NFA) ∈ – siirroilla.
- ei-deterministinen äärellinen automata, jossa ∈ siirtyy ilman ∈ liikkuu
- ei-deterministinen äärellinen automata ilman ∈ siirtyy deterministiseen äärelliseen Automataan(DFA).
- deterministinen äärellinen Automatia säännölliseen lausekkeeseen.
Lex hyväksyy säännölliset lausekkeet syötteenä ja palauttaa ohjelman, joka simuloi äärellistä automaattia tunnistamaan säännölliset lausekkeet.
tämän vuoksi lex yhdistää merkkijonokuvion generoinnin (säännölliset lausekkeet, jotka määrittelevät lexille kiinnostavat merkkijonot) ja merkkijonokuvion tunnistamisen (äärellinen automaatti, joka tunnistaa kiinnostavat merkkijonot).
pisin Ottelusääntö
sen mukaan skannattu lekseemi tulee määrittää kaikkien käytettävissä olevien polettien pisimmän vastaavuuden perusteella.
Tätä käytetään epäselvyyksien selvittämiseen päätettäessä seuraavaa tokenia tulovirrassa.
lähdekoodia analysoitaessa sanastoanalysaattori skannaa koodin kirjain kirjaimelta ja kun operaattori, erikoissymboli tai välilyönti havaitaan, se päättää, onko sana kokonainen.
esimerkki:
int intvalue;analysaattori ei yllä olevaa skannatessaan pysty määrittämään, onko ”int” avainsana int vai tunnisteen intvalue etuliite.
sovelletaan sääntöä, jossa avainsanalle annetaan etusija käyttäjän syötteeseen nähden, mikä tarkoittaa yllä olevassa esimerkissä, että analysaattori tuottaa virheen.
Sanastovirheet
sanastollinen virhe syntyy, kun merkkisarjaa ei voida skannata kelvolliseksi tokeniksi.
nämä virheet voivat johtua tunnisteiden, avainsanojen tai operaattoreiden kirjoitusvirheistä.
yleensä, vaikkakin hyvin harvinaisia sanastovirheitä aiheuttavat Tokenin laittomat merkit.
virheitä voi olla;
- kirjoitusvirhe.
- kaksi merkkiä.
- laittomat merkit.
- tunnisteen tai numeerisen vakion pituus ylittyy.
- merkin korvaaminen virheellisellä merkillä
- siinä olevan merkin poistaminen.
Virheenpalautus merkitsee;
- poistetaan yksi merkki jäljelle jääneestä syötteestä
- siirtämällä kaksi vierekkäistä merkkiä
- poistamalla yksi merkki jäljellä olevasta syötteestä
- lisäämällä puuttuva merkki jäljellä olevaan syötteeseen
- korvaamalla merkki toisella merkillä.
- sivuutetaan peräkkäiset merkit, kunnes muodostetaan laillinen poletti(panic mode recovery).
virheiden palautusjärjestelmät
paniikkitilan palautus.
tässä virheenkorjausohjelmassa jäljettömät kuviot poistetaan jäljellä olevasta tulosta, kunnes leksikaalinen analysaattori löytää hyvin muodostuneen Tokenin jäljellä olevan tulon alusta.
täytäntöönpanon helpottaminen on tämän lähestymistavan etu.
siinä on rajoitus, että suuri määrä syötettä ohitetaan tarkistamatta ylimääräisiä virheitä.
Paikallinen Korjaus.
kun pisteessä havaitaan virhe lisäys/poisto ja / tai korvaava toimenpide suoritetaan, kunnes teksti on muodostettu hyvin.
analysaattori käynnistetään uudelleen tuloksena olevan uuden tekstin ollessa syötettynä.
Kokonaiskorjaus.
se on parannettu paniikkitilan palautus, jota suositaan, kun paikallinen korjaus epäonnistuu.
sillä on korkeat aika-ja tilavaatimukset, joten sitä ei toteuteta käytännössä.
leksikaalisten analysaattoreiden tarve
- parempi kääntäjän hyötysuhde – erikoistuneet puskurointitekniikat merkkien lukemiseen nopeuttavat kääntäjän prosessia.
- kääntäjän suunnittelun yksinkertaisuus – valkoisten välilyöntien ja kommenttien poistaminen mahdollistaa tehokkaat syntaktiset konstruktiot syntaksianalysaattorille.
- kääntäjän siirrettävyys – vain skanneri kommunikoi ulkoisen maailman kanssa.
- erikoistuneita tekniikoita voidaan käyttää leksikaalisen analyysiprosessin parantamiseen
ongelmat, joissa leksikaalinen analyysi
- Lookahead
kun otetaan huomioon syöttömerkkijono, merkit luetaan vasemmalta oikealle yksi kerrallaan.
päättääksemme, onko token valmis vai ei, meidän on katsottava seuraavaa merkkiä.
esimerkki: on ” = ”tehtäväoperaattori tai” = ” – operaattorin ensimmäinen merkki.
Lookahead ohittaa merkkejä syötteessä, kunnes hyvin muodostettu token löytyy, tämä osoittaa, että look ahead ei voi napata merkittäviä virheitä lukuun ottamatta yksinkertaisia virheitä, kuten laittomia symboleita. - epäselvyydet
Lexin kanssa kirjoitetut ohjelmat hyväksyvät monitulkintaiset määritykset, joten valitaan pisin täsmäys ja kun useat lausekkeet täsmäävät syötteeseen, valitaan joko pisin täsmäys tai priorisoidaan ensimmäinen sääntö vastaavuussääntöjen joukossa. - varatut avainsanat
eräissä kielissä on varattuja sanoja, joita ei ole varattu muissa ohjelmointikielissä, esim.Elif on varattu sana Pythonissa mutta ei C: ssä. - Kontekstiriippuvuus
esimerkki:
kun otetaan huomioon lauseke DO 10 l = 10.86, DO10l on tunniste eikä DO ole avainsana.
ja kun otetaan huomioon lausuma DO 10 l = 10, 86, DO on avainsana
tällaiset lausumat vaatisivat merkittävää harkintaa ratkaisun löytämiseksi.
kääntäjien käyttämät sovellukset
- luovat yhteensopivat binääriset suoritustiedostot jäsennetystä koodista.
- Web-selaimet käyttävät HTML -, CSS-ja java-skriptiä jäsentävän web-sivun muotoiluun ja näyttämiseen.
tämän opengenuksen artikkelin myötä sinulla täytyy olla vahva käsitys Sanastoanalyysistä kääntäjän suunnittelussa.