olkaamme tuskallisen rehellisiä, kun yrityksesi ei ole edustettuna Internetissä, se on olematonta maailmalle. Lisäksi, jos sinulla ei ole verkkosivuilla, olet menettämässä runsaasti mahdollisuus houkutella enemmän laatua johtaa. Mikä tahansa liiketoiminta Amazonin kaltaisesta yritysjätistä yhden hengen yritykseen pyrkii saamaan verkkosivun ja sisällön, joka vetoaa yleisöihinsä. Löytää sinut ja yrityksesi verkossa ei lopu tähän. Verkkosivustojen takana on kokonainen ”ihmissilmälle näkymätön” maailma, jossa verkkoselaimilla on tärkeä rooli.
Sisällysluettelo
- mikä on Web Crawler ja indeksointi?
- miten verkkohaku toimii?
- miten Web Crawler toimii?
- mitkä ovat tärkeimmät Web-Telaketjutyypit?
- mitkä ovat esimerkkejä Verkkohyökkääjistä?
- mikä on Googlebot?
- Web Crawler vs Web Scraper-mikä on ero?
- Custom Web Crawler-What Is It?
- Kääriytyminen
mikä on Web Crawler ja indeksointi?
aloitetaan web crawlerin määritelmällä:
web crawler (tunnetaan myös nimellä web spider, spider bot, web bot, tai yksinkertaisesti crawler) on tietokoneohjelma, jota käytetään hakukoneen indeksoida web-sivuja ja sisältöä kaikkialla World Wide Web.
indeksointi on varsin olennainen prosessi, sillä se auttaa käyttäjiä löytämään asiaankuuluvat kyselyt muutamassa sekunnissa. Hakuindeksointia voidaan verrata kirjan indeksointiin. Jos esimerkiksi avaat oppikirjan viimeiset sivut, löydät hakemiston, jossa on luettelo hakusanoista aakkosjärjestyksessä ja sivut, joissa ne on mainittu oppikirjassa. Sama periaate alleviivaa hakuindeksiä, mutta sivunumeroinnin sijaan hakukone näyttää sinulle linkkejä, joista voit etsiä vastauksia kysymykseesi.
hakuindeksien ja kirjaindeksien merkittävä ero on se, että edellinen on dynaaminen, joten sitä voidaan muuttaa ja jälkimmäinen aina staattinen.
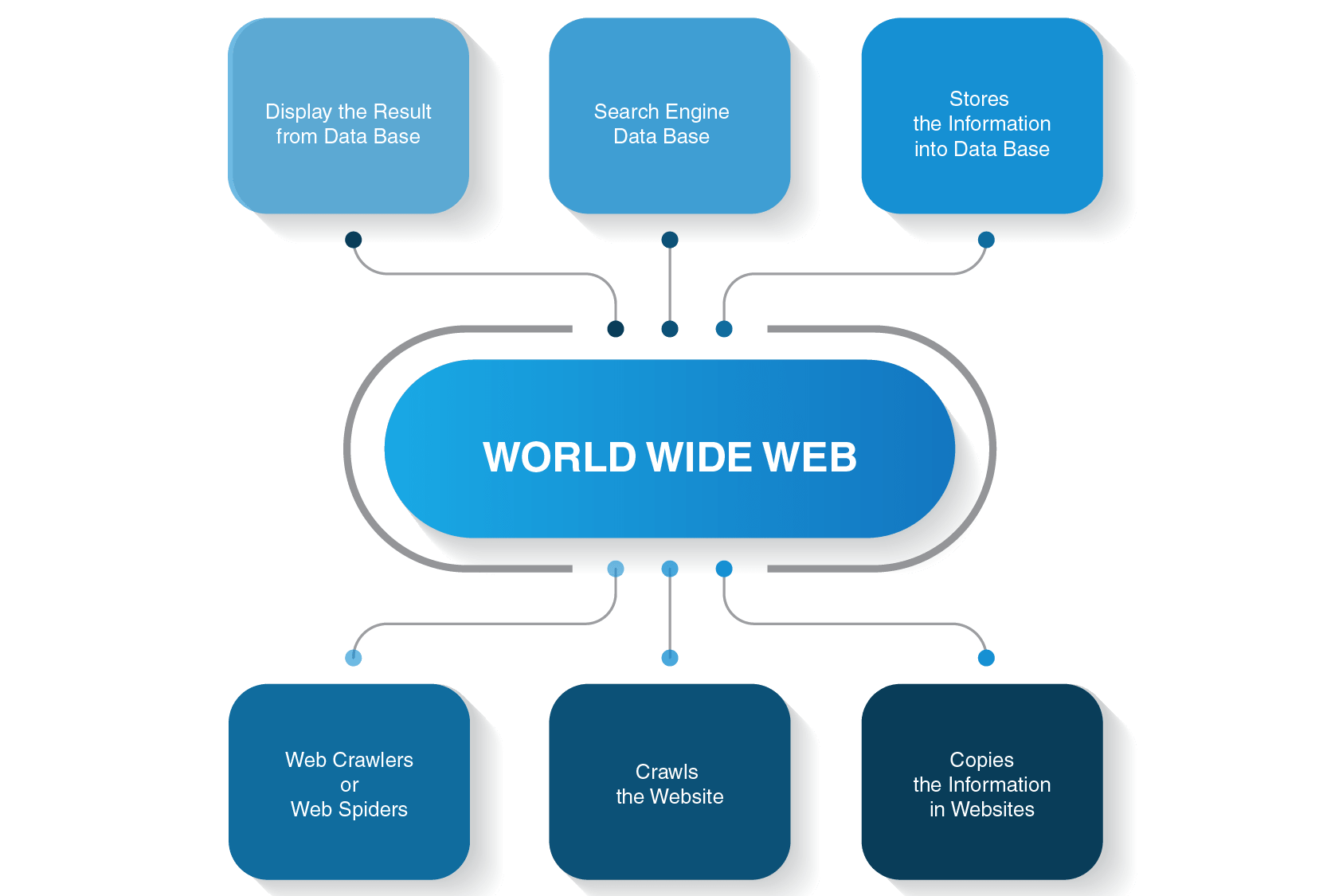
miten verkkohaku toimii?
ennen kuin syvennymme yksityiskohtiin siitä, miten telaketjurobotti toimii, katsotaan, miten koko hakuprosessi suoritetaan ennen kuin saat vastauksen hakukyselyysi.
esimerkiksi, jos kirjoitat ”mikä on maan ja kuun välinen etäisyys” ja painat enteriä, hakukone näyttää luettelon asiaankuuluvista sivuista. Yleensä, se vie kolme suurta vaihetta tarjota käyttäjille tarvittavat tiedot hakuihin:
- verkkohämähäkki ryömii sisältöä sivustoilla
- se rakentaa hakemiston hakukoneelle
- hakualgoritmit sijoittavat merkityksellisimmät sivut
lisäksi on pidettävä mielessä kaksi olennaista seikkaa:
- et tee hakuja reaaliaikaisesti, koska se on mahdotonta
World Wide Webissä on paljon verkkosivuja, ja monia muita luodaan jo nyt, kun luet tätä artikkelia. Siksi voi kestää ikuisuuden, ennen kuin hakukone keksii listan sivuista, joilla olisi merkitystä kyselysi kannalta. Hakuprosessin nopeuttamiseksi hakukone ryömii sivuja ennen niiden näyttämistä maailmalle.
- et tee hakuja World Wide Webissä
et todellakaan tee hakuja World Wide Webissä vaan hakuindeksissä ja tällöin web-ryömijä astuu taistelukentälle.
Ota Yhteyttä Nyt!
miten web Crawler toimii?
hakukoneita on monia-Google, Bing, Yahoo!, DuckDuckGo, Baidu, Yandex ja monet muut. Jokainen niistä käyttää hämähäkkibottiaan sivujen hakemiseen.
he aloittavat ryömintänsä suosituimmilta verkkosivuilta. Niiden ensisijainen tarkoitus web botit on välittää ydin siitä, mitä kunkin sivun sisältö on kyse. Niinpä verkkohämähäkit etsivät sanoja näiltä sivuilta ja rakentavat sitten käytännöllisen luettelon näistä sanoista, joita hakukone käyttää seuraavan kerran, kun haluat löytää tietoa kyselystäsi.
kaikki Internetin sivut on yhdistetty hyperlinkeillä, joten sivustohämähäkit voivat löytää nämä linkit ja seurata niitä seuraaville sivuille. Verkkobotit pysähtyvät vain, kun ne paikantavat kaiken sisällön ja yhdistetyt sivustot. Sitten he lähettävät tallennetulle tiedolle Hakuindeksin, joka tallennetaan palvelimille ympäri maailmaa. Koko prosessi muistuttaa tosielämän hämähäkinverkkoa, jossa kaikki kietoutuu toisiinsa.
indeksointi ei lopu heti, kun sivut on indeksoitu. Hakukoneet käyttävät ajoittain verkkohämähäkkejä nähdäkseen, onko sivuille tehty muutoksia. Jos muutos tapahtuu, hakukoneen Hakemisto päivitetään vastaavasti.
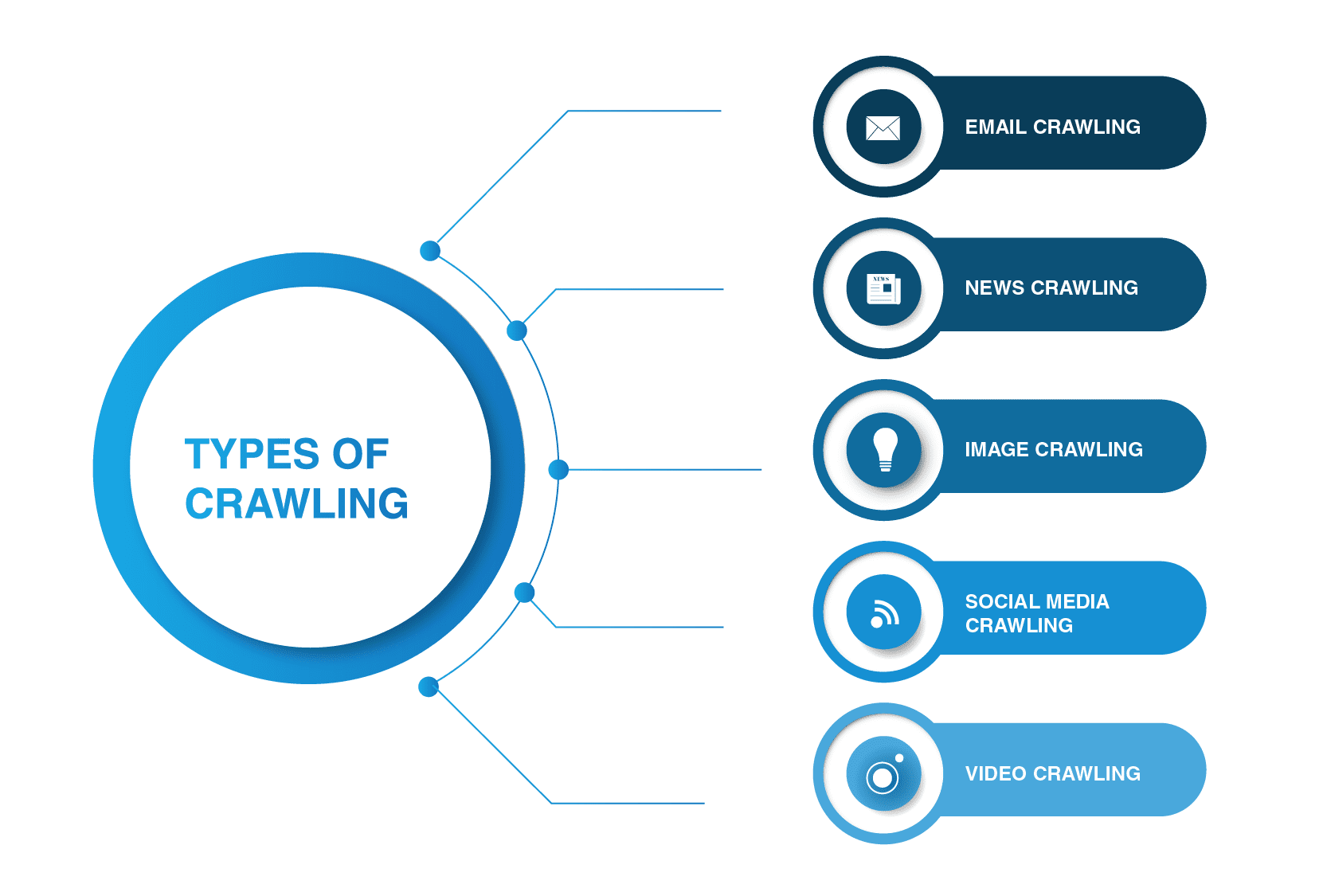
mitkä ovat tärkeimmät Web Crawler tyypit?
Verkkohämähäkit eivät rajoitu hakukonehämähäkkeihin. On olemassa muunlaisia web indeksointi siellä.
- Email crawling
Email crawling on erityisen hyödyllinen lähtevän lyijyn generoinnissa, koska tämän tyyppinen indeksointi auttaa poimimaan sähköpostiosoitteita. On syytä mainita, että tällainen ryömiminen on laitonta, koska se loukkaa henkilökohtaista yksityisyyttä eikä sitä voi käyttää ilman käyttäjän lupaa.
- uutisia ryömivä
internetin myötä uutisia eri puolilta maailmaa voi levitä verkossa nopeasti, ja tietojen poimiminen eri verkkosivuilta voi olla melko hallitsematonta.
on olemassa monia verkkohyökkääjiä, jotka selviävät tästä tehtävästä. Tällaiset telaketjut pystyvät hakemaan tietoja uudesta, vanhasta ja arkistoidusta uutissisällöstä ja lukemaan RSS-syötteitä. He poimivat seuraavat tiedot: Julkaisupäivä, tekijän nimi, otsikot, johdantokappaleet, pääteksti ja julkaisukieli.
- Image crawling
kuten nimikin kertoo, tällaista indeksointia käytetään kuviin. Internet on täynnä visuaalisia representaatioita. Niinpä tällaiset botit auttavat ihmisiä löytämään relevantteja kuvia lukuisista kuvista verkossa.
- sosiaalisen median ryömiminen
sosiaalisen median ryömiminen on varsin mielenkiintoinen asia, sillä kaikilla sosiaalisen median alustoilla ei saa ryömiä. Kannattaa myös muistaa, että tällainen indeksointi voi olla laitonta, jos se rikkoo tietosuojan noudattamista. Silti, on olemassa monia sosiaalisen median alustan tarjoajia, jotka ovat hyvin indeksointi. Esimerkiksi Pinterest ja Twitter sallivat hämähäkkibottien skannata sivunsa, jos ne eivät ole käyttäjäherkkiä eivätkä paljasta mitään henkilökohtaisia tietoja. Facebook, LinkedIn ovat tiukkoja tämän asian suhteen.
- videon ryömiminen
joskus on paljon helpompaa katsoa videota kuin lukea paljon sisältöä. Jos päätät upottaa Youtube, Soundcloud, Vimeo, tai muuta videosisältöä sivustoosi, se voidaan indeksoida joidenkin web-indeksoijat.
mitkä ovat esimerkkejä Web Crawlereista?
monet hakukoneet käyttävät omia hakurobotteja. Esimerkiksi yleisimmät verkkohyökkääjät esimerkit ovat:
- Alexabot
Amazon web crawler Alexabotia käytetään verkkosisällön tunnistamiseen ja käänteisen linkin löytämiseen. Jos haluat pitää joitakin tietoja yksityisiä, voit sulkea Alexabot indeksointi sivuston.
- Yahoo! Slurp Bot
Yahoo crawler Yahoo! Slurp Bot käytetään indeksointiin ja kaavinta web-sivuja parantaa henkilökohtaista sisältöä käyttäjille.
- Bingbot
Bingbot on yksi suosituimmista Microsoftin ylläpitämistä verkkohämähäkeistä. Se auttaa hakukonetta, Bing, luomaan käyttäjilleen merkityksellisimmän indeksin.
- DuckDuck Bot
DuckDuckGo lienee yksi suosituimmista hakukoneista, joka ei seuraa historiaasi ja seuraa sinua millä tahansa sivustoilla. Sen DuckDuck Bot web crawler auttaa löytämään tärkeimmät ja parhaat tulokset, jotka täyttävät käyttäjän tarpeet.
- Facebook ulkoinen hitti
Facebookilla on myös telaketjunsa. Esimerkiksi kun Facebook-käyttäjä haluaa jakaa linkin ulkopuoliselle sisältösivulle toisen henkilön kanssa, ryömijä raaputtaa sivun HTML-koodin ja antaa molemmille otsikon, videon tai kuvien sisällön.
- baiduspider
tätä telaketjua ylläpitää hallitseva Kiinalainen hakukone − Baidu. Kuten mikä tahansa muu botti, se kulkee erilaisten verkkosivujen läpi ja etsii hyperlinkkejä indeksoimaan sisältöä moottorille.
- Exabot
ranskalainen hakukone Exalead käyttää exabotia sisällön indeksointiin, jotta se voitaisiin sisällyttää Moottorin indeksiin.
- Yandex Bot
tämä botti kuuluu Venäjän suurimpaan hakukoneeseen Yandexiin. Voit estää sen indeksoimasta sisältöä, Jos et aio harjoittaa liiketoimintaa siellä.
mikä on Googlebotti?
kuten edellä todettiin, lähes kaikilla hakukoneilla on hämähäkkibotit, eikä Google ole poikkeus. Googlebot on maailman suosituimman hakukoneen käyttämä google crawler, jota käytetään tämän moottorin sisällön indeksointiin.
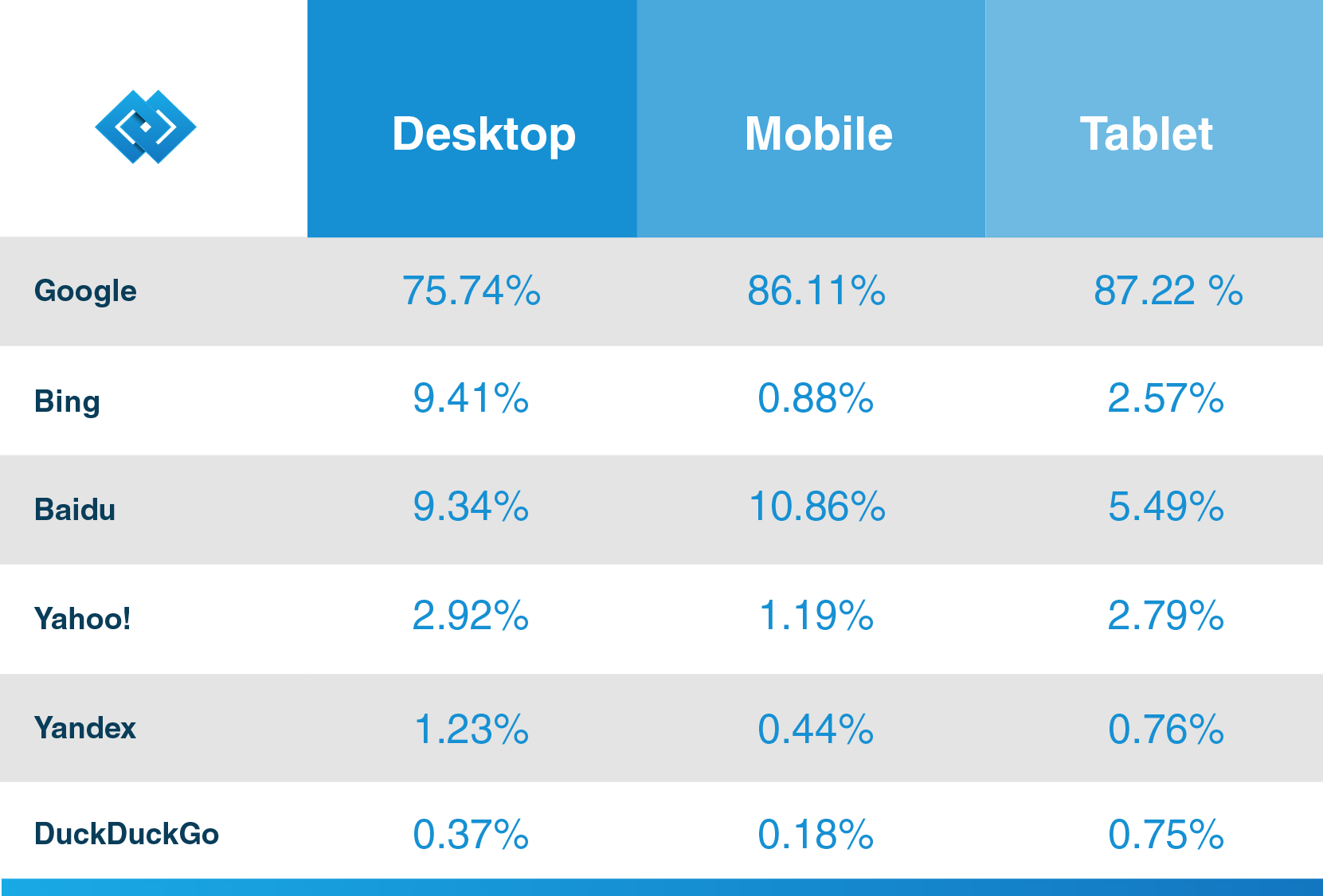
kuten maineikas CRM-myyjä Hubspot toteaa blogissaan, Googlella on yli 92,42 prosentin osuus hakumarkkinoista ja sen mobiililiikenteessä yli 86 prosenttia. Niin, jos haluat tehdä kaiken irti hakukoneen yrityksesi, selvittää lisätietoja sen web hämähäkki, jotta tulevat asiakkaat voivat löytää sisältöä kiitos Google.
Googlebot voi olla kahdenlaisia: työpöytäbotti ja mobiilisovellusten telaketjut, jotka simuloivat käyttäjää näillä laitteilla. Se käyttää samaa indeksointiperiaatetta kuin mikä tahansa muu verkkohämähäkki, kuten linkkien seuraamista ja verkkosivujen sisällön skannaamista. Prosessi on myös täysin automatisoitu ja voi olla toistuva, eli se voi käydä samalla sivulla useita kertoja ei-säännöllisin väliajoin.
jos olet valmis julkaisemaan sisältöä, kestää päiviä ennen kuin Google crawler indeksoi sen. Jos olet verkkosivuston omistaja, voit manuaalisesti nopeuttaa prosessia lähettämällä Indeksointipyynnön Fetch as Google-palvelun kautta tai päivittämällä verkkosivustosi sivukarttaa.
voit käyttää myös robotteja.txt (tai Robots Exclusion Protocol) ”ohjeiden antamiseen” hämähäkkibotille, mukaan lukien Googlebot. Siellä voit sallia tai kieltää crawlers vierailla tiettyjä sivuja sivustosi. Muista kuitenkin, että kolmannet osapuolet voivat helposti käyttää tätä tiedostoa. He näkevät, mitä sivuston osia rajoitit indeksoimasta.
Web Crawler vs Web Scraper-mikä on ero?
monet ihmiset käyttävät web-telaketjuja ja web-kaapimia keskenään. Näiden kahden välillä on kuitenkin olennainen ero. Jos edellinen käsittelee enimmäkseen sisällön metatietoja, kuten tägejä, otsikoita, avainsanoja ja muita asioita, jälkimmäinen ”varastaa” sisältöä verkkosivustolta, joka on lähetetty jonkun muun Online-resurssiin.
web-kaavin myös ”metsästää” tiettyjä tietoja. Esimerkiksi, jos sinun täytyy poimia tietoja verkkosivuilla, jossa on tietoa, kuten osakemarkkinoiden trendit, Bitcoin hinnat, tai mikä tahansa muu, voit hakea tietoja näiltä verkkosivustoilta käyttämällä web scraping bot.
jos indeksoit sivustosi ja haluat lähettää sisältösi indeksoitavaksi tai haluat muiden ihmisten löytävän sen — se on täysin laillista, muuten toisten ihmisten ja yritysten verkkosivujen kaavinta on lain vastaista.
Custom Web Crawler-Mikä Se On?
custom web crawler on botti, jota käytetään tietyn tarpeen kattamiseen. Voit rakentaa hämähäkkibotti kattamaan kaikki tehtävät, jotka on ratkaistava. Esimerkiksi, jos olet yrittäjä tai markkinoija tai muu ammattilainen, joka käsittelee sisältöä, voit helpottaa asiakkaiden ja käyttäjien löytää haluamansa tiedot sivustossasi. Voit luoda erilaisia web-botteja eri tarkoituksiin.
jos sinulla ei ole käytännön kokemusta mukautetun Web-telaketjusi rakentamisesta, voit aina ottaa yhteyttä ohjelmistokehityspalvelun tarjoajaan, joka voi auttaa sinua siinä.
paketointi
verkkosivujen ryömijät ovat olennainen osa kaikkia suuria hakukoneita, joita käytetään sisällön indeksointiin ja löytämiseen. Monilla hakukoneyhtiöillä on bottinsa, esimerkiksi Googlebotin voimanlähteenä toimii yritysjätti Google. Sen lisäksi, että, on olemassa useita erilaisia indeksointi, joita käytetään kattamaan erityistarpeita, kuten video, kuva, tai sosiaalisen median indeksointi.
ottaen huomioon, mitä hämähäkkibotit voivat tehdä, ne ovat erittäin tärkeitä ja hyödyllisiä yrityksellesi, koska web-indeksoijat paljastavat sinut ja yrityksesi maailmalle ja voivat tuoda uusia käyttäjiä ja asiakkaita.
jos haluat luoda mukautetun web crawlerin, ota yhteyttä litslinkiin, kokeneeseen web-kehityspalvelujen tarjoajaan, saadaksesi lisätietoja.